最新多线程版 FFmpeg 剖析

FFmpeg近期推出了一个重要Feature,即将原来的 FFmpeg 命令行工具由单线程变成了多线程。
ffmpeg -i input.mp4 -c:v libx264 -crf 23 out.mp4如上面的命令,以前使用上面命令进行转码时,由于它是单线程工作模式,因此只能利用一个CPU内核。而现在改成多线程工作模式后,它可以充分利用你机子上的多个CPU内核,这可以大大加快转码的速度。

消息刚出来时,不少人以为FFmpeg将所有的编解码器都改成了多线程处理,这种显然是一种误读。
接下来,我们就来剖析一下此次FFmpeg对其转码逻辑做了哪些修改。
两种不同工作模式的比较
下面我们就来分析一下这两种工作模式有何不同。
单线程模式
首先我们来看一下FFmpeg转码工具在单线程模式下是如何进行工作的,其架构如下图所示:
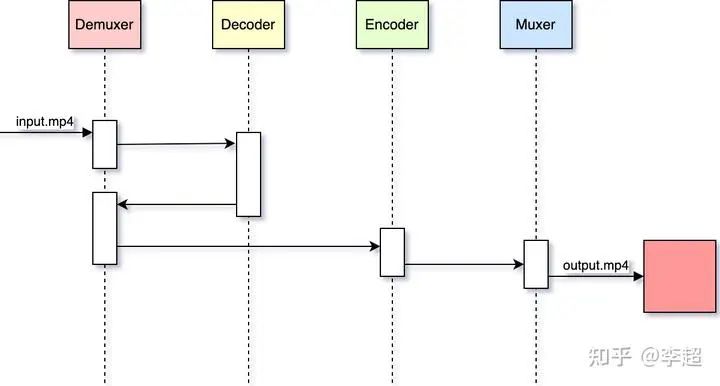
从图中可以看出,在转码时Demuxer首先读取输入文件,之后对其进行解复用,并取出一个个AVPacket发给解码器进行解码。
解码成功后,Demuxer再将解码后的AVFrame送编码器,编码器按照用户设置的编码参数对视频帧重新进行编码,最后交Muxer写到输出文件。
上面的整个操作过程都是单线程处理的,这种工作模式虽然对开发者来说降低了其开发难度,但却无法充分利用计算机的CPU资源。比如我们在一个32核的机子上进行转码的话,FFmpeg转码命令只能利用其中一个核,其它CPU资源都浪费了。
为了解决这个问题,各大厂通常的做法是自己开发一个调度程序,同时启动多个FFmpeg转码命令,这样才能将机子上多个CPU资源利用起来。
但这仍解无法解决一个重要的问题,即如果我们要转码的视频特别复杂,包括多个输入、输出文件时,它的转码时间会特别长。
如何解决这个问题呢?这次FFmpeg给出了解决方案,就是将转码命令由单线程改为多线程。
多线程模式
接下来,咱们再来看看最新版的多线程工作模式是如何工作的,其架构如下所示:
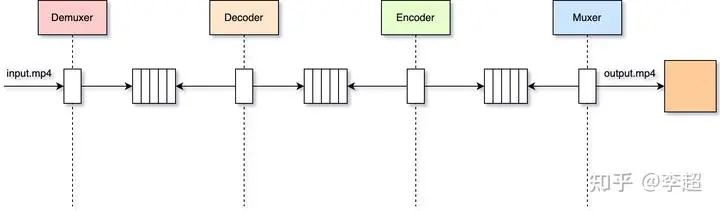
从图中我们可以看到,将FFmpeg转码命令改成多线程后,Demuxer、Decoder、Encoder、Muxer等每个模块都变成了一个独立的线程,线程与线程之间通过队列进行通信,这样就可以充分利用计算机中的CPU资源,缩短转码的时间了。
我们来举个具体的例子,假设我们使用下面的FFmpeg命令进行转码:
ffmpeg -i input.mp4 -c:v libx264 -crf 23 -c:a copy out.mp4<br></br>对于这个命令来说,它会同时启动一个Demuxer线程,一个视频Decoder线程、一个视频Encoder线程,一个Muxer线程。
首先Demuxer线程从input.mp4中读取音视频包,之后将视频包插入到视频Decoder线程队列中;
另一方面,Decoder线程一直在侦听其队列的变化,当发现队列中有数据时,就取出数据偿试解码,并在解码成功后,将其插入到视频编码线程的队列中;
同时,视频编码线程也在侦听着其队列的变化,当发现有数据时取出数据,对其进行编码,最后将编码好的数据插入到Muxer的视频处理队列中。
此外,当Demuxer线程读到音频包后,由于不需要重新进行编码,因此其会将音频包直接插入到Muxer线程的音频处理队列中。
最后,Muxer线程会分别从视频处理队列中和音频处理队列中取出音频包和视频包,并比较它们的时间戳大小,再根据其大小将数据包写入到输出文件out.mp4中,直至将所有的音视频数据处理完成为止。
通过上面的描述我们可以发现,由于转码过程中的每个处理步骤都是由单独的线程控制的,或者说都是并行处理的,因此这种工作模式可以充分利用计算机上的CPU资源,大大缩短处理单个多媒体文件的处理时间,大大提高了工作效率。
此外需要特别强调的是,如果转码命令中需要打开多个输入文件,那么对于每个输入文件会创建一个与之对应的Demuxer线程,以及Decoder线程,Encoder线程等,这一点我们一定要清楚。
代码剖析
下面我们就对新版FFmpeg代码做个简单的剖析,首先来看一下main函数:
int main(int argc, char **argv)
{
//调度器,用于线程的调度,
//包括解复用调度器、解码调度器、编码调度器、filter调度器、复用调度器等
Scheduler *sch = NULL;
...
//为调度器分配空间
sch = sch_alloc();
//分析命令行选项,并打开所有输入输出文件
ret = ffmpeg_parse_options(argc, argv, sch);
...
//进行转码操作
ret = transcode(sch);
...
//转码完成,释放空间
ffmpeg_cleanup(ret);
sch_free(&sch);
return ret;
}在main()函数中,新增了一个Scheduler类型的变量,该变量用于管理调度线程。它包括了复用调度器、解码调度器、编码调度器、filter调度器、复用调度器等,每个调度器里都包括一个线程任务(Task),用于处理具体的逻辑。
ffmpeg_parse_options(…)函数用于分析命令行中的参数,它将命令行中的参数分成三种类型组,即全局组,输入组及输出组。
其中全局组保存全局参数,如 -y;输入组保存输参数,如-i input.mp4,-c:v libx264等;输出组保存输出参数,如out.mp4。而且每种类型的组都可以有多个,如-i input.mp4,-c:v libx264表示有两个输入组。
ffmpeg_parse_options(…)函数除了要分析命令行参数外,它还需要根据分析出的结果打开输入、输出文件。同时根据输入、输出文件创建并初始化各种类型的Task。
其中初始化Task的一项重要工作是为Task绑定对应的处理函数,这里我对每种Task所绑定的处理函数做了整理,如下表所示:

transcode(…)函数主要的作用是调用sch_start(sch)将前面创建好的Task启动起来,也就是为每个Task启动一个线程,然后在线程中调用Task所绑写的处理函数。
到此,转码流程就运转起来了!
Scheduler结构
接下来咱们来看一下Scheduler结构中包括了哪些成员,代码如下:
struct Scheduler {
const AVClass *class;
SchDemux *demux; //解复用调度器指针,共指向解复用调度器数组的首地址
unsigned nb_demux; //解复用调度器个数,每个输入文件对应一个
SchMux *mux; //复用调度器指针,其指向复用调度器数组的首地址
unsigned nb_mux; //复用调度器个数,每个输出文件对应一个
unsigned nb_mux_ready; //记录有多少个复用调度器准备收接收数据了
pthread_mutex_t mux_ready_lock; //保护nb_mux_ready,避免多个线访问nb_mux_ready时产生突冲
unsigned nb_mux_done; //记录有多少个复用调度器完成了数据包的写入
pthread_mutex_t mux_done_lock; //用于保护 nb_mux_done 的锁
pthread_cond_t mux_done_cond; //用于保护 nb_mux_done 的条件变量
SchDec *dec; //解码调度器指针,其指向解码调度器数组的首地址
unsigned nb_dec; //解码调度器个数,每个解码器对应一个
SchEnc *enc; //编码调度器指针,其指向编码调度器数组的首地址
unsigned nb_enc; //编码调度器个数,每个编码器对应一个
SchSyncQueue *sq_enc; //专用于编码调度器与复用调度器的同步队列
unsigned nb_sq_enc;//同步队列个数
SchFilterGraph *filters; //FilterGraph调度器指针,其指向FilterGraph调度器的首地址
unsigned nb_filters;//filterGraph调度器个数,每个FilterGraph对应一个
char *sdp_filename; //SDP文件名,用于接收或发送RTP流
int sdp_auto; //是否在输出RTP流的目录下产生SDP文件
int transcode_started; //转码开始标记
atomic_int terminate; //转码结束标记
atomic_int task_failed; //任务失败标记
pthread_mutex_t schedule_lock; //锁
atomic_int_least64_t last_dts;
};上面就是Scheduler结构,它由demux、mux、dec、enc、sq_enc、filters等字段组成,其中每个字段我都做了详细注释,通过注释大家应该基本清楚每个字段的作用是什么了。
需要注意的是,对于demux、mux、dec等字段在结构中虽然看着只是一个指针,但实际上它是一个指向数组首地址的指针,而数组的个数是由其下面的nb_xxx来记录的。所以无论对于一条转码命令来说,其用到的demux、mux等调度器一般都会有多个,而每个都对应着一个线程。
Scheduler结构清楚之后,下面我们来看一下ffmpeg_parse_options( )函数是如何实现的。
ffmpeg_parse_options函数
ffmpeg_parse_options(…)是一个非常重要的函数,它的主要作用我在前面已经向你做了介绍,下面进入到这个函数中,看一下它具体是怎么做的吧。代码如下:
int ffmpeg_parse_options(int argc, char **argv, Scheduler *sch)
{
...
/* 解析命令行,并将解析的结果保存到octx结构中*/
ret = split_commandline(&octx, argc, argv, options, groups,
FF_ARRAY_ELEMS(groups));
...
/* 打开所有的输入文件 */
ret = open_files(&octx.groups[GROUP_INFILE], "input", sch, ifile_open);
...
/* 创建复杂的filterGraph,关于filterGraph的内容我们先不涉及,先抓主脉落 */
ret = init_complex_filters();
...
/* 打开所有输出文件 */
ret = open_files(&octx.groups[GROUP_OUTFILE], "output", sch, of_open);
if (ret < 0) {
errmsg = "opening output files";
goto fail;
}
...
fail:
/* 释放octx资源 */
uninit_parse_context(&octx);
...
return ret;
}在该函数中,首先调用split_commandline(...)函数解析命令行,并将解析的结果保存到octx结构中。如前面所述,在octx中会将命令行参数分为三种类型组,即全局组、输入组及输出组。
之后调用open_files(...)函数打开所有输入文件。对于octx.groups[GROUP_INFILE]存放的每个输入文件都调用ifile_open(…)进行处理。在ifile_open中会做以下几件事儿:
- 调用
sch_add_demux( )函数。在该函数中创建一个新的SchDemux对象,并将其插入到Scheduler的demux数组中,同时为SchDemux中的Task绑定input_thread函数; - 创建并填充avformat_context对象;
- 调用
avformat_open_input( )打开多媒体文件;
再下来调用init_complex_filters( )创建并初始化filterGraph,对这个函数我们就不展开讲解了,内容比较多,后面再单独介绍。最后调用open_files(...)函数打开所有输出文件。对于octx.groups[GROUP_OUTFILE]存放的每个输出文件都调用of_open(…)进行处理。
在of_open中会做以下几件事儿:
- 调用
avformat_alloc_output_context2( )函数分配上下文; - 调用sch_add_mux( )函数。在该函数中创建一个新的SchMux对象,并将其插入到Scheduler中的mux数组中,同时为SchMux中的Task绑定muxer_thread函数;
- 为输出文件创建输出流;
通过上面的分析我们可以总结出,ffmpeg_parse_options函数主要完成三件事儿,一是分析命令行参数,二是根据分析出的结果打开所有的输入与输出文件,三是为每个输入、输出文件创建SchDemux和SchMux对象,并初始化这两个对象中的Task,为之绑定线程处理函数。
transcode函数
最后我们来看一下transcode函数的实现,其代码如下:
static int transcode(Scheduler *sch)
{
...
/* 启动转码 */
ret = sch_start(sch);
...
/* 等待输出文件复用结束 */
while (!sch_wait(sch, stats_period, &transcode_ts)) {
...
}
/* 停止转码 */
ret = sch_stop(sch, &transcode_ts);
...
return ret;
}在transcode中主要做了三件事儿,其一调用sch_start( )启动Scheduler中的所有任务;其二调用sch_wait( )等待转码结束;其三调用sch_stop( )停止所有开启的任务。
在这三件事儿中,最为核心的是sch_start函数,它会对Scheduler中demux、dec、enc、filtert等字段做遍历,启动每一个任务。
也就是为每个任务启动一个线程,并在线程中调用在ffmpeg_parse_options中绑定好的处理函数。
测试结果
根据测试发现,如果我们只做一些简单的转码任务,如仅将一个输入文件转码成另一种输出文件,那么将FFmpeg命令由单线程改为多线程并不会带来什么好处。
其原因是,转码时占用资源最多的是音视频编解码,而默认情况下FFmpeg编解码已经采用了多线程来提高效率,因此无论FFmpeg命令改不改成多线程都不会有什么提升了。
但如果是一些复杂的转码任务,尤其是有多个输入、输出文件时,FFmpeg命令改成多线程后确实会对性能有一定的提升,必竟并行处理要比串行处理快,而且转码时的输入、输出文件越多,这种性能的提升就越明显。
小结
本文对新版FFmpeg命令行程序做了一个简单的分析,重点讲解了最新的多线程版与之前单线程版之间的区别,同时对其源码做了简单的剖析。
通过本文你应该知道老的FFmpeg存在那些问题,新版FFmpeg是如何解决该问题的。另外我们要清楚新版FFmpeg是如何使用多线程的,线程之间是如何交互的。
当然由于篇幅的原因,本文并没有将新版FFmpeg分析透,只是打开了一扇门。后面我们陆续推出一些文章对其做更深入的剖析。
参考资料
- 音视频入门与实战
- FFmpeg精讲