Elasticsearch核心应用场景-日志优化实践
1. 背景
日志领域是Elasticsearch(ES)最重要也是规模最大的应用场景之一。这得益于 ES 有高性能倒排索引、灵活的 schema、易用的分布式架构,支持高吞吐写入、高性能查询,同时有强大的数据治理生态、端到端的完整解决方案。但原生 ES 在高吞吐写入、低成本存储、高性能查询等方面还有非常大的优化空间,本文重点剖析腾讯云大数据 ES 团队在这三个方面的内核增强优化。
2. 日志领域的挑战
我们先来看看日志领域的挑战有哪些。
首先从日志本身的数据特点来看,主要以半结构化、非结构化为主,传统的数据库方案没法很好的解决解析、存储等问题。ES 支持 JSON 且支持动态映射,高版本还支持 Runtime Feilds,能在查询时动态提取字段,天然支持了日志场景复杂、灵活的数据结构。
日志数据进入 ES 则面临高并发、高吞吐的写入性能挑战。内核层面我们进行了定向路由、物理复制等重磅优化,有效解决日志入口吞吐瓶颈,提升写入性能一倍+。
日志数据的存储是另一大挑战,日志往往是海量的且往往价值不高,存储成本成为用户最顾虑的痛点之一。腾讯云 ES 一方面通过压缩编码优化来降低单位文档存储成本,另一方面我们通过基于云原生环境自研混合存储方案,实现存储与计算分离,降低存储成本 50% 以上。
日志数据的出口,查询性能也是一大挑战,海量数据场景下,大查询对资源的开销非常高,带来的查询延时也非常明显。ES 原生支持了倒排索引,点查过滤的性能非常好,但无法满足日志场景大范围查询、聚合分析等性能需求。对此,腾讯云 ES 进行了查询裁剪、查询并行化等一系列系统性优化,提升查询性能数十倍。
下面是日志领域的挑战总结,后面将针对高吞吐写入、低成本存储、高性能查询层面的优化进行详细分析。

3. 高吞吐写入
3.1 定向路由
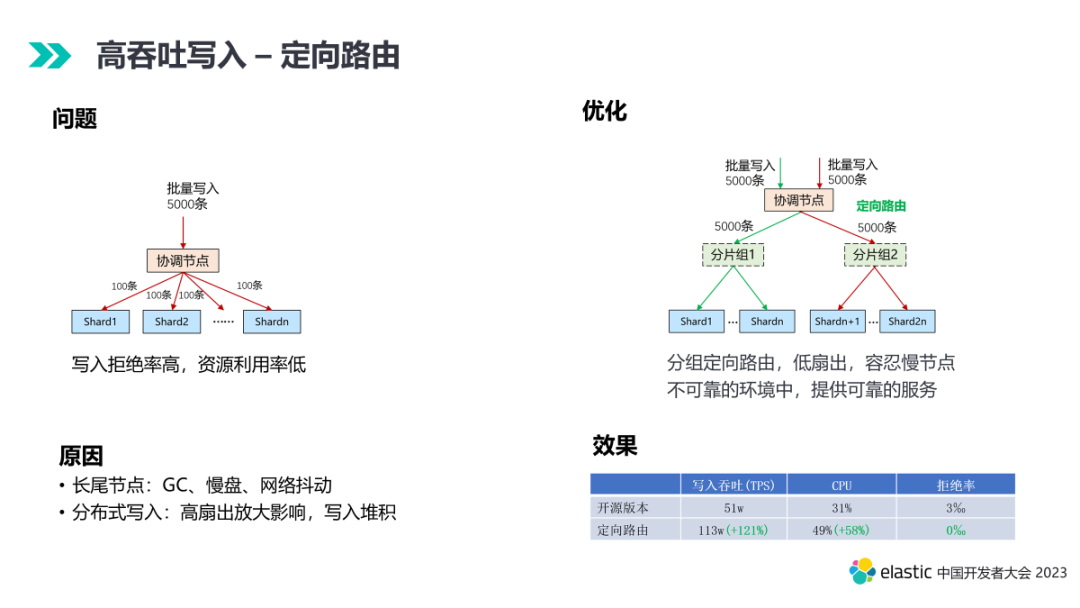
腾讯云 ES 内核通过引入写入定向路由优化,将用户的一个 Bulk 请求路由到一个分片数可控的分片组,降低写入请求扇出影响,容忍慢节点,在不可靠的环境中提供可靠的服务。基于定向路由优化,某日志业务场景,写入吞吐提升一倍多,CPU 资源利用率提升 58%,拒绝率从 3% 降至 0。
定向路由解决了慢节点对写入的影响,接下来我们看看如何优化写入层面冗余的计算开销来提升性能。
3.2 物理复制
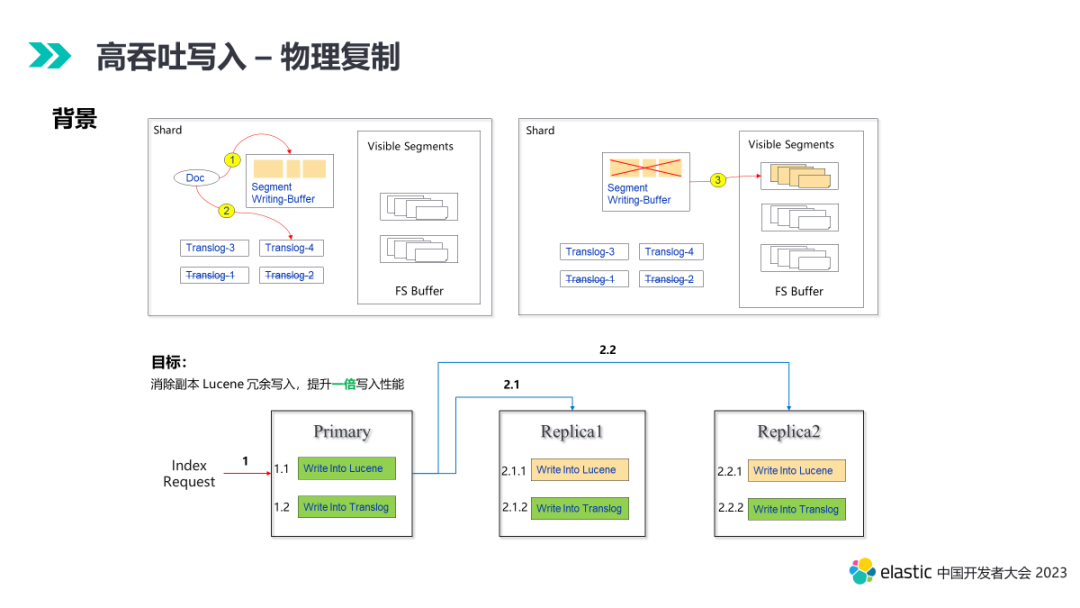
- 数据在内存中构建各种数据类型,包括行存、列存、各种索引。
- 写入 Translog,相当于 WAL 确保数据可靠性,机器挂掉数据可重放。
- 周期性 refresh 将内存中的数据结构 buffer 构建成完整的 segment 并打开 reader 可查。
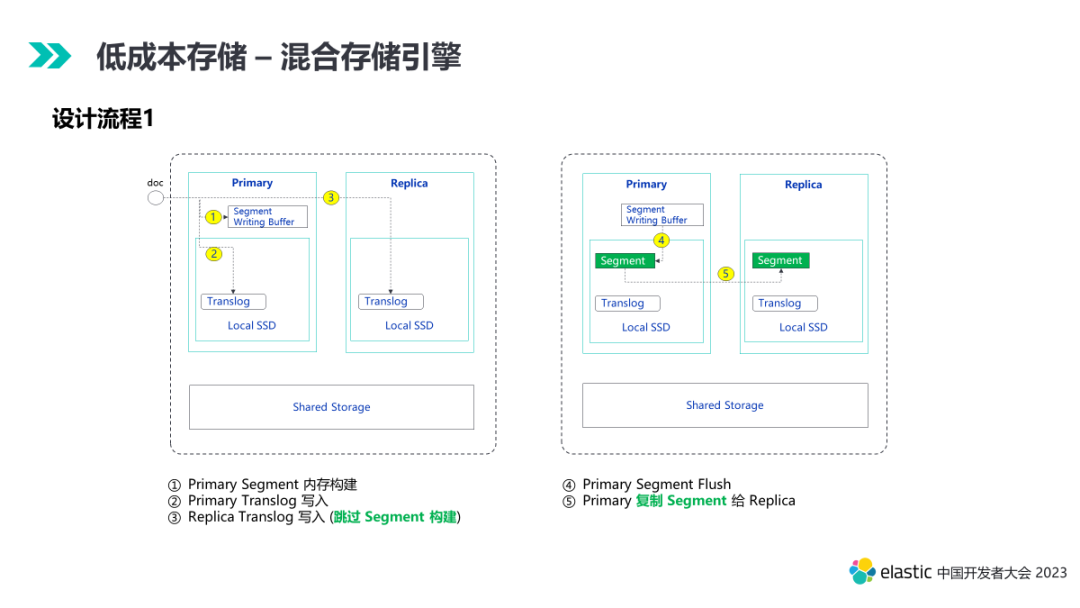
ES 分布式层的写入,数据先从协调节点转发至 Primary,主分片写完 Lucene 和 Translog 之后并行转发给多个 Replica,副本分片完成 Lucene 和 Translog 的写入。这个过程中,副本分片的 Lucene 写入是冗余的,因为这个写入栈在 Primary 上进行了一遍,在 Replica 上会完整的再来一遍,开销非常高。
物理复制解决的就是从分片上冗余写入栈的开销。

通过 Segment 物理复制的能力,有效裁剪了 Replica 写入的计算开销,在主从副本场景下提升写入性能接近一倍。
4. 低成本存储
前面我们重点介绍了海量日志数据高吞吐写入层面的性能优化。海量的数据流入到 ES 之后,存储是另一大挑战,接下来我们来探讨一下海量存储场景如何进行成本优化,我们先来看看背景。

- 云原生环境下分布式架构层。ES 的主从副本乘以底层云盘、对象存储等三份副本(EC 编码优化推出可能在 1.33 左右)。
- 单机存储引擎层。由于 ES 是行列混存,且有丰富的索引结构,应用场景丰富的同时,也导致了单位文档存储成本放大较多。
- 底层基础设施。为了应对高吞吐写入,往往需要引入 SSD 硬盘,其成本高寿命短。如果用冷热架构,温层往往会挂多块 HDD 盘来扩大容量,此时单盘的损坏会导致整个节点替换,存在大量的数据恢复搬迁,代价太大。另外机器运维的人力成本也不低。
从上面几个维度的成本影响面来看,我们的优化重点一方面是降低单位文档的存储成本,另一方面是降低冗余副本、存储介质的成本。
4.1 压缩编码优化
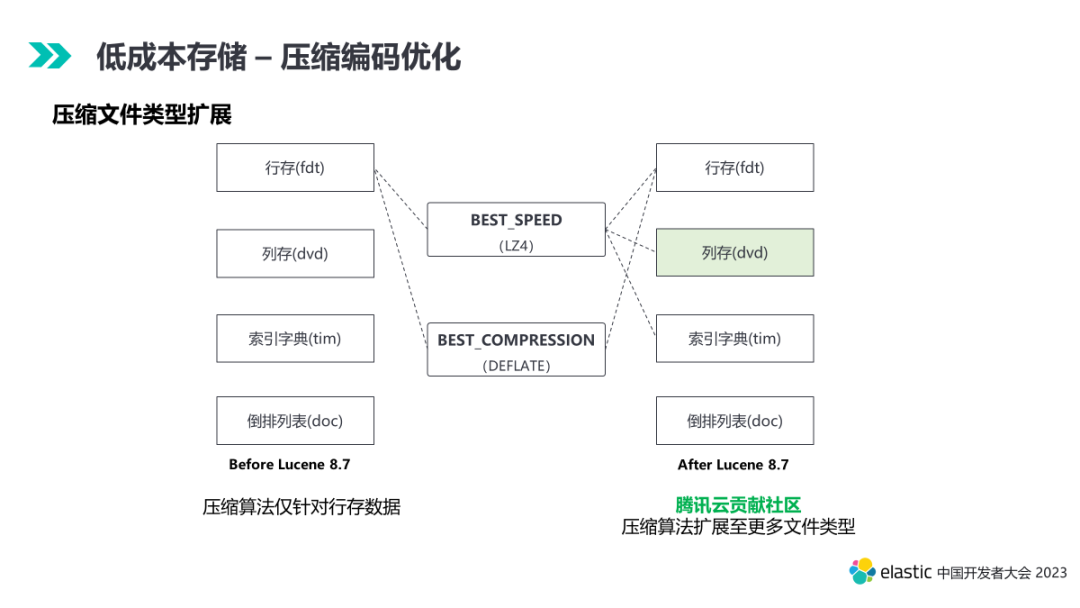
4.1.1 列存压缩

4.1.2 扩展基础压缩算法
除了优化列存以外,我们还引入了新的通用压缩算法。

4.2 混合存储引擎
前面主要介绍了通过压缩编码优化降低单位文档存储成本,而单位文档的存储优化是有极限的。另一个方向是从存储架构层面进行优化。在云原生的背景下,我们引入了自研混合存储引擎方案。
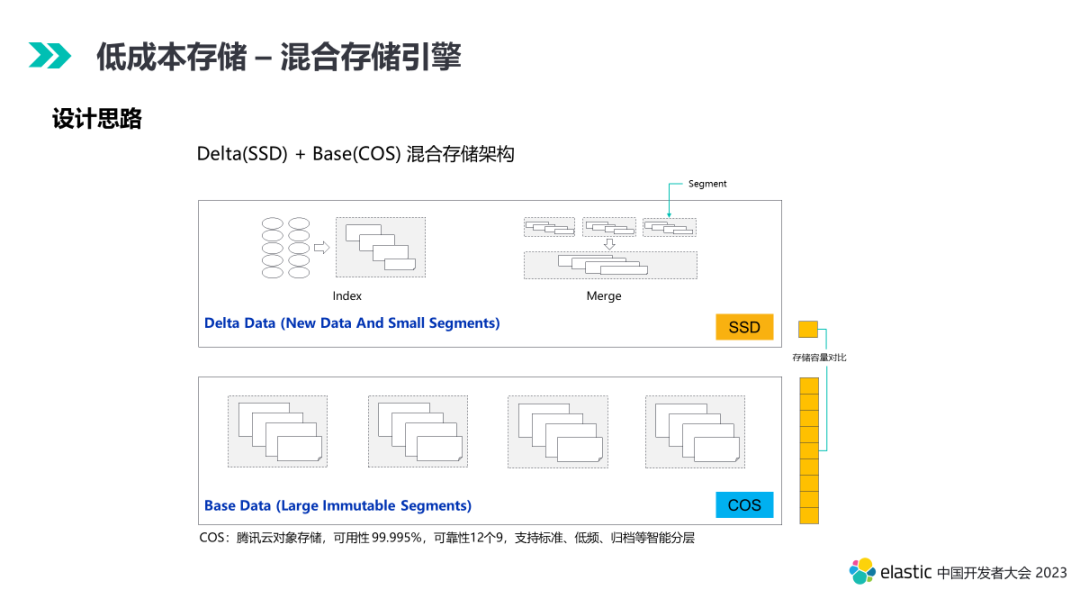
接下来我们结合索引数据的生命周期看看混合存储引擎的整体设计。
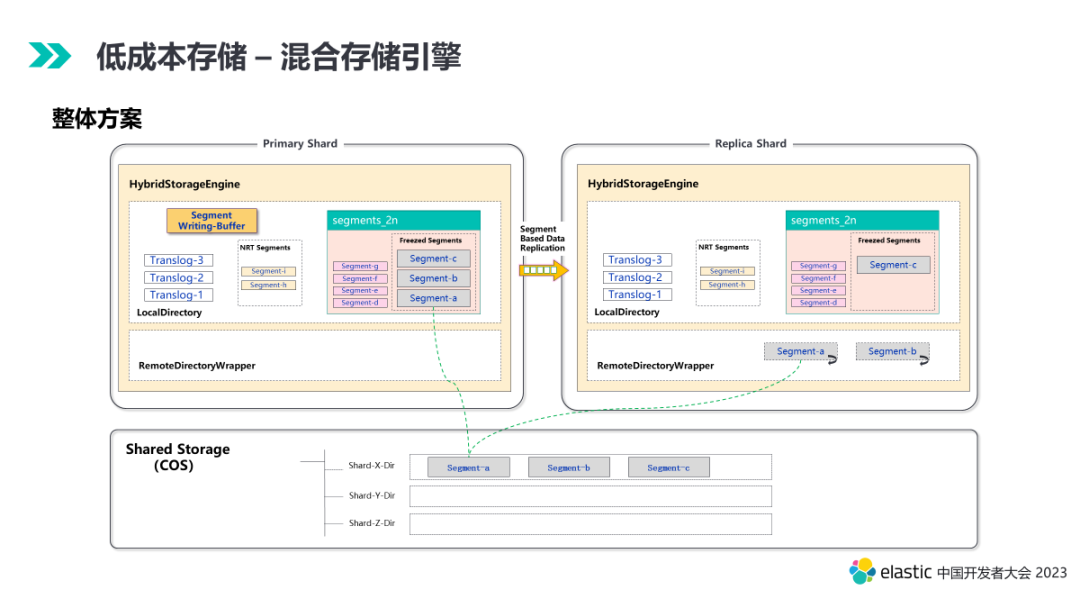
下面我们细分流程看看整体方案的设计细节。
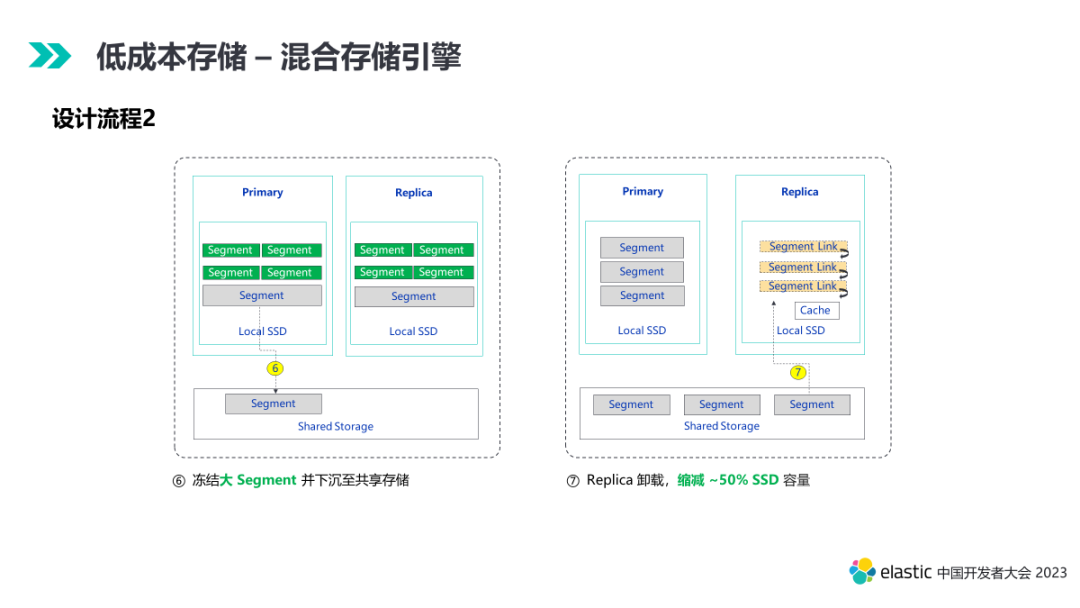
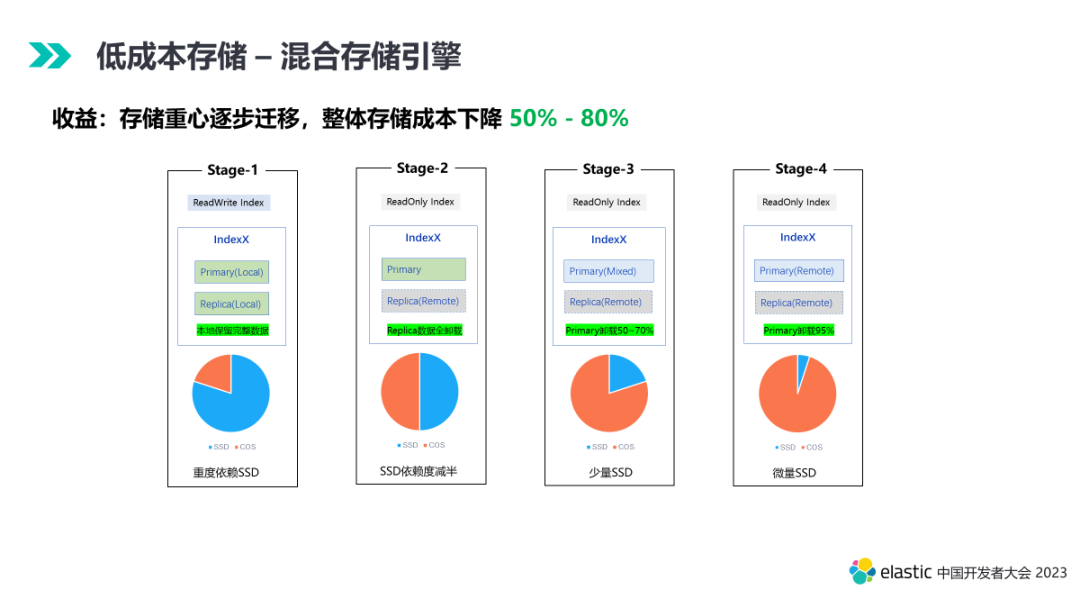
第七个阶段,数据的查询频次有所降低。一般情况,本地的 primary 即可满足绝大部分查询性能需求。此时 replica 会从本地卸载,读取会走远端共享存储,同时本地会有缓存机制保存用户常用查询数据提升性能。此时的查询会优先打到 primary。通过卸载本地 replica,我们可以缩减约 50% 的 SSD 容量。
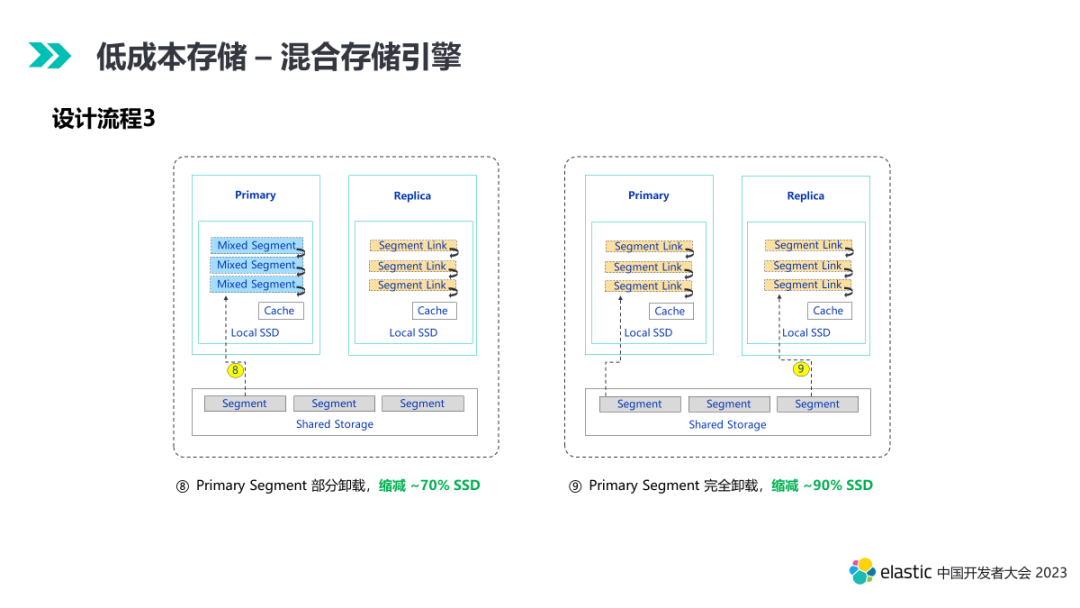
第九个阶段,查询几乎没有了,数据处于归档状态。本地的 primary 彻底实现卸载,依靠本地的缓存加速满足极少量的查询需求。本阶段 SSD 的缩减到达 90% 左右。

- Local Segment。行列存、索引文件等全部在本地,抗住热数据高并发读写请求。
- Mixed Segment。行列存等数据文件可能卸载,只有部分索引文件在本地,满足少量的查询请求。
- Remote Segment。行列存、索引文件等全部在远程,本地只有少量元数据文件,满足冷数据低成本归档需求。
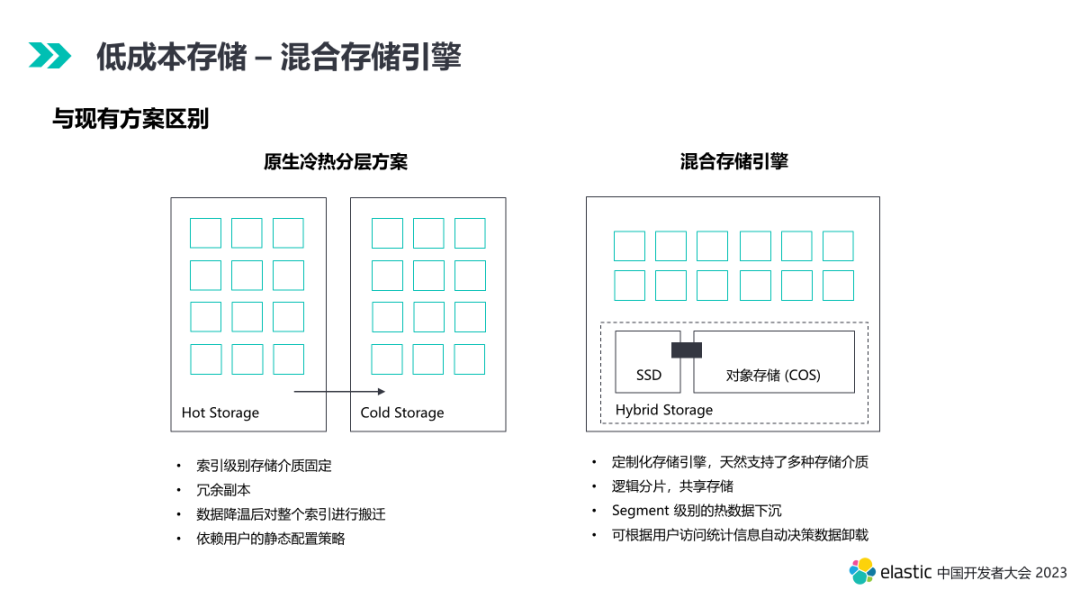
- 存储架构差异。1). 传统冷热分层索引级别存储介质固定。2). 混合存储 SSD 和对象存储是一个整体,数据可以双向局部流通。
- 副本差异。1). 传统冷热分层存在冗余副本。2). 混合存储底层采用共享存储,上层分片最终形态为逻辑分片,消除了云原生环境下的冗余副本。
- 数据搬迁差异。1). 传统冷热分层数据降温后索引需要整体搬迁。2). 混合存储支持在热数据阶段 segment 级别的数据下沉。
- 配置策略差异。1). 传统冷热分层依赖用户的静态配置策略,灵活性低、运维成本高。2). 混合存储除了支持用户配置外,还可根据用户访问统计信息自动决策数据下沉、卸载时机,实现数据智能分层。
截止目前日志场景海量数据的低成本存储优化到这里就介绍完毕了,后面继续介绍查询性能优化。
5. 高性能查询
5.1 查询性能影响面
前面我们分析了日志场景的海量存储成本优化。数据存储降本之后,接下来要考虑的是数据流出,如何解决用户查询性能问题。因为混合存储底层采用对象存储,其和 SSD 的性能差异肯定是有一个量级的区别。我们需要系统性做一些查询优化、缓存优化来找回这种存储介质的变更带来的性能损耗。
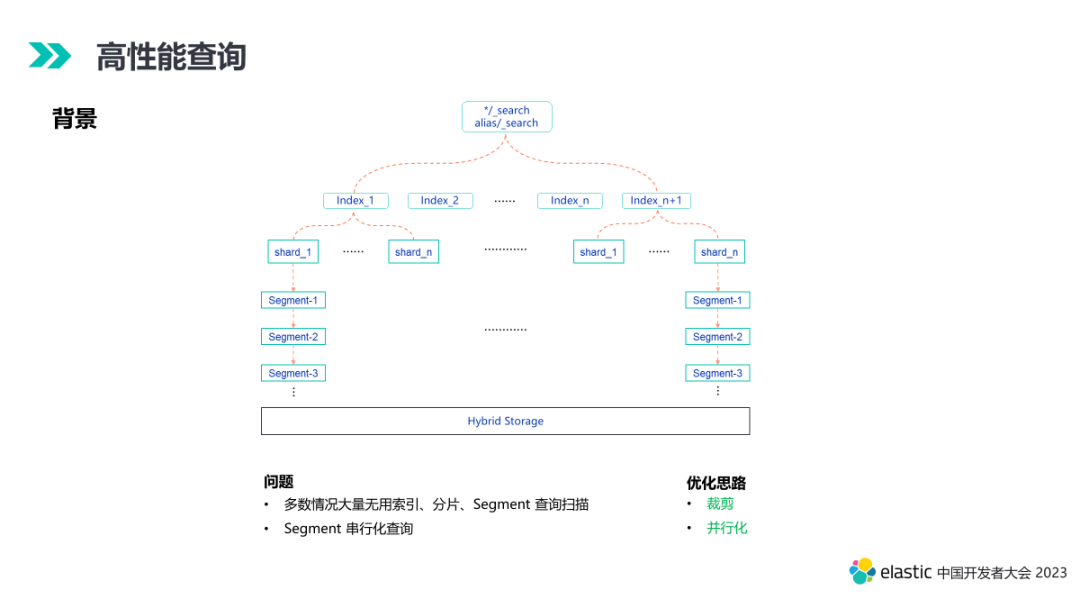
5.1.1 大量查询空转扫描
ES 有高效的倒排索引,点查的性能是非常强悍的。多索引或通过别名关联索引查询也是相对传统数据库的一个优势特性,而这一特性也会带来一些性能瓶颈问题。如上图所示,当我们查询的索引是一个星号,或者一个索引前缀匹配,或是一个别名的时候,底层可能关联多个物理索引,而我们的查询可能只有部分索引会有数据命中。而 ES 实际执行查询会将底层所有匹配的索引、包括每个索引底层的每个分片逐一遍历查询。这样会存在大量的无用索引、分片、segment 的查询空转扫描。
5.1.2 Segment 串行化执行
ES 底层分片之间是可以并行化的,但是单个分片内部多个 segment 之间是串行化的。混合存储引擎的底层是对象存储,多个 segment 串行化导致 IO 排队严重,查询效率低下,尤其是在大查询拉取数据较多的场景下。
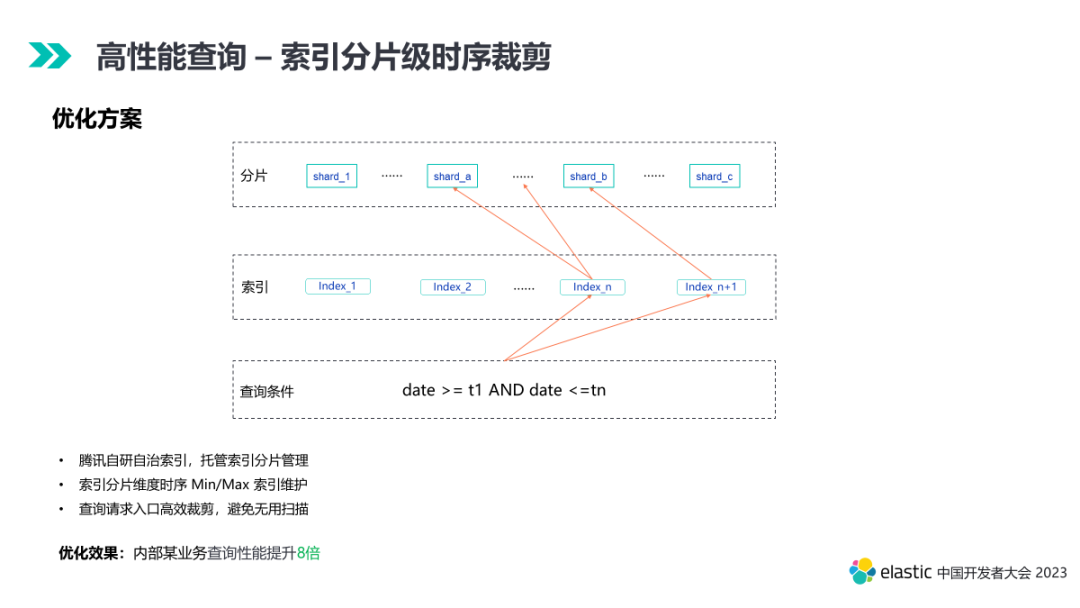
5.2 索引分片级时序裁剪优化
基于上面两大影响面分析,我们针对性的优化思路是查询裁剪和查询并行化,下面我们来展开分析。
5.3 Segment 级别查询裁剪
单个分片包含多个 segment,在查询过程中会依次遍历 segment 进行查询。但往往只有部分 segment 或者 segment 内部部分数据段存在有效数据,因此 segment 维度的查询裁剪也是优化的重点。
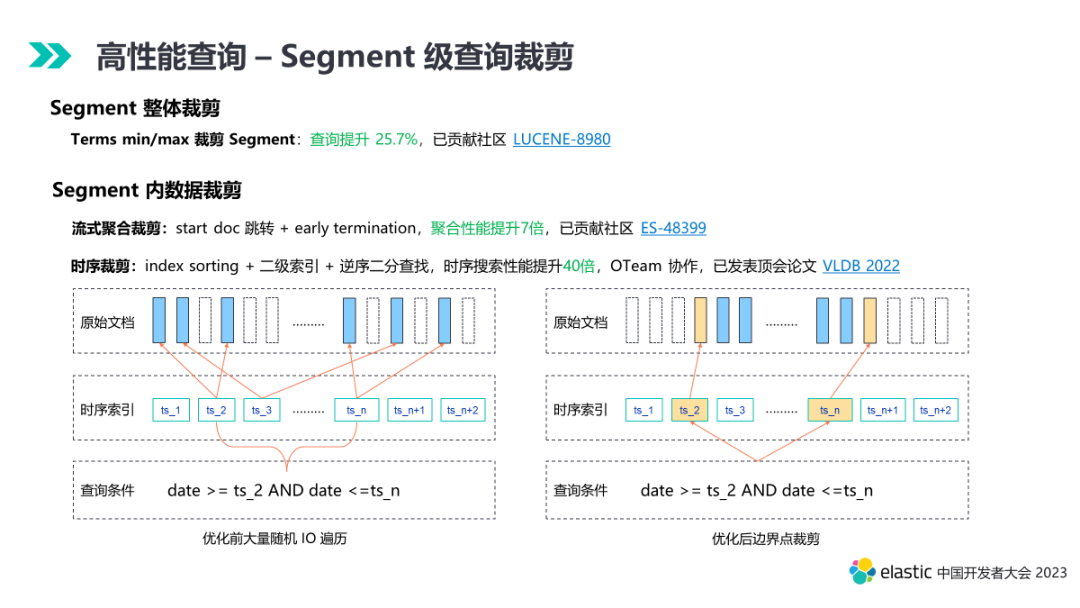
- Segment 整体裁剪。社区版本已经支持列存、数值索引等维度的裁剪,对 Terms 维度还缺少整体裁剪,腾讯进行了优化,并提交给了社区,点查性能提升 25.7%。
- Segment 内数据裁剪。1). 流式聚合裁剪。在 Composite Aggregation 场景,支持聚合翻页,每次翻页会涉及大量重复数据的查询,腾讯进行了优化,基于 index sorting,每次翻页采用起始 doc id 跳转,加上满足 size 条件提前结束优化,流式聚合性能提升 7 倍,且支持正、逆序,已反馈给社区。2). 时序裁剪。社区版本,在大的时序范围查询场景,构建实践范围 posting list 的时候,涉及大量的数据文件遍历,产生大量的随机 IO 影响查询性能。TencentES OTeam 协作进行了深度优化,基于 index sorting,利用 BKD 做二级索引,实现端点提取裁剪遍历,逆序采用二分查找,满足了大范围的时序查询性能需求,时序搜索性能提升 40 倍。
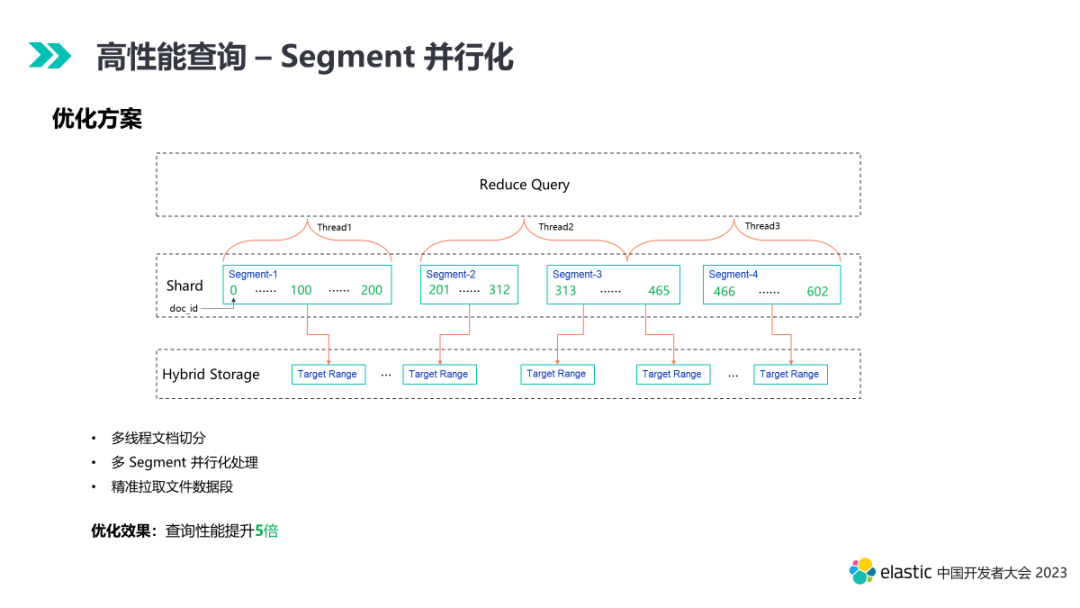
5.4 Segment 并行化
6. 云原生数据平台
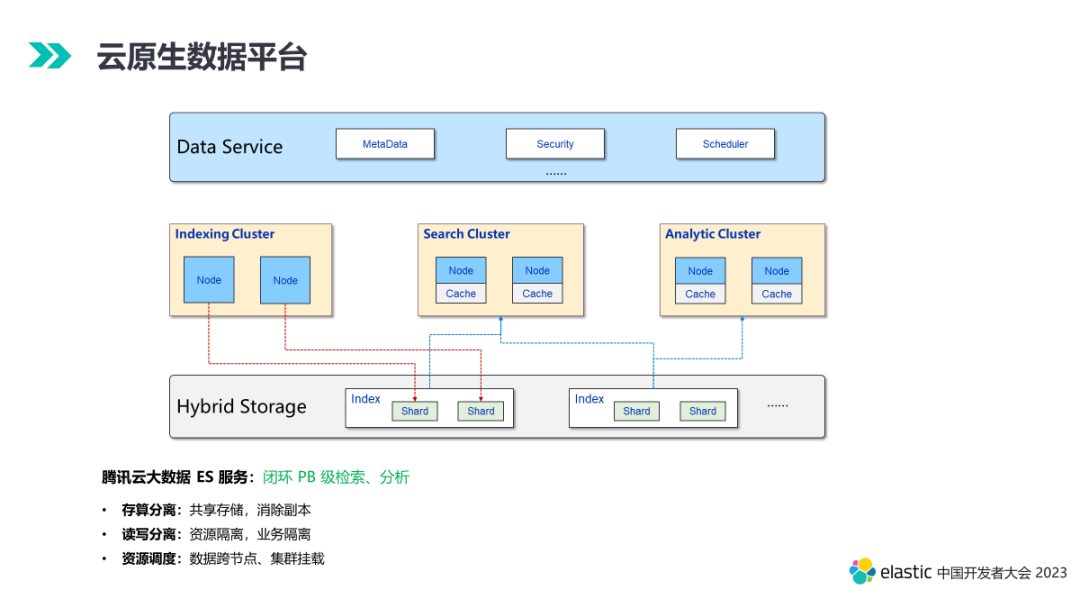
目前腾讯云推出的 Elasticsearch Serverless 服务已覆盖上述大部分能力,后续会持续完善,敬请关注。
作者:daniel
腾讯技术工程公众号