Linux内存映射mmap源码解析
内存映射(Memory Mapping)是一种操作系统提供的技术,它允许将文件或设备中的数据直接映射到进程的内存空间中,使得进程可以像访问内存一样来读取和写入这些数据。简单说就是将磁盘上的文件映射到进程的虚拟地址空间中。
通过内存映射,我们可以在不需要进行繁琐的读取和写入操作的情况下,直接通过指针对文件进行读写操作。也就是说,当我们使用内存映射后,文件中的数据会被映射到一个特定区域的内存中,并且该内存区域与磁盘上文件的内容保持同步。可以把内存映射看作是一个窗口,你能够透过这个窗口直接看到并修改文件中的内容。你可以像读写普通变量一样操作这段内存空间,而无需关心底层的读取和写入过程。
内存映射有很多应用场景,比如在处理大型文件时,可以避免频繁地从磁盘读取和写入数据;在多进程之间共享数据时,可以方便地实现数据交互;在网络编程中使用套接字时,也可以利用内存映射来提高数据传输的效率等等。总之,内存映射是一种便捷高效的数据访问方式。
一、概览
mmap是Linux中使用频率非常高的一个系统调用:
- 程序运行前,mmap会先将动态链接库映射到进程的地址空间。
- 用户调用malloc,如果分配的内存大小大于阈值,则直接使用mmap分配
- 使用POSIX的有名信号量时,自动调用mmap将共享文件(其中包括futex锁)映射至进程的地址空间
- 共享内存的底层原理与mmap密不可分
- ...
但是mmap处于内核的内存管理和文件管理这两个模块的交汇处,比较复杂,也比较有趣,个人认为有必要深入了解一下mmap。
二、mmap API
void *mmap(void addr, size_t length, int prot, int flags, int fd, off_t offset);mmap将在进程的地址空间中创建一个新的内存映射,并返回该内存的起始虚拟地址。
如果参数addr不为null,则该内存映射的起始地址为参数addr,如果addr为null那么内核将自动找到一个未映射的虚拟地址空间创建映射。
参数length指明内存映射区域的长度。
参数prot表示内存区域的可读、可写、可执行、可获取等属性。
参数fd表示内存映射是否关联一个实体文件,如果是则fd的值是一个大于0的值,表示该映射是一个文件映射;如果不是则fd = -1,此时该内存映射就是所谓的匿名映射。
参数flags,标识了这个内存映射是否是进程间共享的,以及对该映射的改动是否会同步到底层文件。
- MAP_SHARED :表示这个映射是进程共享的,对映射的改动其他进程都可见。且如果内存映射关联一个实体文件,那么对它的改动将会同步到底层文件中。
- MAP_PRIVATE:创建一个copy_on_write的内存映射,当一个进程改动映射内容时,将创建一个额外的内存映射,进程的改动只在这个额外复制上执行,这些改动对其他进程不可见。且如果内存映射关联一个实体文件,对它的改动不会同步到底层文件中。
小结一下,参数fd将映射分为文件映射和匿名映射,flags将映射分为共享映射和私有映射。那么两两组合就有4中类型,下表简要介绍它们各自的用途
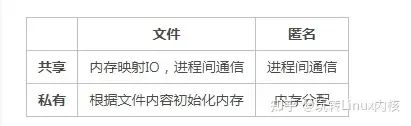
内存映射IO:将一个文件以共享的方式映射时,对它进行的改动将自动同步到磁盘上,因此文件的共享映射等同于实现了对文件的读写,功能上无限接近与Linux的文件IO系统调用read、write等。
进程间通信:mmap的另一个重要用途是实现进程间通信,因为不同进程的地址空间彼此隔离,一个进程不能直接访问另一个进程的地址空间。通过mmap和PageCache,使得不同进程的不同虚拟地址能够映射到同一物理地址上。此时一个进程即使凭借虚拟地址进行内存修改,另一个进程也能看到物理空间的变
化。从上表可以看出,无论是匿名映射还是基于文件的映射,都可以实现进程间通信。比如POSXI信号量中分为有名信号量和匿名信号量,有名信号量通过基于文件的共享映射实现,而匿名信号量通过匿名共享映射实现。
据文件内容初始化内存:最常见的就是执行一个程序前,利用mmap将动态链接库加载到进程的地址空间中。由于设置了MAP_PRIVATE选项,对内存映射的任何改动都不会影响到文件的内容,因此可以防止恶意程序修改共享库文本。
内存分配:在使用malloc分配内存时,如果请求内存的大小大于M_MMAP_THRESHOLD,则直接使用mmap进行内存分配。(目前, glibc库会动态调整M_MMAP_THRESHOLD的大小,详见mallopt man page)
三、mmap实现
mmap内存映射的实现过程:
- 进程启动映射过程,并在虚拟地址空间中为映射创建虚拟映射区域
- 调用内核空间的系统调用函数mmap(不同于用户空间函数),实现文件物理地址和进程虚拟地址的一一映射关系
- 进程发起对这片映射空间的访问,引发缺页异常,实现文件内容到物理内存(主存)的拷贝
适合的场景
- 您有一个很大的文件,其内容您想要随机访问一个或多个时间
- 您有一个小文件,它的内容您想要立即读入内存并经常访问。这种技术最适合那些大小不超过几个虚拟内存页的文件。(页是地址空间的最小单位,虚拟页和物理页的大小是一样的,通常为4KB。)
- 您需要在内存中缓存文件的特定部分。文件映射消除了缓存数据的需要,这使得系统磁盘缓存中的其他数据空间更大 当随机访问一个非常大的文件时,通常最好只映射文件的一小部分。映射大文件的问题是文件会消耗活动内存。如果文件足够大,系统可能会被迫将其他部分的内存分页以加载文件。将多个文件映射到内存中会使这个问题更加复杂。
不适合的场景
- 您希望从开始到结束的顺序从头到尾读取一个文件
- 这个文件有几百兆字节或者更大。将大文件映射到内存中会快速地填充内存,并可能导致分页,这将抵消首先映射文件的好处。对于大型顺序读取操作,禁用磁盘缓存并将文件读入一个小内存缓冲区
- 该文件大于可用的连续虚拟内存地址空间。对于64位应用程序来说,这不是什么问题,但是对于32位应用程序来说,这是一个问题
- 该文件位于可移动驱动器上
- 该文件位于网络驱动器上
示例代码
//
// ViewController.m
// TestCode
//
// Created by zhangdasen on 2020/5/24.
// Copyright © 2020 zhangdasen. All rights reserved.
//
#import "ViewController.h"
#import <sys/mman.h>
#import <sys/stat.h>
@interface ViewController ()
@end
@implementation ViewController
- (void)viewDidLoad {
[super viewDidLoad];
NSString *path = [NSHomeDirectory() stringByAppendingPathComponent:@"test.data"];
NSLog(@"path: %@", path);
NSString *str = @"test str2";
[str writeToFile:path atomically:YES encoding:NSUTF8StringEncoding error:nil];
ProcessFile(path.UTF8String);
NSString *result = [NSString stringWithContentsOfFile:path encoding:NSUTF8StringEncoding error:nil];
NSLog(@"result:%@", result);
}
int MapFile(const char * inPathName, void ** outDataPtr, size_t * outDataLength, size_t appendSize)
{
int outError;
int fileDescriptor;
struct stat statInfo;
// Return safe values on error.
outError = 0;
*outDataPtr = NULL;
*outDataLength = 0;
// Open the file.
fileDescriptor = open( inPathName, O_RDWR, 0 );
if( fileDescriptor < 0 )
{
outError = errno;
}
else
{
// We now know the file exists. Retrieve the file size.
if( fstat( fileDescriptor, &statInfo ) != 0 )
{
outError = errno;
}
else
{
ftruncate(fileDescriptor, statInfo.st_size + appendSize);
fsync(fileDescriptor);
*outDataPtr = mmap(NULL,
statInfo.st_size + appendSize,
PROT_READ|PROT_WRITE,
MAP_FILE|MAP_SHARED,
fileDescriptor,
0);
if( *outDataPtr == MAP_FAILED )
{
outError = errno;
}
else
{
// On success, return the size of the mapped file.
*outDataLength = statInfo.st_size;
}
}
// Now close the file. The kernel doesn’t use our file descriptor.
close( fileDescriptor );
}
return outError;
}
void ProcessFile(const char * inPathName)
{
size_t dataLength;
void * dataPtr;
char *appendStr = " append_key2";
int appendSize = (int)strlen(appendStr);
if( MapFile(inPathName, &dataPtr, &dataLength, appendSize) == 0) {
dataPtr = dataPtr + dataLength;
memcpy(dataPtr, appendStr, appendSize);
// Unmap files
munmap(dataPtr, appendSize + dataLength);
}
}
@end基于文件的内存映射必然与文件系统的联系比较大,其中最关键的就是PageCache(页高速缓存)。PageCache一方面是操作系统对磁盘的缓存,起到加速的作用,另一方面,每个文件的每个页在内存中对应的PageCahce都是独一无二的,这就为mmap的实现打下了基础。
Linux的虚拟文件系统的主要数据结构有:file、dentry、inode,内核编写者选择将PageCache与inode进行联系,因为只有inode和文件的是一对一的关系。inode数据结构中有一个i_mapping属性,它是一个指向struct address_space的指针,address_space数据结构的page_tree属性又保存了一个基数树结构,这颗基数树就管理了对应于该文件的所有Page。在linux中每一个Page结构都唯一确定一个物理内存页,该物理内存页的内容就是对部分磁盘文件的数据拷贝,且在内存中只有这一份拷贝,这就是概念上所说的PageCache。
如此,不同进程只要使用同一个inode来获取对应的PageCache,那么就能够映射同一个物理页,如此就能达成共享内存的目的。
如下图所示,是file、dentry、inode、address_space这几个结构的关系图:
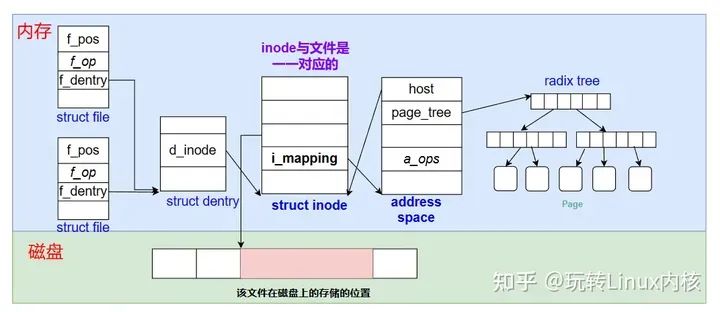
你可以看到,不同的struct file结构可能关联到同一个文件,它们可能由不同的进程打开,各自维护自己的读写指针f_pos。那么dentry结构呢?图中只画了一个dentry,但并不代表dentry与磁盘文件是一一对应的,比如硬链接就是一个例子:文件名不同那么dentry也不同,但是关联到的inode却是同一个,这样看来确实只有inode结构与磁盘文件一一对应了。所以address_space结构由inode来管理是比较合适的。
题外话,上述这些结构,每个结构都有一个特殊的成员XX_ops,s这个结构的成员大多是函数指针,比如f_ops:
struct file_operations {
struct module *owner;
loff_t (*llseek) (struct file *, loff_t, int);
ssize_t (*read) (struct file *, char *, size_t, loff_t *);
ssize_t (*write) (struct file *, const char *, size_t, loff_t *);
int (*readdir) (struct file *, void *, filldir_t);
unsigned int (*poll) (struct file *, struct poll_table_struct *);
int (*ioctl) (struct inode *, struct file *, unsigned int, unsigned long);
int (*mmap) (struct file *, struct vm_area_struct *);
int (*open) (struct inode *, struct file *);
int (*flush) (struct file *);
int (*release) (struct inode *, struct file *);
int (*fsync) (struct file *, struct dentry *, int datasync);
int (*fasync) (int, struct file *, int);
int (*lock) (struct file *, int, struct file_lock *);
ssize_t (*readv) (struct file *, const struct iovec *, unsigned long, loff_t *);
ssize_t (*writev) (struct file *, const struct iovec *, unsigned long, loff_t *);
};熟悉的函数有read、write、mmap、llseek等。这就是操作接口, file_operations规定了一个file能够做些什么操作,但没有具体实现它,具体的实现则由各自的不同种类的文件实现它, 这就是Linux 虚拟文件系统的关键所在:上层调用者不必知道一个文件具体是指什么,无论是Ext文件、管道文件还是共享文件,都只需要调用这些接口即可,从而实现了“一切皆文件”的效果。
本文主要关心其中的mmap操作,因此所有需要或者可以进行内存映射的文件系统,都必须设置mmap指针,否则将出错。Linux的Ext文件系统则使用默认的mmap函数,generic_file_mmap。而管道文件系统不能进行mmap操作,因此将这个指针设置成了NULL。
3.2mmap与匿名映射
上一节介绍到,mmap基于文件映射时,内存页面都有对应的磁盘存储位置。某一时刻,如果系统内存不足,那么操作系统会首先将内存中的脏页刷盘,然后再回收该Page结构以应对内存紧缺的情况。当然如果是私有映射,该内存页将直接被丢弃。
但如果是匿名页射呢?它们不会与磁盘的某个位置对应,是否表示当内存紧张时,系统将不会回收这些匿名映射对应的页呢?
答案视操作系统是否开启了swap机制而定。如果没有开启swap机制,那么内核不能回收这些页;如果开启了swap机制,那么匿名页仍然会被换出到磁盘设备中的一块专有区域中,这块区域就叫做swap area。
swap area散落在不同的块设备上,内核用swap_info_struct数组来管理这些交换区。swap_info_struct如下所示:
struct swap_info_struct {
// ...
struct file *swap_file; // 指向一个文件或者设备
struct block_device *bdev; // 指向文件/分区所在的块设备的对应数据结构
// ...
unsigned short *swap_map;
// ...
unsigned int pages; // 该swap_area有多少槽位
};swap_file指向该交换区对应的磁盘文件或者设备,pages表示该交换区一共有多少“槽位”,一般情况下一个槽位的大小与操作系统一个页的大小相同,也即4KB大小。swap_map指向一个短整型数组,这个数组的大小与槽位数相同,其中的每个元素都被用作一个访问计数器,表示有多少个进程共享这个交换页。
一个槽位在磁盘上的位置由它所在的swap area(即swap_info数组的小标)以及在给swap area中的编号决定,两者构成了swp_entry_t:
typedef struct {
unsigned long val;
} swp_entry_t;swp_entry_t其实只是一个长整型,内核大致将其分成如下部分:
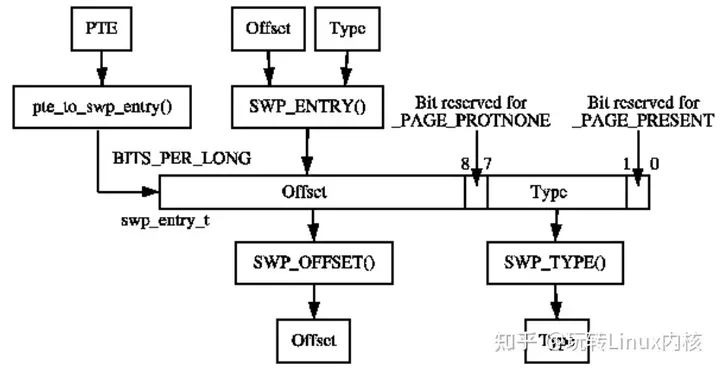
可以看到大致上分成Type和Offset两部分,其中Type就是值swap_info的数组下标,Offset指该槽位在对应的swap area中的编号。
而它的第0位,用作Page_Present标记。这其实与pte表项有关, swp_entry_t占用的存储空间其实就是pte_t, 它与pte_t是可以相互转化的:
- 当一个匿名内存页还在内存时,它对应的pte表项的值就表示为原本的意思,pte的第0为present被置1。
- 当内核决定将一个匿名页 swap out时,会把pte表项的值当作swp_entry_t来记录内存页的去向,这是为了之后的swap in做准备,内核需要根据swp_entry_t的信息定位磁盘上的页。且内核swap out一个匿名页时,将其swp_entry_t的最后一位置0。
所以,swp_entry_t与pte_t就像一个union数据结构,在不同的场景下有不同的解释。特别的,当对应的页位于内存时,其第0位置1,当对应的页已经swap out到磁盘时,其第0位置0,这样就可以通过根据最后一位的数值来判断对应的页是否位于内存。
注意以上的行为只针对匿名页,如果是基于文件的页呢?它们被刷盘后,其pte_t被清零。
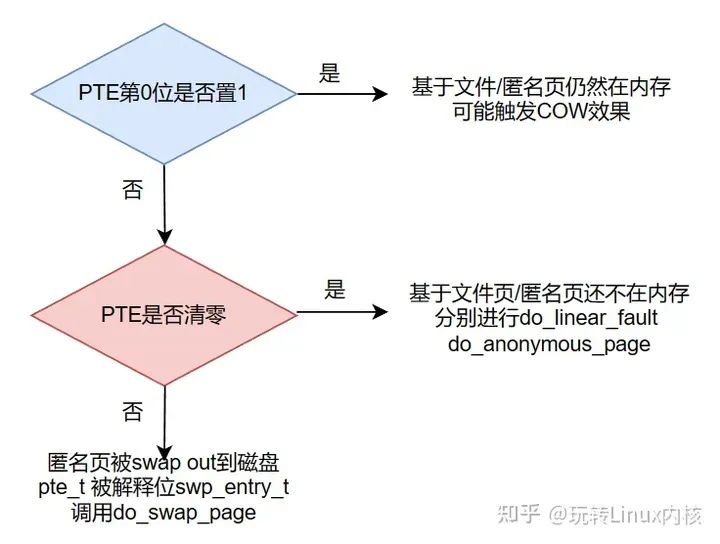
因此我们可以通过判断pte_t的值及其第0位的值判断它对应的页是否在内存,是否是匿名页:
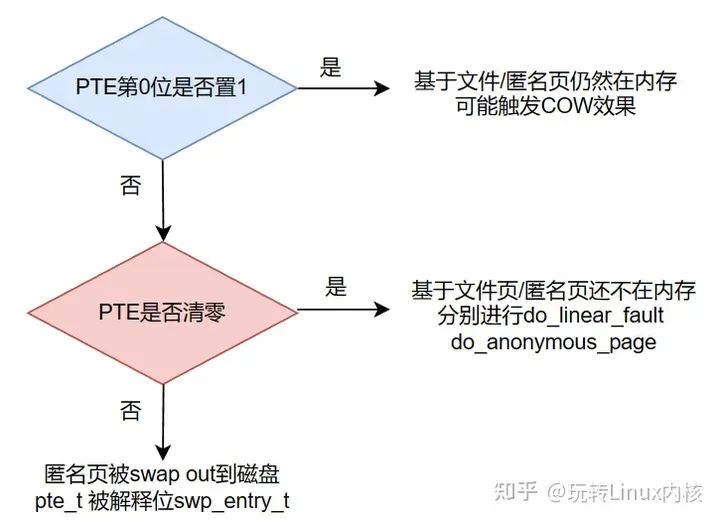
这样的双重判断在之后的缺页中断处理流程中被使用,内核会根据各种不同的情况调用不同的函数以处理不同种类的缺页中断。
3.3mmap源码浅析
从系统调用开始首先进入mmap的系统调用,它只是转发给了另一个系统调用sys_mmap_pgoff
SYSCALL_DEFINE6(mmap, unsigned long, addr, unsigned long, len,
unsigned long, prot, unsigned long, flags,
unsigned long, fd, unsigned long, off)
{
// ...
error = sys_mmap_pgoff(addr, len, prot, flags, fd, off >> PAGE_SHIFT); // 调用sys_mmap_pgoff
// ..
}
SYSCALL_DEFINE6(mmap_pgoff, unsigned long, addr, unsigned long, len,
unsigned long, prot, unsigned long, flags,
unsigned long, fd, unsigned long, pgoff)
{
struct file * file = NULL;
unsigned long retval = -EBADF;
if (!(flags & MAP_ANONYMOUS)) {
if (unlikely(flags & MAP_HUGETLB))
return -EINVAL;
file = fget(fd);
if (!file)
goto out;
}
// ..
retval = do_mmap_pgoff(file, addr, len, prot, flags, pgoff);
// ..
}sys_mmap_pgoff只是通过flags判断是否是匿名映射,如果不是则获取对应的struct file结构,然后再将其转发给do_mmap_pgoff函数,而该函数和它调用的mmap_region就是发挥主要作用的两个函数。
do_mmap_pgoff位于mmap.c文件中:
unsigned long do_mmap_pgoff(struct file * file, unsigned long addr,
unsigned long len, unsigned long prot,
unsigned long flags, unsigned long pgoff)
{
struct mm_struct * mm = current->mm;
struct inode *inode;
unsigned int vm_flags;
/* 掠过一系列检查 */
// 调用get_unmapped_area获得当前进程中还没有被映射的虚拟内存
addr = get_unmapped_area(file, addr, len, pgoff, flags);
/* 设置vmarea的flags,尤其需要对基于文件和匿名页映射做出一些区分 */
vm_flags = calc_vm_prot_bits(prot) | calc_vm_flag_bits(flags) |
mm->def_flags | VM_MAYREAD | VM_MAYWRITE | VM_MAYEXEC
inode = file ? file->f_path.dentry->d_inode : NULL;
// 略过一些检查
if (file) { // 基于文件的映射
switch (flags & MAP_TYPE) {
case MAP_SHARED: //共享映射
// ...
vm_flags |= VM_SHARED | VM_MAYSHARE; // 设置shared标志
// ...
case MAP_PRIVATE: // 私有映射
// ...
if (!file->f_op || !file->f_op->mmap) // 基于文件的映射必须要有这两个数据结构!!否则错误
return -ENODEV;
}
} else { // 匿名映射
switch (flags & MAP_TYPE) {
case MAP_SHARED:
vm_flags |= VM_SHARED | VM_MAYSHARE;
break;
case MAP_PRIVATE:
pgoff = addr >> PAGE_SHIFT;
break;
default:
return -EINVAL;
}
}
return mmap_region(file, addr, len, flags, vm_flags, pgoff,
accountable);
}do_mmap_pgoff主要做了三件事:
- 调用get_unmapped_area获得当前进程中还没有被映射的虚拟内存
- 根据是否基于文件映射,是否共享/私有映射对vma的标志位进行设置
- 调用mmap_region函数
接下来看mma_region函数:
unsigned long mmap_region(struct file *file, unsigned long addr,
unsigned long len, unsigned long flags,
unsigned int vm_flags, unsigned long pgoff,
int accountable)
{
struct mm_struct *mm = current->mm;
struct vm_area_struct *vma, *prev;
int error;
struct inode *inode = file ? file->f_path.dentry->d_inode : NULL;
/* Clear old maps */
error = -ENOMEM;
munmap_back:
vma = find_vma_prepare(mm, addr, &prev, &rb_link, &rb_parent); // 检查是否addr地址已经存在一个内存映射
if (vma && vma->vm_start < addr + len) { // 如果本来存在映射
if (do_munmap(mm, addr, len)) // 则do_munmap解除映射
return -ENOMEM;
goto munmap_back;
}
// ...
/*略过一些检查*/
// ...,首先find_vma_prepare检查是否在addr这个地址已经存在一个内存映射,则先接解除原来的映射
接着,分配一个vm_area_struct结构,该结构是对进程虚拟地址区间的描述:
vma = kmem_cache_zalloc(vm_area_cachep, GFP_KERNEL); //分配一个vma结构
if (!vma) {
error = -ENOMEM;
goto unacct_error;
}
vma->vm_mm = mm; // 对应于本进程的mm_struct结构
vma->vm_start = addr; //映射开始区域
vma->vm_end = addr + len; // 映射结束区域
vma->vm_flags = vm_flags; // 设置vmflags,标志位在do_mmap_pgoff中就已经处理好了
vma->vm_page_prot = vm_get_page_prot(vm_flags);
vma->vm_pgoff = pgoff; // 设置偏移,基于文件映射时,这个偏移就是指文件内偏移量几个结构的关系如下所示,task_struct结构是进程资源的集合的描述,其中的mm_struct指针指向mm_struct, 该结构就是对进程的虚拟地址空间的一个抽象。vma结构是对进程某个虚拟地址区间的描述,一个mm_struct肯能管理多个vma结构,并使用红黑树将它们管理起来。如果映射是基于文件,那么vma有个vm_file结构指向某文件的file_struct。
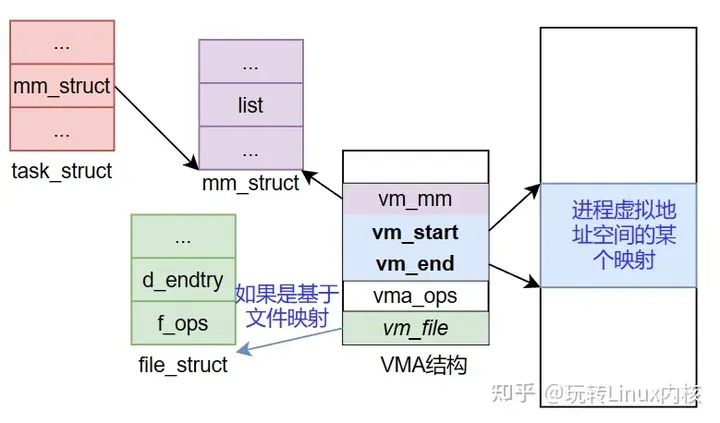
再回到mmap_region中,它分配了vma后,就根据映射是否基于文件,进行不同的处理:
if (file) { // 如果是基于文件的映射
// ...
vma->vm_file = file;
get_file(file);
error = file->f_op->mmap(file, vma); // 进行mmap
// ...
} else if (vm_flags & VM_SHARED) { // 如果是匿名共享映射
error = shmem_zero_setup(vma); // 在共享文件系统上分配file struct,并之后会以0初始化之。
// ...
}如果是基于文件的映射,最终会调用file->f_op->mmap进行映射,如果文件属于ext文件系统,那么该函数指针指向generic_file_mmap:
int generic_file_mmap(struct file * file, struct vm_area_struct * vma)
{
struct address_space *mapping = file->f_mapping;
if (!mapping->a_ops->readpage)
return -ENOEXEC;
file_accessed(file);
vma->vm_ops = &generic_file_vm_ops; // 主要工作就是这个
vma->vm_flags |= VM_CAN_NONLINEAR;
return 0;
}
struct vm_operations_struct generic_file_vm_ops = {
.fault = filemap_fault,
};可以看到该函数的主要工作就是将vma->vm_ops指针设置为generic_file_vm_ops,将来发生缺页中断时,就通过这个指针调用generic_file_vm_ops的filemap_fault函数。然后mmap的整个流程就基本束了,它不会再分配任何内存也不会实际加载这些页面。至于,匿名共享映射,将调用shmem_zero_setup在共享文件系统上分配inode并创建file结构,我不打算再深入这个函数了,但可以肯定的是,它也不会将内存页读入页面。
总结以下,整个mmap流程实际上没有将页面读入内存,它甚至连映射都没有创建!它唯一分配的内核数据结构就是vma结构,用这个结构表示进程对内存的一种需求,但是内核不会立刻满足这个需求。当进程真正需要这些内存时,内核才会通过缺页中断满足这种需求。这体现里计算机中“懒加载”的思想。
3.4缺页中断源码浅析
1)do_page_fault
来看看看缺页中断的实现,它会为mmap“料理后事”,即真正地加载物理页面到内存。
内核中缺页中断的处理交由函数do_page_fault完成,首先它会错误地址从cr2寄存器中读出:
asmlinkage void __kprobes do_page_fault(struct pt_regs *regs,
unsigned long error_code)
{
int write, fault;
unsigned long address;
// ...
address = read_cr2(); // 页错误地址函数参数struct pt_regs *regs指向的是上下文保存的寄存器数值,error_code是硬件在引发缺页中断时保存的一个错误码,该错误码表示了硬件发生缺页中断的原因,详见《深入Linux内核架构》4.10节。
接着,do_page_fault调用find_vma查找用户进程有没有为发生缺页中的地址创建vma结构,其中find_vma函数能够查找vma->vm_end >= address的第一个vma结构:
vma = find_vma(mm, address);
if (!vma)
goto bad_area;
if (likely(vma->vm_start <= address))
goto good_area;
if (!(vma->vm_flags & VM_GROWSDOWN))
goto bad_area;
if (expand_stack(vma, address)) // 栈扩张
goto bad_area;如果没有相应的vma,则跳转到bad_area, 这将会发送sigv信号给当前进程,进程在返回用户态前会处理这个信号,默认行为是转储并终止进程。(关于信号的实现原理,可以参考我之前的博客)
如果找到了相应的vma,且vma的起始地址 <= address, 表示这个内存地址在堆上,那就跳转到good_area进行下一步操作。
如果找到相应的vma。且vma的起始地址 > address, 那么还要检擦vma的标志位有没有VM_GROWSDOWN,如果有则表示这是一个栈扩容操作,则调用expand_stack进行扩容,如果没有则跳转到bad_area结束进程。
接着看good_area的操作,首先它会对error_code进行检查,看看时什么原因引起了缺页中断,如果是写错误,且vma的flag也允许写,那么将write变量自增,表示有写错误引起的缺页中断。其他情况一律跳转到bad_area:
good_area:
info.si_code = SEGV_ACCERR;
write = 0;
switch (error_code & (PF_PROT|PF_WRITE)) {
default: /* 3: write, present */
case PF_WRITE: /* write, not present */
if (!(vma->vm_flags & VM_WRITE)) // 发生读错误,但是vma的flag没有设置写位
goto bad_area;
write++; // 写错误,且vma允许写
break;
case PF_PROT: /* read, present */
goto bad_area;
case 0: /* read, not present */
if (!(vma->vm_flags & (VM_READ | VM_EXEC | VM_WRITE)))
goto bad_area;
}最后调用handle_mm_fault进行进一步处理:
fault = handle_mm_fault(mm, vma, address, write);该函数会进一步调用handle_pte_fault,下一节将对该函数进行详细分析。
2)handle_pte_fault
前半段的源码如下所示:
static inline int handle_pte_fault(struct mm_struct *mm,
struct vm_area_struct *vma, unsigned long address,
pte_t *pte, pmd_t *pmd, int write_access)
{
pte_t entry;
spinlock_t *ptl;
entry = *pte;
if (!pte_present(entry)) { // p位置0
if (pte_none(entry)) { // 该页不在内存,也不在swap cache
if (vma->vm_ops) { // 基于文件的映射
if (vma->vm_ops->fault || vma->vm_ops->nopage)
return do_linear_fault(mm, vma, address,
pte, pmd, write_access, entry); // 将磁盘文件加载到内存
// ...省略一个处理函数do_no_pfn, 没有去研究了
}
// 匿名映射,为进程分配内存
return do_anonymous_page(mm, vma, address,
pte, pmd, write_access);
}
// 省略非线性映射的处理
// pte不为none,表示匿名页换出到了swap space中,此时pte_t 就能看成是swp_entry_t
// 则将swap space中的内容重新加载到内存
return do_swap_page(mm, vma, address,
pte, pmd, write_access, entry);
}
// 后面的代码包括COW的处理上面这段代码通过判断pte的p位以及pte是否为none进行不同的处理,可以再次对照这幅图看看它的处理逻辑:
这里我选择do_linear_fault再深入分析,该函数最终的效果时将文件从磁盘加载到内存:
static int do_linear_fault(struct mm_struct *mm, struct vm_area_struct *vma,
unsigned long address, pte_t *page_table, pmd_t *pmd,
int write_access, pte_t orig_pte)
{
// ...
return __do_fault(mm, vma, address, pmd, pgoff, flags, orig_pte);
}该函数进行一些检查后调用__do_fault:
static int __do_fault(struct mm_struct *mm, struct vm_area_struct *vma,
unsigned long address, pmd_t *pmd,
pgoff_t pgoff, unsigned int flags, pte_t orig_pte)
{
if (likely(vma->vm_ops->fault)) { // 调用fault
ret = vma->vm_ops->fault(vma, &vmf);
if (unlikely(ret & (VM_FAULT_ERROR | VM_FAULT_NOPAGE)))
return ret;
// ...可以看到它会直接调用vma的vm_ops->fault,是不是优点熟悉,该函数在mmap源码分析的时候见过,该函数指针将会在mmap_region函数中被设置为generic_file_vm_ops.fault:
struct vm_operations_struct generic_file_vm_ops = {
.fault = filemap_fault,
};filemap_fault函数将会根据vma将磁盘的文件内容载入内存制定的虚拟地址处,具体代码就不深入了。
/**
* filemap_fault - read in file data for page fault handling
* @vma: vma in which the fault was taken
* @vmf: struct vm_fault containing details of the fault
*
* filemap_fault() is invoked via the vma operations vector for a
* mapped memory region to read in file data during a page fault.
*/
int filemap_fault(struct vm_area_struct *vma, struct vm_fault *vmf)根据上一节mmap的分析,我们知道该vma是由mmap创建的,它表示了进程对内存的一种需求,终于到现在为止filemap_fault将会满足这个需求,mmap所余留的工作被补上了。
3.5写时复制
这一节简要说说写时复制,它在handle_pte_fault函数后半段:
static inline int handle_pte_fault(struct mm_struct *mm,
struct vm_area_struct *vma, unsigned long address,
pte_t *pte, pmd_t *pmd, int write_access)
{
//...
if (!pte_present(entry)) {
// 上一节的内容,处理匿名页和基于文件的页
}
// 如果pte的p位为1,但是触发了写错误,那么就有可能触发写时复制机制
if (write_access) {
if (!pte_write(entry))
return do_wp_page(mm, vma, address,
pte, pmd, ptl, entry);
}
// ...write_access在do_page_fault中设置,它会检查错误码,如果是因为写错误而发生缺页中断且对应的vma允许写的话,则write_access的值被设置成1。handle_pte_fault的代码再次判断pte项的可写位是否为0(!pte_write(entry)),如果是的话就会调用do_wp_page进行页面的复制。
可以看到,写实复制需要软件和硬件共同协作。软件需要将对应vma的flags设置为允许写,也要将pte的可写位置0,硬件只会对pte的可写位做检查,如果是0则触发缺页中断进入内核执行上面这段代码。
那么,“设置vma的flage为可写,pte不可写”是在哪里执行的呢?---在fork中,这也是Linux创建进程比较快的原因。
fork会把父进程的资源拷贝置子进程中,这些资源里就包括虚拟地址空间,但是fork并不会立刻就创建物理页并复制它们,而是使得父子进程共享虚拟地址空间所对应的物理页,并将这些页设为写保护,一旦父子进程的其中一个对物理页面执行写操作就会引发缺页中断,随后内核才会正真地复制物理页,父子进程在这之后才会“分家”。
具体代码对应于copy_one_pte中,该函数会将在do_fork的一系列函数调用中被调用:
static inline void
copy_one_pte(struct mm_struct *dst_mm, struct mm_struct *src_mm,
pte_t *dst_pte, pte_t *src_pte, struct vm_area_struct *vma,
unsigned long addr, int *rss)
{
// ...
/*
* If it's a COW mapping, write protect it both
* in the parent and the child
*/
if (is_cow_mapping(vm_flags)) {
ptep_set_wrprotect(src_mm, addr, src_pte);
pte = pte_wrprotect(pte);
}
// ...
}
static inline int is_cow_mapping(unsigned int flags)
{
return (flags & (VM_SHARED | VM_MAYWRITE)) == VM_MAYWRITE; // vma flags可写且不共享时为COW
}该函数名非常直观就是拷贝pte项,但是如果通过is_cow_mapping判断为COW机制,那么需要将父子进程的pte的可写标志置0。
实现的效果就是:如果父子进程都只是读取相关内存,那么各自相安无事,但只要其中的一个试图去修改\写入这些写保护的内存,就会触发缺页中断,接着内核就执行到了handle_pte_fault这个内核函数中,触发了写时拷贝机制。