你背的“八股文”可能已经过时了
阿里妹导读
随着技术的不断更新迭代,一些曾经被认为是“标准答案”的观点和方法,已经不再适应当前的需求,甚至被视为过时的做法。在新的JDK版本中,许多新的特性、工具和方法被引入,使得Java编程变得更加简洁、高效和强大。所以,是时候对“八股文”进行一次知识库的清理和更新了。
一、String里不再使用char[]
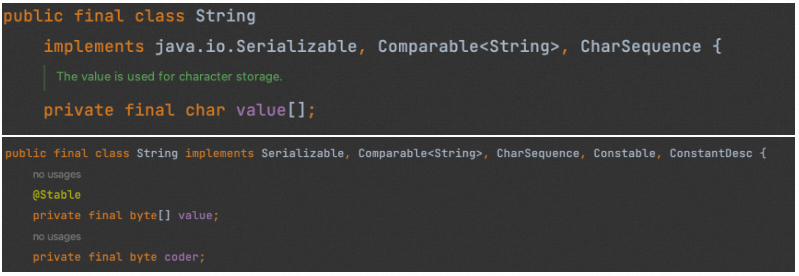
在JDK9之前,String内部是通过char数组(char[])来保存字符数据的。但在JDK9以后,String的实现内部改为使用byte数组(byte[])。
这样做的主要原因是为了节省内存空间,因为对于大量的拉丁文系列字符(如英文、数字、常见的标点符号等),使用byte数组存储比使用char数组可以节省一半的空间。同时,String类的内部还引入了一个名为coder的byte类型的字段。这个字段是用来标识存储在byte数组中的数据是何种字符编码的。
在新的String类的实现中,存在两种可能的字符编码:ISO-8859-1(一个字符占用一个字节)和UTF-16(一个字符占用两个字节)。
对于ISO-8859-1编码的字符串,coder的值为0,而对于UTF-16编码的字符串,coder的值为1。
这样,通过检查coder字段的值,就可以知道存储在byte数组中的数据应该使用什么样的编码方式进行处理,从而避免了因为字符编码不同而导致的处理错误。
二、switch支持的类型不再局限于基本类型与String
讲这一点之前,首先要了解什么是“模式匹配”,模式匹配是一种语言特性,用来检查某一个值是否匹配某种模式,并根据结果执行相应的代码,在Scala和Haskell中模式匹配是一项核心特性,而在Java中,模式匹配的概念在JDK14后被引入。简单而言,模式匹配可以让你检查一个变量或值的类型是否符合设定的的某些规则(模式),如果符合/不符合,就可以执行一些特定的操作。比如通过模式匹配,可以指定下面这样的操作(JDK14):
Object obj = "hello";
if (obj instanceof String str) {
System.out.println(str.length());
}在这个例子中,“String str”就是一个模式,同时完成了类型检查(instanceof)和向下转型(赋值给变量str),使得代码更为简洁。在JDK17中,switch也支持了这一功能:
Object obj = 10L;
switch (obj) {
case String str -> System.out.println("str: " + str);
case Integer intNum -> System.out.println("int: " + intNum);
case Long longNum -> System.out.println("long: " + longNum);
default -> throw new IllegalStateException("Unexpected value");
}不过目前的模式匹配主要还是应用在类型检查的时候自动转换(略简陋),在其他语言中,模式匹配还可以实现各种功能,比如在匹配的同时提取复杂数据结构中的值:
val list = List(1, 2, 3)
list match {
case head :: tail => println(s"head: $head, tail: $tail")
case Nil => println("empty list")
}在这个例子中head :: tail就是一个模式,将队列的头尾分别放入head和tail对象中,从而执行下一步操作。
三、synchronized的偏向锁已经被废弃了
首先来回顾一下什么是偏向锁。偏向锁是Java中synchronized关键字的一种优化手段,基本思想是同一个线程的反复访问无需加锁,主要目标是消除数据在没有竞争的情况下的同步操作,提高运行时性能。实际执行时,如果一个线程获得了锁,那么锁就进入偏向模式,此时记录下线程ID,当这个线程再次请求锁时,无需再做任何同步操作,这样就省去了大量有关锁申请的操作。
但是在真实情况中,偏向锁并不总能带来预期的性能优势,相反地,在某些情况下(多核处理器环境),偏向锁的撤销需要进入全局安全点(即safepoint,虚拟机将所有的线程暂停执行),会带来比较长的停顿时间。
偏向锁想法是好的,但是增加了JVM的复杂性,同时也并没有为所有应用都带来性能提升。因此,在JDK15中,偏向锁被默认关闭,在JDK18中,偏向锁已经被彻底废弃(无法通过命令行打开)。
四、G1推出后,分代回收的策略也发生了变化
这个大家相对比较熟悉,因为JDK7已经引入了G1垃圾收集器,在JDK9中被设置为默认的垃圾收集器。在G1中,没有严格的年轻代和老年代的划分,而是分为多个大小相同的独立区域,每个区域在不同的时间点可能会扮演不同的角色。五、不需要考虑JDK与JRE的关系了
JDK和JRE都是Java的重要组成部分,但它们的角色和用途是不同的。JDK是Java开发工具包,主要用于开发Java应用。它包含了JRE,同时还提供了一些额外的工具,如编译器(javac)、调试器(jdb)等。JRE则是运行Java应用程序所需的环境。它包含了Java虚拟机(JVM)和Java类库,也就是Java应用程序运行时所需的核心类和其他支持文件。
在JDK 8及之前的版本中,Oracle会提供独立的JRE和JDK供用户下载。也就是说,你可以只安装JRE来运行Java程序,也可以安装JDK来开发Java程序。
然而从JDK 9开始,Oracle不再单独发布JRE。取而代之的是jlink工具,可以使用这个工具来生成定制的运行时镜像。这种方式简化了Java应用的部署,因你只需要分发包含你的应用和定制运行时镜像的包,不需要单独安装JRE。
六、泛型可能不再是“语法糖”
提起Java的泛型,很多人第一时间想到的就是“语法糖”、“类型擦除”。类型擦除是Java泛型的一种实现机制。这意味着在编译时,泛型类型会被替换为它的限定类型(如果没有明确指定,那就是Object),并且在字节码中并不保留泛型信息。比如,如果你有一个如下的泛型类:
public class Box<T> {
private T object;
public void set(T object) { this.object = object; }
public T get() { return object; }
}在编译后,这个类会变成:
public class Box {
private Object object;
public void set(Object object) { this.object = object; }
public Object get() { return object; }
}类型擦除最大的优点就是保证了与老版本Java代码的兼容**性,因为在引入泛型之前的Java代码都是没有泛型信息的。但类型擦除毕竟是不得已为之,会有一些缺点,比如无法执行某些类型检查、导致方法签名冲突**等。
接着, Valhalla项目出现了,Valhalla项目是OpenJDK的一个长期项目,它的主要目标是为Java引入一些改进和新特性,包括泛型的专门化。目前Java的泛型实现使用了类型擦除,这意味着泛型信息只存在于编译时,而在运行时则被擦除。
泛型的专门化意味着泛型信息可以保留到运行时,从而可以根据类型参数生成特定的代码,提高运行效率,并且实现更安全的类型。不过Valhalla项目的步子迈的有点大,进展比较慢,有很多人说这个项目“凉了”。
尽管如此,很多新特性已经在预览版本实现了,未来就会在正式版中出现。
七、Java可以在接口中定义私有方法
Java中的接口的目的是定义公开的API,而不是实现方法细节,所以在JDK8以前都不支持默认和静态方法。但是出于便捷性的考虑,JDK8中支持方法的默认实现,这样当一个接口有大量实现类的情况下,可以在不破坏原有实现的前提下迭代API。
JDK8中接口类的默认实现解决了模型抽象中的很多问题,随之而来的是在接口中的默认方法如果需要共享一些代码段,只能将这些代码段抽象出一个新的函数。
如果这个函数是静态的(JDK8支持接口中定义静态函数),那么在函数里无法访问其他非静态API;如果是一个有默认实现的API,就会导致实现类可以自由重载。而且最重要的是,不管怎么样,API都会被暴露出去,这不是开发者想要看到的。
最终,JDK9允许了开发者在接口中定义私有方法,从而提取和封装默认方法中的公共代码,减少代码的冗余。