数据序列化工具Protobuf编码&避坑指南
我们现在所有的协议、配置、数据库的表达都是以 protobuf 来进行承载的,所以我想深入总结一下 protobuf 这个协议,以免踩坑。
作者:bear
先简单介绍一下 Protocol Buffers(protobuf),它是 Google 开发的一种数据序列化协议(与 XML、JSON 类似)。它具有很多优点,但也有一些需要注意的缺点:
优点:
- 效率高:Protobuf 以二进制格式存储数据,比如 XML 和 JSON 等文本格式更紧凑,也更快。序列化和反序列化的速度也很快。
- 跨语言支持:Protobuf 支持多种编程语言,包括 C++、Java、Python 等。
- 清晰的结构定义:使用 protobuf,可以清晰地定义数据的结构,这有助于维护和理解。
- 向后兼容性:你可以添加或者删除字段,而不会破坏老的应用程序。这对于长期的项目来说是非常有价值的。
缺点:
- 不直观:由于 protobuf 是二进制格式,人不能直接阅读和修改它。这对于调试和测试来说可能会有些困难。
- 缺乏一些数据类型:例如没有内建的日期、时间类型,对于这些类型的数据,需要手动转换成可以支持的类型,如 string 或 int。
- 需要额外的编译步骤:你需要先定义数据结构,然后使用 protobuf 的编译器将其编译成目标语言的代码,这是一个额外的步骤,可能会影响开发流程。
总的来说,Protobuf 是一个强大而高效的数据序列化工具,我们一方面看重它的性能以及兼容性,除此之外就是它强制要求清晰的定义出来,以文件的形式呈现出来方便我们维护管理。下面我们主要看它的编码原理,以及在使用上有什么需要注意的地方。
编码原理
概述
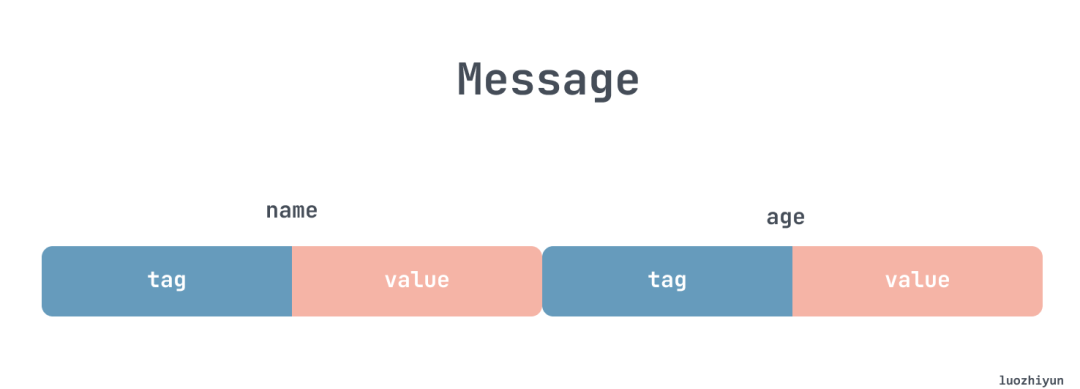
对于 protobuf 它的编码是很紧凑的,我们先看一下 message 的结构,举一个简单的例子:
message Student {
string name = 1;
int32 age = 2;
}message 是一系列键值对,编码过之后实际上只有 tag 序列号和对应的值,这一点相比我们熟悉的 json 很不一样,所以对于 protobuf 来说没有 .proto 文件是无法解出来的:
对于 tag 来说,它保存了 message 字段的编号以及类型信息,我们可以做个实验,把 name 这个 tag 编码后的二进制打印出来:
func main() {
student := student.Student{}
student.Name = "t"
marshal, _ := proto.Marshal(&student)
fmt.Println(fmt.Sprintf("%08b", marshal)) // 00001010 00000001 01110100
}打印出来的结果是这样:
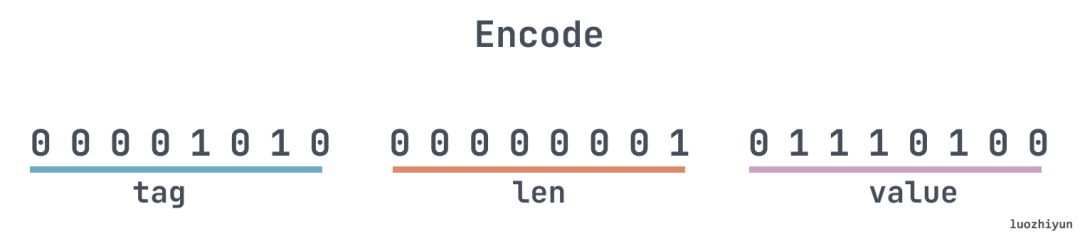
上图中,由于 name 是 string 类型,所以第一个 byte 是 tag,第二 byte 是 string 的长度,第三个 byte 是值,也就是我们上面设置的 “t”。我们下面先看看 tag:
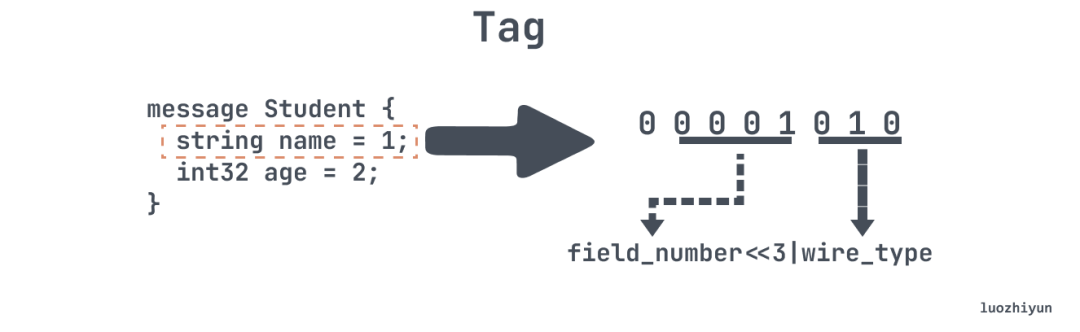
tag 里面会包含两部分信息:字段序号,字段类型,计算方式就是上图的公式。上图中将 name 这个字段序列化成二进制我们可以看到,第一个 bit 是标记位,表示是否字段结尾,这里是 0 表示 tag 已结尾,tag 占用 1byte;接下来 4 个 bit 表示的是字段序号,所以范围 1 到 15 中的字段编号只需要 1 bit 进行编码,我们可以做个实验看看,将 tag 改成 16:
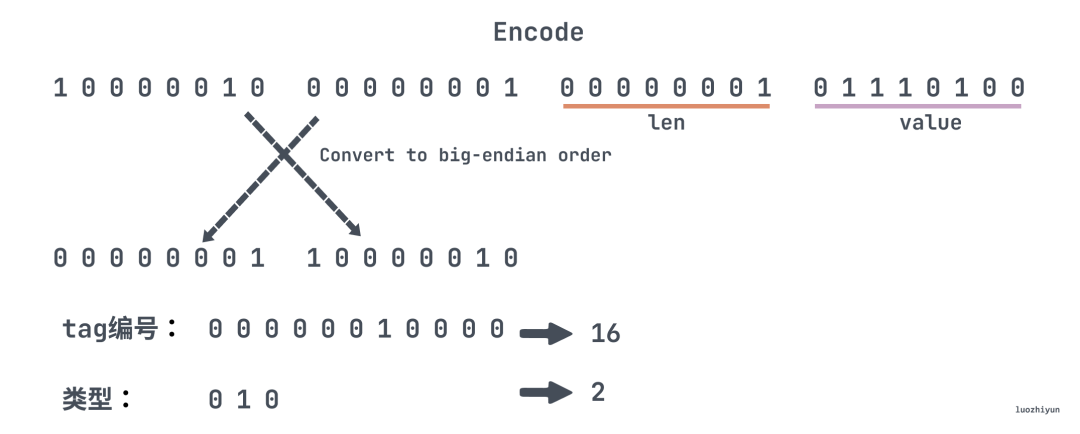
pb4由上图所示,每个 byte 第一个 bit 表示是否结束,0 表示结束,所以上面 tag 用两个 byte 表示,并且 protobuf 是小端编码的,需要转成大端方便阅读,所以我们可以知道 tag 去掉每个 byte 第一个 bit 之后,后三位表示类型,是 3,其余位是编号表示 16。
所以从上面编码规则我们也可以知道,字段尽可能精简一些,字段尽量不要超过 16 个,这样就可以用一个 byte 表示了。
同时我们也可以知道,protobuf 序列化是不带字段名的,所以如果客户端的 proto 文件只修改了字段名,请求服务端是安全的,服务端继续用根据序列编号还是解出来原来的字段。但是需要注意的是不要修改字段类型。
接下来我们看看类型,protobuf 共定义了 6 种类型,其中两种是废弃的:
IDNameUsed For0VARINTint32, int64, uint32, uint64, sint32, sint64, bool, enum1I64fixed64, sfixed64, double2LENstring, bytes, embedded messages, packed repeated fields3SGROUPgroup start (deprecated)4EGROUPgroup end (deprecated)5I32fixed32, sfixed32, float上面的例子中,Name 是 string 类型所以上面 tag 类型解出来是 010 ,也就是 2。
Varints 编码
对于 protobuf 来说对数字类型做了压缩的,普通情况下一个 int32 类型需要 4 byte,而 protobuf 表示 127 以内的数字只需要 2 byte。因为对于一个普通 int32 类型数字,如果数字很小,那么实际上有效位很少,比如要表示 1 这个数字,二进制可能是这样:
00000000 00000000 00000000 00000001前 3 个字节都是 0 没有表示任何信息,protobuf 就是将这些 0 都去除了,用 1 byte 表示 1 这个数字,再用 1 byte 表示 tag 的编号和类型,所以占用了 2byte。
比如我们对上面 student 设置 age 等于 150:
func main() {
student := student.Student{}
student.Age = 150
marshal, _ := proto.Marshal(&student)
fmt.Println(fmt.Sprintf("%08b", marshal)) //00010000 10010110 00000001
fmt.Println(fmt.Sprintf("%08b", "a"))
}上面打印出来的二进制如下,因为 150 超过 127,所以需要用两个 byte 表示:
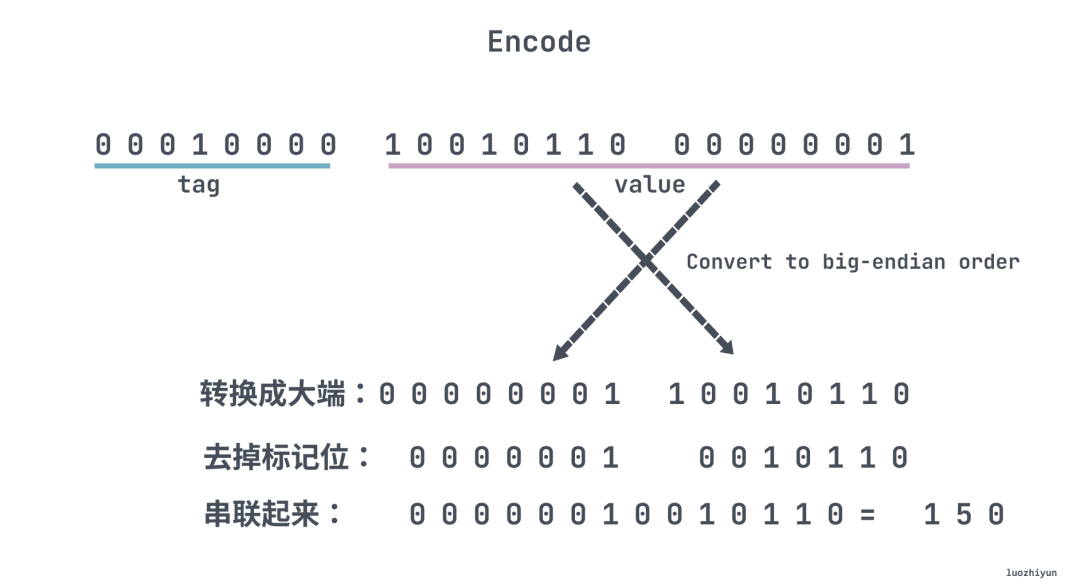
第一个 byte 是 tag 这里就不再重复介绍了。后面两个 byte 是真实的值,每个 byte 的最高位 bit 是标记位,表示是否结束。然后我们转换成大端表示,串联起来就可以得到它的值是 150。
ZigZag 编码
Varints 编码之所以可缩短数字所占的存储字节数是因为去掉了 0 ,但是对于负数来说就不行了,因为负数的符号位为 1,并且对于 32 位的有符号数都会转换成 64 位无符号来处理,例如 -1,用 Varints 编码之后的二进制:
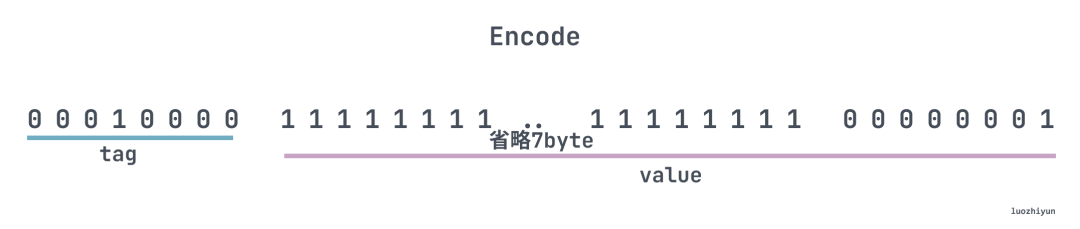
所以 Varints 编码负数总共会恒定占用 11 byte,tag 一个 byte,值占用 10 byte。
为此 Google Protocol Buffer 定义了 sint32 这种类型,采用 zigzag 编码。将所有整数映射成无符号整数,然后再采用 varint 编码方式编码。例如:
Signed OriginalEncoded As00-1112-23……0x7fffffff0xfffffffe-0x800000000xffffffff参照上面的表,也就是将 -1 编码成 1,将 1 编码成 2,全部都做映射,实际的 Zigzag 映射函数为:
(n << 1) ^ (n >> 31) //for 32 bit
(n << 1) ^ (n >> 63) //for 64 bit对于使用来说,只是编码方式变了,使用是不受影响,所以对于如果有很高比例负数的数据,可以尝试使用 sint 类型,节省一些空间。
embedded messages & repeated
比如现在定义这样的 proto:
message Lecture {
int32 price =1 ;
}
message Student {
repeated int32 scores = 1;
Lecture lecture = 2;
}给 scores 取值为 [1,2,3],编码之后发现其实和上面讲的 string 类型很像。第一个 byte 是 tag;第二 byte 是 len,长度为 3;后面三个 byte 都是值,我们设定的 1,2,3。

再来看看 embedded messages 类型,让 Lecture 的 price 设置为 150 好了,编码之后是这样:

其实结构也很简单,左边的是 Student 类型,右边是 Lecture 类型。有点不同的是对于 embedded messages 会将大小计算出来。
最佳实践
字段编号
需要注意的是范围 1 到 15 中的字段编号需要一个字节进行编码,包括字段编号和字段类型;范围 16 至 2047 中的字段编号需要两个字节。所以你应该保留数字 1 到 15 作为非常频繁出现的消息元素。
因为使用了 VarInts,所以单字节的最高位是零,而最低三位表示类型,所以只剩下 4 位可用了。也就是说,当你的字段数量超过 16 时,就需要用两个以上的字节表示了。
保留字段
一般的情况下,我们是不会轻易的删除字段的,防止客户端和服务端出现协议不一致的情况,如果您通过完全删除某个字段或将其注释掉来更新消息类型,那么未来的其他人不知道这个 tag 或字段被删除过了,我们可以使用 reserved 来标记被删除的字段,如:
message Foo {
reserved 2, 15, 9 to 11;
reserved "foo", "bar";
}当然除了 message ,reserved 也可以在枚举类型中使用。
不要修改字段 tag 编号以及字段类型
protobuf 序列化是不带字段名的,所以如果客户端的 proto 文件只修改了字段名,请求服务端是安全的,服务端继续用根据序列编号还是解出来原来的字段,但是需要注意的是不要修改字段类型,以及序列编号,修改了之后就可能按照编号找错类型。
不要使用 required 关键字
required 意味着消息中必须包含这个字段,并且字段的值必须被设置。如果在序列化或者反序列化的过程中,该字段没有被设置,那么 protobuf 库就会抛出一个错误。
如果你在初期定义了一个 required 字段,但是在后来的版本中你想要删除它,那么这就会造成问题,因为旧的代码会期待该字段始终存在。为了确保兼容性,Google 在最新版本的 protobuf(protobuf 3)中已经不再支持 required 修饰符。
尽量使用小整数
Varints 编码表示 127 以内的数字只需要 2 byte,1 byte 是 tag,1 byte 是值,压缩效果很好。但是如果表示一个很大的数如 :1<<31 - 1,除去 tag 外需要占用 5 byte,比普通的 int 32 多 1 byte,因为 protobuf 每个 byte 最高位有一个标识符占用 1 bit。
如果需要传输负数,可以试试 sint32 或 sint64
因为负数的符号位为 1,并且 Varints 编码对于负数如果是 32 位的有符号数都会转换成 64 位无符号来处理,所以 Varints 编码负数总共会恒定占用 11 byte,tag 一个 byte,值占用 10 byte。
而 sint32 和 sint64 将所有整数映射成无符号整数,然后再采用 varint 编码方式编码,如果数字比较还是可以节省一定的空间的。
Reference
- https://sunyunqiang.com/blog/protobuf_encode/
- https://halfrost.com/protobuf_encode/
- https://protobuf.dev/programming-guides/encoding/
- https://protobuf.dev/programming-guides/dos-donts/