解锁 PDF 文件:使用 JavaScript 和 Canvas 渲染 PDF 内容
最近研究了 Web 的 FileSystemAccess Api,它弥补了 Web 长期以来缺少的能力:操作用户设备中的文件;而如今通过这个 Api 我们能够实现常见的文件操作:创建、删除、修改、移动等。
研究 FileSystemAccess 与其他相关的知识,我才发现如今的 Web 不单单只是一个网页了,推翻了我以往对于 Web 的认知。
具体而言,PWA 能够让一个网站安装至用户设备,文件操作系统与 Storage Api 允许操作用户文件,Share Target 能够让我们将已安装网站设为指定文件格式的打开目标,这已经能够代替一些简单的文件处理程序了;对于性能,WebAssembly 也在不断发展中,目前缺少的只有文件访问权限的持久化,随着发展,相信未来一些处理文件的 Web 程序更多的会以桌面应用的形式存在,就如同 Excalidraw 一般。
也因此,萌生了研究 JS 中二进制操作的想法,这里以解析 PDF 为例,探讨研究对于 JS 中二进制操作的方式。
PDF 文档结构
特定类型的文件,它们的文件格式总是相同的,也就是说有通用的解析方法,PDF 文件也不例外。
一个 PDF 文档主要有以下 4 个部分:
- Header
- Body
- Xref
- Trailer
这 4 个部分共同组成了一个 PDF 文档。
Header
对于一个不可执行的文件来说,它的存在只是为了被读取,具体的行为是由解析器来决定的,而解析器为了知道当前文件是否能够被自己处理,就需要一个特定标识,这被称为 magic number,它通常存在于文件的头部,PDF 的标识被定义为 % PDF - 版本号,其中 % PDF 是固定的,对应的字节为 0x25``0x50``0x44``0x46。
在 Header 的下一行,通常会添加一些不可读的字节数据,这些数据是为了兼容传统文件传输程序,让它们知道当前文件是一个二进制文件。
Body
在 PDF 文档中,并没有一个标识 Body 区域的特征,它只是泛指 PDF 中的页面、资源、流等数据,这些数据被抽象为一个个对象,通过这些对象我们才能将 PDF 文档解析为可读的内容。
一个标准的对象格式为:
1 0 obj % 1 为对象编号,0 为对象版本号
<< >>
endobjXref(交叉引用表)
Xref 是 PDF 中存储对象偏移的区域,通过它我们能够快速的访问到指定的对象,而不必处理完整的文档,这意味着解析 PDF 文档是非常快的,举例来说,如果我们想要解析 PDF 中的第一个页面,首先获取到这个页面对象在 Xref 中的索引,然后根据存储的偏移位置访问到这个对象。
Xref 的表现形式如下:

Trailer
Trailer 位于文档尾部,其中的数据描述了如何读取当前文档,一个 PDF 解析器首先需要处理的就是这一部分的数据。
一个简单的 Trailer 如下:
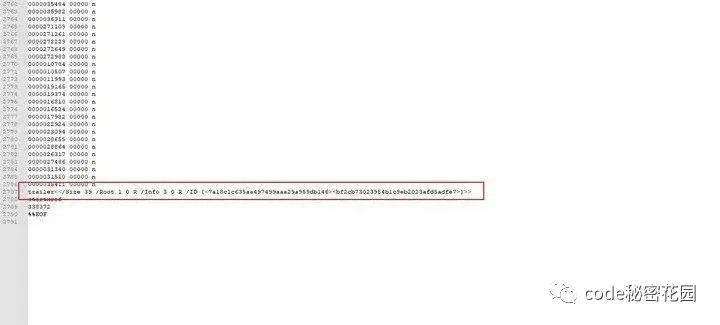
<<``>> 里,其中必须存在 Size 和 Root 属性,Size 标识着当前文档的对象个数,Root 是一个间接引用,指向了当前文档的文档目录,通过文档目录能够获取到页面信息,进而找到需要解析的页面。
在 trailer 的后面,通常跟着 startxref 的数据,这里存放了交叉引用表的位置偏移。

PDF 数据类型
PDF 为了方便数据的管理,定义了一些数据类型,分别有:
- 字典:包裹在
<<``>>中,其中的数据两两成对,一个为键一个为值,键必须是名称,值可以是任意类型,例如<< /Size 60 >>。 - 数组:包裹在
[ ]中,数组元素可以是任意类型。 - 间接引用:引用 PDF 中的对象,格式为 1 0 R,其中 1 为对象编号,0 为对象的版本号。
- 字符串:PDF 中,字符串有两种表现形式,一种被 () 包裹,其中内容可以是任意的字符,一种被
<>包裹,其中数据是 16 进制的字符串数字。 - 数字:整数和实数。
- 名称:以
/开始,如/Catalog,用于字典中的键或其他用途,名称通常映射了另一个实际的值。 - 布尔值:true | false。
- null:null 值。
PDF 中通常使用字典来描述当前对象的相关信息。
除了这些基本数据外,PDF 还存在着不可被解析为可读文本的流数据,通常用于存储图像、字体和压缩后的绘图指令,它的表现形式如下:
12 0 obj
<< >>
stream
% 流数据
endstream
endobjPDF Parser
了解了 PDF 文档的基本格式后,对于如何解析我们就有了一个概念,思路大概如下:
- 解析 Header,通过 magic number 判断当前文件是否是 PDF 文档。
- 从文件尾部读取,通过 startxref 记录交叉引用表的地址。
- 解析 trailer,并记录其中数据。
- 解析 xref,记录文档中对象的地址。
这些步骤执行完后,我们就能通过获取到的数据任意的访问需要的对象,并根据对象内容进行 PDF 页面的渲染。当然,在此之前我们需要先获取到文件数据。
获取文件数据
web 想要获取到文件,常用的方法就是 <input type="file" />,但其实它获取的只是一个类似指针的东西,并不存在真实的数据,在获取到文件指针后我们还需要通过 FileReader 将文件数据读取到内存,同时因为读出来的数据是一个 ArrayBuffer 实例,没有直观的数据形式,所以我们需要将他转换为 TypedArray 或 DataView,代码如下:
const getBufferView = (file: File) => {
return new Promise<Uint8Array>((resolve, reject) => {
const reader = new FileReader();
reader.onload = () => {
resolve(new Uint8Array(reader.result as ArrayBuffer));
};
reader.onerror = reject;
reader.readAsArrayBuffer(file);
});
};这里我们将文件读取后转换为了 Uint8Array 实例,之所以选择它,是因为 PDF 中可读数据都存在于 ASCII 码表中,而 8 位二进制所能表示的最大值是 255,足以表示 ASCII 码表中的所有数据。
这里我随便选择了一个 PDF 文档,打印出来的数据如下:
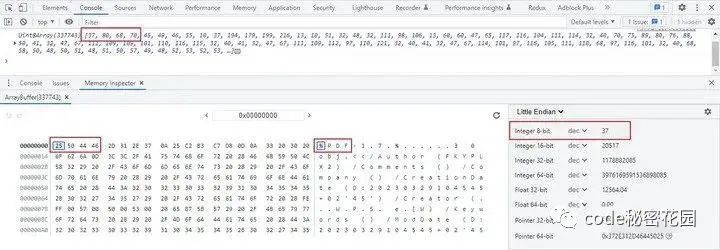
图片图片中,25 是一个 16 进制数值(两个 16 进制所能表示的最大值是 255,也就是一字节),转换为 10 进制为 37,在 ASCII 码表中对应的字符就是 %。
数据标识
虽然 PDF 中的一些辅助信息通常是可读的字符串,但通过字符串的方式解析这些信息是不可取的,因为字符串操作本身存在性能问题,而我们要处理的又是动辄数以万计的字节数据,所以这里我采用了直接对比字节数据的方式,为此我封装了一个工具函数:
const isTypeOf =
(binary: number[]) => (maybe: Uint8Array, offset?: number) =>
binary.every((correct, i) => correct === maybe[i + (offset || 0)]);这个工具函数接收一个字节标识,返回一个对比函数,对比函数通过对字节标识的按位对比来判断数据是否相等,需要注意的是对比函数还支持一个可选的字节偏移,指示应从数据的哪个位置开始对比。这个函数的使用如下:
const Flag = {
/** pdf magic number */
IS_PDF: [0x25, 0x50, 0x44, 0x46]
};
const isPDF = isTypeOf(Flag.IS_PDF);
isPDF(uint8); // PDF 的 magic number 位于文件的头部,偏移为 0,可以不用指定偏移数数据类型解析
PDF 中,trailer 和对象的描述信息都存在于字典中,而字典中又可能存在其他的 PDF 数据类型,因此只有能够解析它们,我们才能获取到其中的数据。
个人的思路是仿照 vue 对于模板字符串的解析一样,维护一个状态栈,不断的读取数据,当遇到标识的开头时,将特定的数据推入栈中,遇到标识的结尾时,将这个数据弹出,这样能够保证数据的层级,同时可以判断解析是否出错(遇到标识结尾时与状态栈顶进行对比)。
例如:在遇到字典开始的字节数据时([0x3c, 0x3c]),将表示字典的标识数据推入栈中,在遇到字典结束的字节数据时([0x3e, 0x3e]),将栈顶数据弹出并判断栈顶数据是否为字典标识。
相关代码如下:
/** 将 Uint8Array 解码为可读文本 */
const toText = (binary: Uint8Array) => new TextDecoder().decode(binary);
class PDFParser {
/** 被处理的文件数据 */
bytes: Uint8Array;
/** 字节偏移 */
offset = 0;
/** 缓存字节偏移,当解析不成功时回退偏移 */
beforeOffset = 0;
/** 数组解析深度 */
depth = 0;
/** 状态栈 */
stateStack: PDF.StateStack = [];
constructor(bytes: Uint8Array) {
/** 文件数据 */
this.bytes = bytes;
}
/** 字节偏移前进控制 */
forward(step?: number) {
return isNumber(step) ? (this.offset += step) : ++this.offset;
}
/** 字节偏移后退控制 */
back(step?: number) {
return isNumber(step) ? (this.offset -= step) : --this.offset;
}
/** 字节偏移设置 */
set(before: number) {
return (this.offset = before);
}
/** 缓存当前字节偏移 */
cache() {
this.beforeOffset = this.offset;
}
/** 回退字节偏移 */
reset() {
this.offset = this.beforeOffset;
}
/** 解析值 */
parseValue(stream: Uint8Array, decision?: ReturnType<typeof isTypeOf>) {
/** 数据开始 */
let startOffset = this.offset;
const isBreak = (bytes: Uint8Array, offset?: number) =>
decision
? !decision(bytes, offset)
: !isBreakPoint(bytes, offset) &&
!isEnd(bytes, offset) &&
!isStart(bytes, offset);
for (; ; this.forward()) {
/** 不为断点则视为数据开始 */
if (isBreakPoint(stream, this.offset)) continue;
/** 开始偏移 */
startOffset = this.offset;
for (; ; this.forward()) {
/** 为断点处或为特征数据结尾则视为数据结束 */
if (isBreak(stream, this.offset)) continue;
return stream.slice(startOffset, this.offset);
}
}
}
/** 解析数字 */
parseNumber(stream: Uint8Array) {
/** 缓存偏移 */
this.cache();
/** 解析值请判断是否为数字 */
const num = window.parseFloat(toText(this.parseValue(stream)));
if (!isNumber(num)) {
/** 不为数字则回退偏移 */
this.reset();
return false;
}
/** 否则返回数字 */
return num;
}
/** 解析引用:1 0 R */
parseQuote(stream: Uint8Array) {
/** 解析数字 */
const serial = this.parseNumber(stream);
/** 不为数字说明不是间接引用 */
if (!isNumber(serial)) return false;
/** 缓存偏移 */
this.cache();
/** 是否为数字,且后跟 R 标识 */
const version = window.parseFloat(toText(this.parseValue(stream)));
const isQuoteFlag = isQuote(this.parseValue(stream));
/** 不为数字或不存在 R 标识则回退偏移,并返回第一个数字 */
if (!isNumber(version) || !isQuoteFlag) {
this.reset();
return serial;
}
/** 返回间接引用 */
return { type: 'quote', serial, version } as const;
}
/** 解析数组 */
parseMultivalued(stream: Uint8Array) {
const values: unknown[] = [];
let value: unknown = undefined;
/** 解析引用或数字 */
const addQuote = () => {
value = this.parseQuote(stream);
value !== false && values.push(value);
};
/** 默认执行一次 */
addQuote();
/** 不为数组结束符号 ] 时执行循环体 */
while (!isSquareBracketEnd(stream, this.offset)) {
switch (true) {
/** 解析字典 */
case isDictionaryStart(stream, this.offset):
values.push(this.parseDictionary(stream));
break;
/** 解析数组 */
case isSquareBracketStart(stream, this.offset):
this.forward(Feature.SQUARE_BRACKET_START.length);
/** 解析深度加 一 */
this.depth++;
values.push(this.parseMultivalued(stream));
break;
/** 解析名称 */
case isInclined(stream, this.offset):
this.forward(Feature.INCLINED.length);
values.push({ type: 'name', value: toText(this.parseValue(stream)) });
break;
/** 解析字符串 */
case isArrowStart(stream, this.offset):
this.forward();
values.push(toText(this.parseValue(stream, isArrowEnd)));
break;
/** 解析字符串 */
case isParenthesesStart(stream, this.offset):
this.forward();
values.push(toText(this.parseValue(stream, isParenthesesEnd)));
break;
default:
this.forward();
addQuote();
break;
}
}
/** 递归解析数组, 如果解析深度不为 0, 则上层数组还需继续解析数组元素 */
if (this.depth !== 0) {
/** 字节偏移前进一位,避免上层数组解析到内部数组的 ] 符号而中止循环 */
this.forward(Feature.SQUARE_BRACKET_END.length);
this.depth--;
}
return values;
}
/** 解析字典 */
parseDictionary<T>(stream: Uint8Array): T {
/** 字典数据 */
const dictionary = {} as T;
/** 是否结束当前解析 */
let jumpOut = false;
/** 当前键 */
let key = '';
/** 顶部栈数据 */
const top = () => this.stateStack[this.stateStack.length - 1];
/** 状态栈弹出 */
const popStack = (key: PDF.StateStackKeys) => {
const topKey = this.stateStack.pop();
/** 顶部栈数据与当前数据不一致时,则解析出错 */
if (!isEqual(topKey, key)) {
throw Error(
'analyze the PDF error, please contact the plug -in developer'
);
}
};
/** jumpOut 在遇到字典结尾符号 >> 时会为 true,则停止循环解析 */
while (!jumpOut) {
switch (true) {
/** 字典开头 <<,字节为 [0x3c, 0x3c] */
case isDictionaryStart(stream, this.offset):
this.forward(Feature.DICTIONARY_START.length);
this.stateStack.push('DICTIONARY_START');
if (key !== '') {
// 递归字典解析
dictionary[key] = this.parseDictionary(this.bytes);
key = '';
}
break;
/** 字典结尾 >>,字节数据为 [0x3e, 0x3e] */
/** 可能是字符串与字典结尾 >>>,因此需要判断顶部栈是否是字典结尾 */
case isEqual(top(), 'DICTIONARY_START') &&
isDictionaryEnd(stream, this.offset):
this.forward(Feature.DICTIONARY_END.length);
popStack('DICTIONARY_START');
jumpOut = true;
break;
/** 数组开始 [,字节数据为 [0x5b] */
case isSquareBracketStart(stream, this.offset):
this.forward(Feature.SQUARE_BRACKET_START.length);
this.stateStack.push('SQUARE_BRACKET_START');
// 数组解析
dictionary[key] = this.parseMultivalued(stream);
key = '';
break;
/** 数组结束 ],字节数据为 [0x5d] */
case isSquareBracketEnd(stream, this.offset):
this.forward(Feature.SQUARE_BRACKET_END.length);
popStack('SQUARE_BRACKET_START');
break;
/** 名称 /,字节数据为 [0x2f] */
case isInclined(stream, this.offset):
this.forward(Feature.INCLINED.length);
/*
* 解析名称,需要注意的时,字典中的数据是两两成对的,键为名称,值也可以是名称,所以这里通过一个变量 key 缓存键,
* 当再次进入到当前代码块是判断 key 是否存在数据,存在则当前名称应作为值。
**/
if (key !== '' && key in dictionary && isUndef(dictionary[key])) {
dictionary[key] = {
type: 'name',
value: toText(this.parseValue(stream))
};
key = '';
} else {
key = toText(this.parseValue(stream));
/**
* 遇到名称时,如果这个名称没有被作为值使用,则会默认继续一次,如果解析的数据不为数字或引用,
* 则会回退字节偏移并继续循环解析。
*/
dictionary[key] = this.parseQuote(stream) || undefined;
}
break;
/** 16 进制字符串开始 <,字节数据为 [0x3c] */
case isArrowStart(stream, this.offset):
this.forward(Feature.ARROW_START.length);
this.stateStack.push('ARROW_START');
// 字符串解析
dictionary[key] = toText(this.parseValue(stream, isArrowEnd));
key = '';
break;
/** 16 进制字符串结束 >,字节数据为 [0x3e] */
case isArrowEnd(stream, this.offset):
this.forward(Feature.ARROW_END.length);
popStack('ARROW_START');
break;
/** 字符串开始 (,字节数据为 [0x28] */
case isParenthesesStart(stream, this.offset):
this.forward(Feature.PARENTHESES_START.length);
this.stateStack.push('PARENTHESES_START');
// 字符串解析
dictionary[key] = toText(this.parseValue(stream, isParenthesesEnd));
key = '';
break;
/** 字符串结束 ),字节数据为 [0x29] */
case isParenthesesEnd(stream, this.offset):
this.forward(Feature.PARENTHESES_END.length);
popStack('PARENTHESES_START');
break;
default:
/** 没有匹配时默认前进一位偏移 */
this.forward();
break;
}
}
/** 返回字典对象 */
return dictionary;
}
}上述代码虽然多,但基本操作都是相同的,只是不断的前进字节偏移并对匹配的数据做处理,需要注意的只是对于字节偏移的管理。
这里我们以 trailer 中的图片为例,它所解析出来的数据如下:
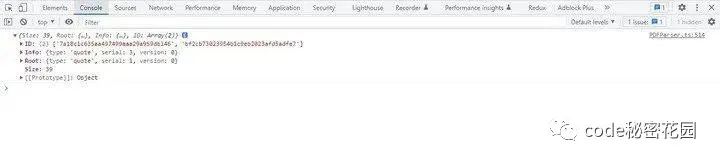
图片截图中,Root 对象的 type 属性是自定义的,表明这个对象是一个间接引用,serial 引用的对象编号,通常也可以看作是在交叉引用表中的索引,version 则是引用对象的版本号。
交叉引用表解析
到目前为止,我们只知道文档目录的对象编号(上文中 Root 的 serial 属性),而不知道文档目录所在的字节偏移,因此接下来我们需要解析交叉引用表,代码如下:
getPdfXref(stream: Uint8Array) {
// startxref 记录了交叉引用表所在的字节偏移
/** 设置偏移为 startxref + xref 的长度 */
this.set(this.startxref + Flag.XREF.length);
/** 解析对象开始编号 */
this.parseValue(stream);
/** 解析对象个数 */
let size = window.parseFloat(toText(this.parseValue(stream)));
while (size--) {
/** 解析对象偏移 */
this.xref.push(window.parseFloat(toText(this.parseValue(stream))));
/** 未知 */
this.parseValue(stream);
/** 标识 */
this.parseValue(stream);
}
}这里我们着重讲解下 parseValue 方法的作用,在 PDF 中,数据分割通常使用空格符、换行符来实现,parseValue 就是在不断的前进字节偏移中,找到不为分割符号的字节偏移,将其作为数据的开始,然后继续前进,当遇到分割符号时,将当前的字节偏移作用数据的结束,并将两个字节偏移中的数据切割出来。
使用上述代码对于 Xref 解析出来的数据如下:
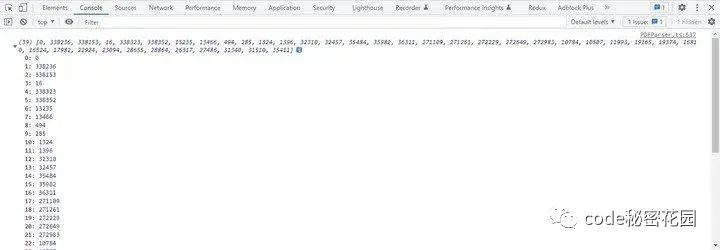
Catalog 与 Pages
在 trailer 中,Root 指向了文档目录,文档目录的基本格式如下:
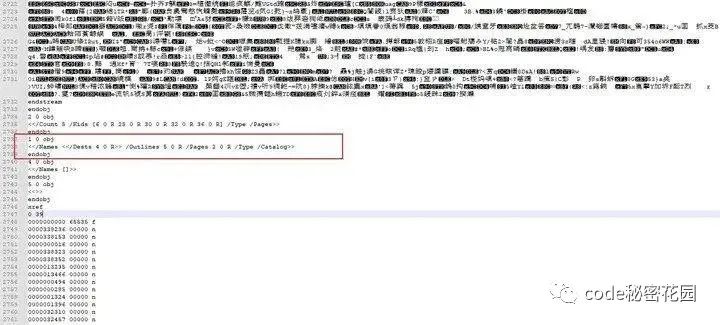
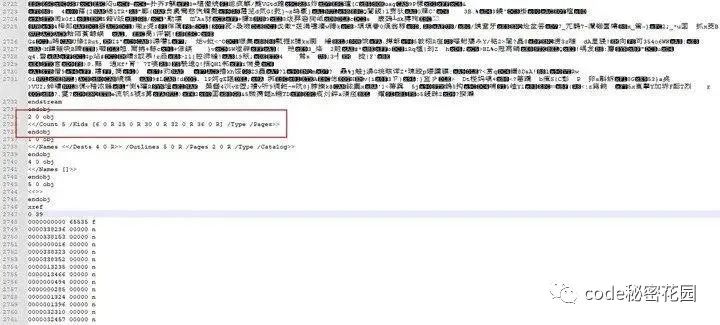
Pages 根节点对象的基本格式如下:
Canvas Draw
这里我们以上文中的第一个页面为例,讲解如何解析页面内容并绘制到 canvas 中。该页面的对象编号为 6,它的基本信息如下:

- Type:必须是 Page,表示当前对象是一个页面。
- Parent:指向父节点。
- Contents:指向内容对象,通常存放压缩后的绘图指令。
- Resources:页面的资源,如图形状态、字体、图片等。
解码绘图指令
上述页面的内容被存放在对象 7 中,它的基本信息如下:
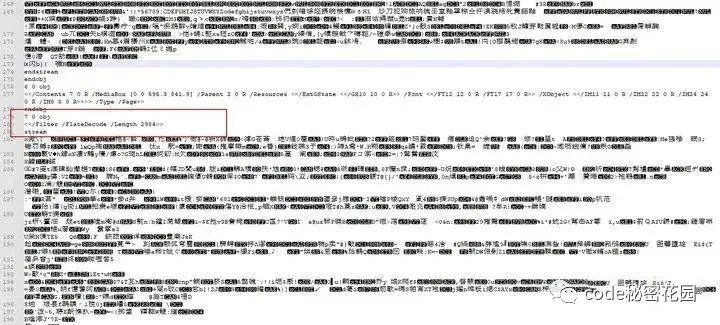
图片Filter 指示数据使用了什么压缩算法,Length 则表示压缩后数据的字节长度,在字典信息后,跟随着 stream 关键字,表示流数据的开始,endstream 则标识着流数据的结束。
对于压缩算法,个人不是很了解,所以这里使用了第三方类库 pako 来对流数据进行解压缩,上图中的流数据被解压后是可读的绘图指令,如下图:
绘制文档
接下来我们要做的事情就很明确了,我们只需要不断的读取绘图指令并使用 canvas 进行绘制,就可以将一个 PDF 文档展示出来了,但我们需要注意两者之间的差异:canvas 和 PDF 的坐标系是不同的,且 PDF 中使用的单位是 Point 而不是 Pixel。
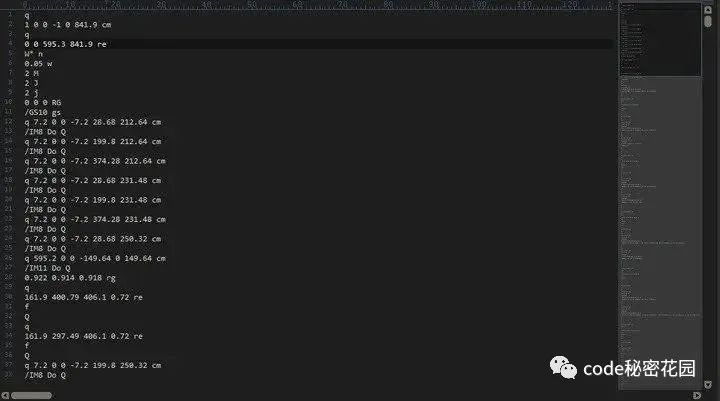
对于 PDF 中的绘图指令来说,它是后置位的,也就是说操作数在前,操作符在后,我们可以通过一个栈来维护其中的数据,以下图为例:
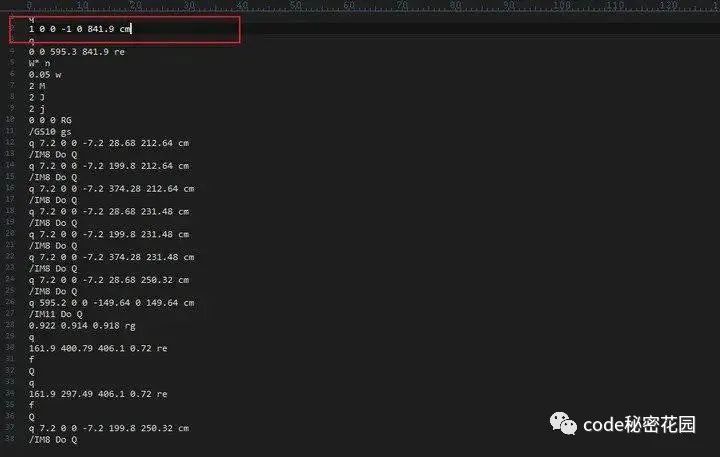
图片前面 6 个数值为操作数,cm 则是一个表示转换矩阵的操作符,当我们读取时,将数值依次压入栈中,当读取到 cm 指令时将栈中的数据依次出栈并作为指令的参数。
绘制图像
PDF 的 Do 操作符允许在当前位置输出一个外部对象,通常是一张图片,Do 操作符的入参是一个名称,这个名称映射了一个间接引用,通过引用可以知道它的字节偏移,从而解析相对应的图像数据并绘制到 canvas 中,注意,对于图像来说,必须在 onload 事件之后绘制到画布上,否则会无法显示。
解析文字
PDF 中,通常不会直接存储页面上的文本,而是转换为 Unicode 编码,并将其与另一个 Unicode 编码值相映射,在展示文本时,找到对应的字体对象,通过 ToUnicode 引用找到映射对象,解压其中的流数据就能找到实际的文字内容,如下图:
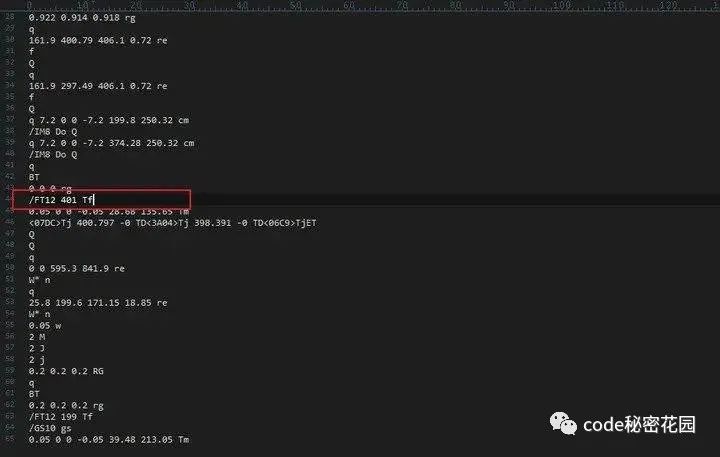
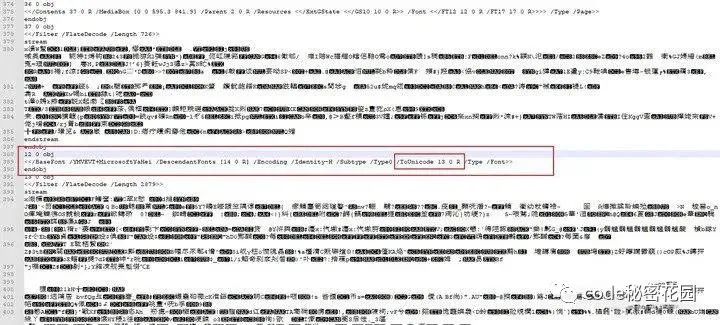

图片解压图中 obj 13 的流数据后会得到类似下图的数据:
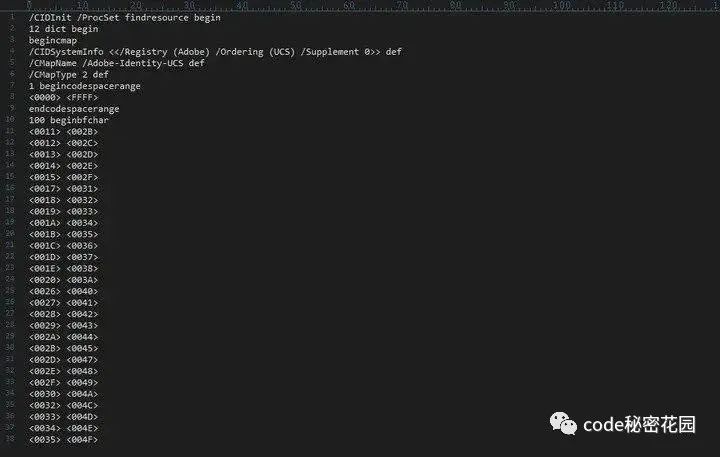
图片左侧的 16 进制字符串是在绘制指令中使用,右侧的 16 进制字符串才是真正的 Unicode 码值,可以通过 String.fromCodePoint 转换为文字内容。
示例
个人写了一个简单的 PDF 解析示例,因为对于绘图相关知识不是很懂,解析出来的位置,偏移还有转换等还有毛病,同时因为只是参照一两个 PDF 文件进行代码编写的,所以会有解析失败的情况,以下是个人简历解析出来的样式:
最后
- 本文作者:@yuanyxh
- 原文:https://zhuanlan.zhihu.com/p/631442533
参考:
- https://zxyle.github.io/PDF-Explained/
- https://blog.csdn.net/xzz/article/details/4447123
- https://blog.csdn.net/u012632138/article/details/81559375
- https://www.cnblogs.com/Primzahl/p/14735567.html
- https://www.cnblogs.com/warcraft/p/10998541.html
- https://www.cnblogs.com/adair-blog/p/14107894.html