一种基于ODPS SQL的全局字典索引分布式计算思路

阿里妹导读
本文提供一种能充分利用分布式计算资源来计算全局字典索引的方法,以解决在大数据量下使用上诉方式导致所有数据被分发到单个reducer进行单机排序带来的性能瓶颈。
在一些业务场景中,我们需要将字符串映射为一个整形数字,并确保全局唯一,比如在BitMap字典索引计算场景。常用的方法是将数据集根据需要映射的字符串做全局order by排序,将排序号作为字符串的整形映射。该方式能达到目标,但如果一次要计算的数据量太大(十亿级别或更大),会跑耗时较久甚至跑不出来。
本文提供一种能充分利用分布式计算资源来计算全局字典索引的方法,以解决在大数据量下使用上诉方式导致所有数据被分发到单个reducer进行单机排序带来的性能瓶颈。
order by方式
sort_data数据集中id已经唯一,数据量级9.3亿,直接对数据集全局开窗排序写法如下:
INSERT OVERWRITE TABLE test_data_result
SELECT id
,ROW_NUMBER() OVER (ORDER BY id ASC ) AS rn
FROM test_data
;DAG图:
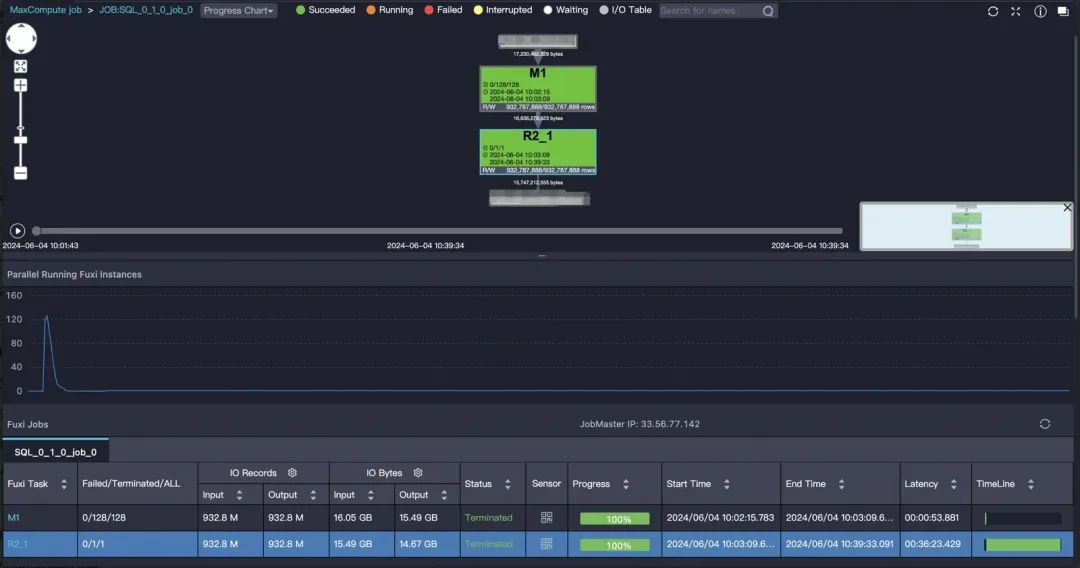
耗时30分钟,reducer只有一个,这里设置set odps.sql.reducer.instances=256是不起作用的,在这种方式下reducer只能有一个才能保证是全局唯一的。
分布式优化思路
大数据量下计算最忌讳的就是演变为单机计算,好一点的情况是跑很久,数据量再大可能直接跑不出来。如何利用计算资源水平扩展的优势来解决?思路是先做分桶进行分布式局部排序、再基于桶大小得到全局索引。类似于操作系统指令寻址的基址寻址,我们需要对每个id做绝对地址映射,利用一个基址加上相对地址得到绝对地址。
代码参考如下:
--第一步
WITH hash_bucket AS
(
SELECT id
,ROW_NUMBER() OVER (PARTITION BY bucket_no ORDER BY id ASC ) AS bucket_rel_index
,COUNT(1) OVER (PARTITION BY bucket_no ) AS bucket_size
,bucket_no
FROM (
SELECT id
,ABS(HASH(id)) % 100000 AS bucket_no
FROM test_data
)
)
--第二步
,bucket_base AS
(
SELECT bucket_no
,SUM(bucket_size) OVER (ORDER BY bucket_no ASC ) - bucket_size AS bucket_base
FROM (
SELECT DISTINCT bucket_no
,bucket_size
FROM hash_bucket
)
)
--第三步
INSERT OVERWRITE TABLE sort_data_result_1
SELECT /*+ MAPJOIN(t2) */
t1.id
,t2.bucket_base + bucket_rel_index AS id_index
FROM hash_bucket t1
JOIN bucket_base t2
ON t1.bucket_no = t2.bucket_no
;1.第一步先对id做hash分桶,然后计算每个桶的大小,桶数量可以根据需要计算的id数量来评估,这里分100000个桶,然后计算出每个id在桶内的相对位置bucket_rel_index,同时计算出桶大小bucket_size;2.第二步根据桶大小计算每个桶的基址;
3.第三步将桶基址+id在桶内的相对地址得到全局唯一的绝对地址id_index;
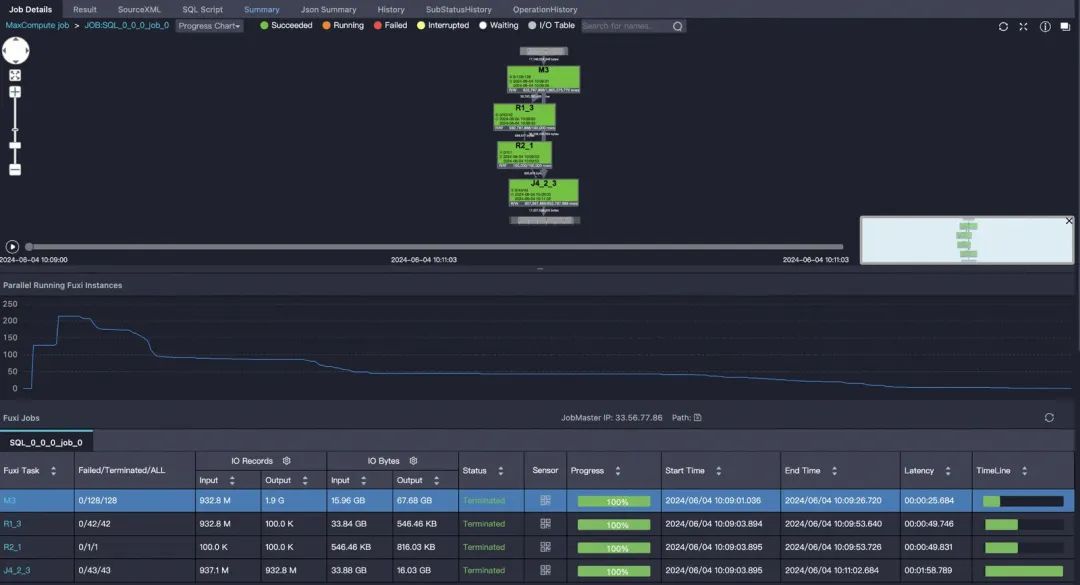
优化后避免了单机计算,耗时2分钟。
日常优化记录,也许并非最优,如有其他方式欢迎探讨。
随需而动:自动弹性,稳定交付
本方案使用应用型负载均衡(ALB)和弹性伸缩(ESS)智能分配网络流量、动态调整服务器资源,提高应用的高可用性和吞吐量,弹性控制资源利用率、缩减资源成本