关于前后端JSON解析差异问题与思考

本文主要总结了作者在一次涉及流程表单的需求发布中遇到的问题及思考总结。
一、问题回顾
在一次涉及流程表单的需求发布时,由于表单设计的改动,需要在历史工单中的一个json字段增加一个属性,效果示意如下:
[{"key1":"value1"}] -> [{"key1":"value1", "key2":"value2"}]由于历史数据较多,采用了通过odc从数据库查询数据,线下开发数据处理脚本,更新数据后生成sql去线上执行,脚本示例如下。
String target = JSON.toJSONString(
JSON.parseObject(oraData).put("key2","value2")
)在数据变更时未发现问题,存量工单抽查显示正常。但在第二天有业务反馈,有部分工单出现前端异常导致无法展示的问题。根据经验分析,这类问题一般是前端在处理数据时出现异常导致,考虑到昨天对工单中的一个json字段进行了变更,初步推断应该是该字段变更后影响了前段解析。为了验证猜测,将前端查询的接口返回数据,拷贝到在线解析json的网站中进行解析测试。结果发现页面解析失败,观察发现json中包含回车,回车删除后解析正常。在dev验证删除后数据解析正常后,应急对线上异常工单进行了处理。
二、问题思考
2.1 JavaScript如何解析json字符串
首先在Chrome控制台做一个简单的json解析实验,过程如下:
var str = "{\"key\":\"v1\\nv2\"}"
console.log(str)
// 打印结果 {"key":"v1\nv2"}
console.log(JSON.parse(str))
// 打印结果 {key: 'v1\nv2'}
console.log(JSON.parse(str).key)
// 打印结果 v1
// v2经过测试,可以得到以下结论:
1)JavaScript在加载字符串时,会自动识别 斜杠 并进行反转义;
2)在进行json解析,会对值对应的字符串进行二次反转义,将\n解析为回车字符。在查阅JSON官方对parse工具的流程说明后,印证了上述测试。
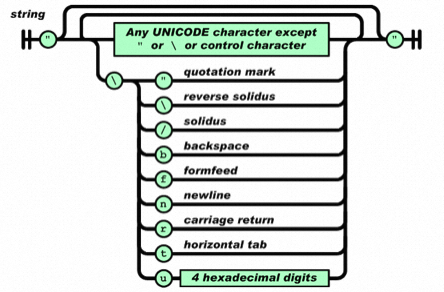
但在处理过程中,我们看到解释器的允许通过范围,有说明不包含control character。常见的回车、换行等字符都属于control character。
所以可以推测,在JavaScript解析json时,如果遇到control character,可能会引起异常情况。
为了验证猜想做了以下对比实验。
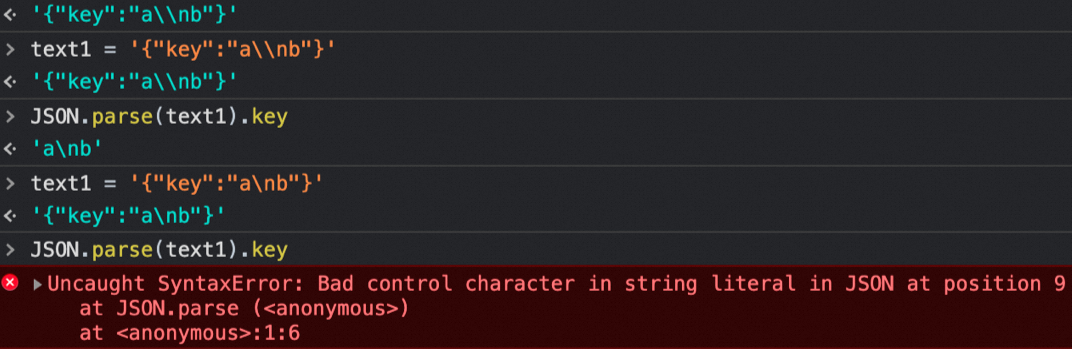
经过测试可以发现,在JavaScript使用的JSON解析器sdk中,会对于字符串中的control character进行校验,如遇到则会直接抛出异常。由于JavaScript在加载字符串时会先做一次字符转义,会将”\n“转换为回车字符,即 (byte) 13,使得解析JSON时提示异常。
这里会出现一个新的疑问,字符转义这个问题看起来是会经常出现的,为什么到现在才碰到一次呢。这里继续对JavaScript的JSON编码器进行测试。

经过测试可以发现,JavaScript在对字符串进行JSON编码时,会自动对字符串中的斜杠进行编码,正好对应了在JSON解码时对字符串自动解码。到这里可以明白了,同时仅使用JavaScript的JSON编码器和解码器,会自动对control character进行转义和反转义处理,不会出现异常。那在Java中呢?
2.2 Java如何解析json字符串
在java中,常用的JSON处理SDK是fastjson,此处以fastjson进行测试。
为了搞清楚在java中fastjson会如何解析json字符串中的control character,进行了以下实验:
Map<String, String> testMap = new HashMap<>();
testMap.put("key", "v1\nv2");
System.out.println("1 >> " + JSON.toJSONString(testMap));
String testStr1 = "{\"key\":\"v1\nv2\"}";
System.out.println("2 >> " + testStr1);
System.out.println("3 >> " + JSON.parseObject(testStr1).getString("key"));
String testStr2 = "{\"key\":\"v1\\nv2\"}";
System.out.println("4 >> " + testStr2);
System.out.println("5 >> " + JSON.parseObject(testStr2).getString("key"));打印结果如下:
1 >> {"key":"v1\nv2"}
2 >> {"key":"v1
v2"}
3 >> v1
v2
4 >> {"key":"v1\nv2"}
5 >> v1
v2经过测试,我们可以得出以下结论:1)java的fastjson在进行json解析前,加载字符串时也会进行反转义处理,对于\n等control character也会转义为对应的byte值;2)java的fastjson在对json中的字符串进行解码时,会将字符串中的转义最进行反转义处理;3)java的fastjson在对json中的字符串进行解码时,不会受到字符串中control character的影响,可以正常提取值。
为了验证上面的推论,这里截取了fastjson关于解析String字符串的部分源码。
public final void scanString() {
np = bp;
hasSpecial = false;
char ch;
for (;;) {
ch = next();
if (ch == '\"') {
break;
}
if (ch == EOI) {
if (!isEOF()) {
putChar((char) EOI);
continue;
}
throw new JSONException("unclosed string : " + ch);
}
if (ch == '\\') {
if (!hasSpecial) {
hasSpecial = true;
if (sp >= sbuf.length) {
int newCapcity = sbuf.length * 2;
if (sp > newCapcity) {
newCapcity = sp;
}
char[] newsbuf = new char[newCapcity];
System.arraycopy(sbuf, 0, newsbuf, 0, sbuf.length);
sbuf = newsbuf;
}
copyTo(np + 1, sp, sbuf);
// text.getChars(np + 1, np + 1 + sp, sbuf, 0);
// System.arraycopy(buf, np + 1, sbuf, 0, sp);
}
ch = next();
switch (ch) {
case '0':
putChar('\0');
break;
case '1':
putChar('\1');
break;
case '2':
putChar('\2');
break;
case '3':
putChar('\3');
break;
case '4':
putChar('\4');
break;
case '5':
putChar('\5');
break;
case '6':
putChar('\6');
break;
case '7':
putChar('\7');
break;
case 'b': // 8
putChar('\b');
break;
case 't': // 9
putChar('\t');
break;
case 'n': // 10
putChar('\n');
break;
case 'v': // 11
putChar('\u000B');
break;
case 'f': // 12
case 'F':
putChar('\f');
break;
case 'r': // 13
putChar('\r');
break;
case '"': // 34
putChar('"');
break;
case '\'': // 39
putChar('\'');
break;
case '/': // 47
putChar('/');
break;
case '\\': // 92
putChar('\\');
break;
case 'x':
char x1 = next();
char x2 = next();
boolean hex1 = (x1 >= '0' && x1 <= '9')
|| (x1 >= 'a' && x1 <= 'f')
|| (x1 >= 'A' && x1 <= 'F');
boolean hex2 = (x2 >= '0' && x2 <= '9')
|| (x2 >= 'a' && x2 <= 'f')
|| (x2 >= 'A' && x2 <= 'F');
if (!hex1 || !hex2) {
throw new JSONException("invalid escape character \\x" + x1 + x2);
}
char x_char = (char) (digits[x1] * 16 + digits[x2]);
putChar(x_char);
break;
case 'u':
char u1 = next();
char u2 = next();
char u3 = next();
char u4 = next(); int val = Integer.parseInt(new String(new char[] { u1, u2, u3, u4 }), 16);
putChar((char) val);
break;
default:
this.ch = ch;
throw new JSONException("unclosed string : " + ch);
}
continue;
}
if (!hasSpecial) {
sp++;
continue;
}
if (sp == sbuf.length) {
putChar(ch);
} else {
sbuf[sp++] = ch;
}
}
token = JSONToken.LITERAL_STRING;
this.ch = next();
}阅读源码后,我们可以验证我们的猜想,得出以下结论:1)fastjson在解析字符串时,会自动将遇到的转义字符进行反转义;2)对于不需要特殊处理的字符,直接存入数据,继续处理下一字符。
2.3 Java和JavaScript交互如何出现JSON解析问题
经过上面对fastjson和JavaScript在JSON处理的区别,可以清晰的看出来本次问题是如何出现的。
起初在JavaScript进行JSON编码和解码时,会在编码时额外对\n等control character进行一次反转义。结果是在JavaScript对json字符串解码时,可以经过两次反转义再得到control character,不会触发校验引起意外情况。
原始数据:[{"key1","v1\\nv2"}]但是在需要追加数据时,由于数据加工处理是使用java脚本进行处理的,因此出现了编码差异。fastjson在解析JSON数据时,自动将\n等转义字符进行反转义,解析为control character。但是在加工处理后,将JSON数据编码为json字符串时,仅仅对control character进行了一次处理,还原为 \n 形式。
更新后数据:[{"key1","v1\nv2"},{"key2","value2"}]更新到数据库后,在前端查询解析时,由于在字符串加载时自动反转义出了control character,就会出现由于字符无法识别解码错误的问题。
针对该问题,后续如果还有类似需求进行处理,需要编码得到数据后,对json字符串中的所有 \ 再次进行一次反转义,使得数据可以通过两次反转义再得到实际期望字符,即可解决该问题。
期望正确数据:[{"key1","v1\\nv2"},{"key2","value2"}]三、经验总结
1)在需要进行数据处理的时候,尽量保持只有一方对数据进行加工和解析。如果具备条件则数据的编码、解码全部由后端处理;或者由于需求影响,全部由前端进行编码、解码,对于多个合作方使用了未知SKD编解码数据的场景也可以复用相同的原则,可以很大程度上避免该类问题发生。
2)在开发过程中,对于数据处理类sdk的升级、替换等操作需要慎之又慎。不同sdk的数据处理方式可能存在很多细小的差别,简单替换容易为日后出现事故埋下隐患。在进行升级、替换前一定要要针对与各类可能出现的数据情况进行充分验证。