JS程序设计的常用套路

阿里妹导读
亲尝百草,方知甘苦。套路,通常有助于提升代码的可读性、扩展性和效率。以下是作者工作中总结出来的一部分代码套路,分享给大家。
武侠小说里,往往有这样的场景,一少年被仇家追杀至绝境误入一山洞,偶然发现石壁上赫然刻着江湖失传已久的绝世武功,少年有着过目不忘的本领,将石壁上刻的一招一式牢牢记在了心中。还没等领悟其中奥妙,突然间洞穴开始晃动坍塌,山石崩裂,少年人侥幸逃出。后来隐姓埋名,勤学苦练,终于悟透了这绝世神功。满月临弓影,连星入剑端。十年一剑,破空而出,剑意万里,直冲霄汉。
在编程的世界里,大概可能也是这样的一个历程吧。在代码实践之前,读到教科书里的设计原则、模式、规范,可能往往不知所云。这时要做的,便是牢牢记住。纸上得来终觉浅,在之后数年的代码实践当中,每个人可能逐渐会形成自己的一个惯用套路,在解决实际问题时极为有效。而这些套路,实际就和那些理论融会贯通了。亲尝百草,方知甘苦。
套路,通常有助于提升代码的可读性、扩展性和效率。以下是我喜欢的一部分。
类型定义的套路
数据类型是值集和定义在这个值集上的一组操作的总称。通常来讲,数据类型确定了,代码的逻辑结构也便随之确定,两者互相成就,相辅相成。过往的编码经验表明,逻辑实现的困难程度和设计质量与数据类型之间存在很大相关性。选择合适的数据类型,可以简化逻辑,提升代码的扩展性和可读性。这种感觉非常像数据结构和算法之间的关系,虽然后者更倾向于影响计算机硬件的利用率和运行效率。
例子
例如下面这段代码片段,里面有多个魔法字符串出现,乍一看让人头大。我们知道,枚举(Enum)是一些常量的集合。
当代码中需要用到一些固定的常量却又晦涩难懂时,可以考虑使用枚举定义,来提高代码的可读性。
...
if (group === 'customer_free_group') {
list.push({
id: 'customer_free_cid',
Type: 'EQ',
bizType: 'customer_free',
});
} else if (group === 'customer_biz_group') {
list.push({
id: 'customer_biz_cid',
Type: 'AND',
bizType: 'customer_biz'
});
} else if (group === 'contact_group') {
list.push({
id: 'contact_cid',
Type: 'IN',
bizType: 'contact',
});
}
...使用枚举类型来定义这里的常量,类型定义一出来,仿佛代码逻辑就容易懂了一些:
enum GroupTypes {
customerFreeGroup = 'customer_free_group', // 免费客户组
customerBizGroup = 'customer_biz_group', // 收费客户组
contactGroup = 'contact_group', // 联系人组
}
enum LogicalOperationTypes {
EQ = 'EQ',
IN = 'IN',
AND = 'AND',
GT = 'GT',
LT = 'LT',
}
enum BizTypes {
customer_free = 'customer_free', // 免费客户
customer_biz = 'customer_biz', // 收费客户
contact = 'contact', // 联系人
}接着将原代码的魔法字符串改掉,改后的代码貌似可以透出一些帮助读者理解的信息了,可读性上有些进展。而且因为有了明确的命名和集中管理的地方,也方便后续的扩展:
...
if (group === GroupTypes.customer_free_group) {
list.push({
id: IdTypes.customer_free_cid,
type: LogicalOperationTypes.EQ,
bizType: BizTypes.customer_free,
});
} else if (group === GroupTypes.customer_biz_group) {
list.push({
id: IdTypes.customer_biz_cid,
type: LogicalOperationTypes.AND,
bizType: BizTypes.customer_biz,
});
} else if (group === GroupTypes.contact_group) {
list.push({
id: IdTypes.contact_cid,
type: LogicalOperationTypes.IN,
bizType: BizTypes.contact,
});
}
...接着,我们发现代码里出现了多次相似的代码结构。相似代码消除也有很多套路,使用合适的类型定义也是其中的一个。当我们在代码中觉察到相似的结构时,可能可以动一动映射表(Map)的心思了。先尝试将相似的代码结构定义到一个映射表里:
const groupConfigMap = {
customer_free_group: {
id: IdTypes.customer_free_cid,
type: LogicalOperationTypes.EQ,
bizType: BizTypes.customer_free,
},
customer_biz_group:{
id: IdTypes.customer_biz_cid,
type: LogicalOperationTypes.AND,
bizType: BizTypes.customer_biz,
},
contact_group: {
id: IdTypes.contact_cid,
type: LogicalOperationTypes.IN,
bizType: BizTypes.contact,
},
};定义好之后,接下来,主代码中的逻辑就会变成下面这样:
...
if (group in groupConfigMap) {
list.push(groupConfigMap[group]);
}
...当group在映射表中时,直接将对应的对象推入list数组。这使得代码更简洁且易于扩展。如果未来有新的group类型,只需添加到映射表即可。主代码逻辑部分从20行缩减到3行。虽然一目十行要求有些高,但一眼看过去三行应该是没问题。变身后的代码一目了然,简单清晰,读起来感觉真不错。
小结
如果条件分支主要基于某个键的值,可以考虑使用 映射表来存储对应的行为,这样可以将条件判断转换为简单的查找操作。通过使用枚举和映射表等数据类型将数据重新定义,可以将复杂逻辑简化,消减冗余代码,使代码更加简洁和易于维护。
函数提取的套路
在一个函数中可能出现多次分支和循环的逻辑结构,这可能导致一个函数过长,从而影响阅读体验。如果不加控制,可能将变得难以理解和维护。
这时我们可以考虑,将其中在多个地方重复或者负责特定任务的一段代码封装成一个新的函数。
函数式编程强调使用纯函数和不可变数据,最常见的是将业务逻辑和数据处理分开,数据处理部分很容易使用函数式编程。当然,新函数要符合单一职责原则,每个函数只做一件事。
例子
这是一个函数中的部分代码片段:
...
if (bizStatus === 'RUNNING') {
bizName = 'flow_in_approval';
} else if (bizStatus === 'COMPLETED') {
if (bizAction === 'modify') {
bizName = 'flow_modify';
} else if (bizAction === 'revoke') {
bizName = 'flow_revoke';
} else {
bizName = 'flow_completed';
}
} else {
bizName = 'sw_flow_forward';
}
...这段代码是通过BizStatus和BizAction的值来判断设置对应的bizName,逻辑相对独立,可以将其从几百行的原函数中抽出来,封装成一个新的函数getBizName。先用前面数据类型的套路整理一下,使用枚举来存放常量,并应用到代码中:
const BizStatus = {
RUNNING: 'RUNNING',
COMPLETED: 'COMPLETED',
};
const BizAction = {
MODIFY: 'modify',
REVOKE: 'revoke',
REFUSE: 'refuse'
};
const getBizName = (bizStatus:BizStatus, bizAction:BizAction)=>{
let bizName = '';
if (bizStatus === BizStatus.RUNNING) {
bizName = 'flow_in_approval';
} else if (bizStatus === BizStatus.COMPLETED) {
if (bizAction === BizAction.MODIFY) {
bizName = 'flow_modify';
} else if (bizAction === BizAction.REVOKE) {
bizName = 'flow_revoke';
} else {
bizName = 'flow_completed';
}
} else {
bizName = 'flow_forward';
}
return bizName;
}之后,原函数的位置变为了顺序结构。顺序结构是让人理解起来最轻松的一种结构了:
...
bizName = getBizName(bizStatus, bizAction);
...小结
如果一个函数本身过大,其中出现了多次分支结构和循环结构,可以考虑将每个分支结构或循环结构封装成新的函数。通过函数提取,可以逐步分解大而复杂的函数,将原函数中主流程尽量保持简单清晰的顺序结构。
通过新函数的合理命名,将极大的增强原函数的可读性和维护性。但是,看到getBizName这个函数,还会觉得哪里怪怪的。
那就要用到下面的分支逻辑处理的套路了,继续往下。
分支处理的套路
分支结构是程序设计中的常见的逻辑结构,它可以使程序根据不同的条件执行不同的代码。然而过度的分支可能导致代码难以理解和维护。
优化的分支逻辑,可以提高代码的可读性、可维护性和性能。卫语句(Guard Clause)是一种利用条件语句提前退出函数执行的编程风格,可以避免深层嵌套,使代码更扁平并尽早返回。
它常用的两个场景,一是在函数开头用来进行参数验证或条件检查,不合条件立即退出,避免继续执行剩余的代码。二是在函数的多个条件分支中,返回对应的值。
例子
继续使用上面未完的这段代码,我们将深度嵌套的条件通过逻辑运算合并成一个条件,避免条件的多层嵌套。再使用卫语句,使函数尽早返回,不需继续执行后续代码。这样代码更加简洁,易于理解。扩展功能时,也不需要深入嵌套去理解逻辑,修改起来更容易。
const getBizName = (bizStatus, bizAction) => {
if (bizStatus === BizStatus.RUNNING) {
return 'flow_in_approval';
}
if (bizStatus === BizStatus.COMPLETED && bizAction === BizAction.MODIFY) {
return 'flow_modify';
}
if (bizStatus === BizStatus.COMPLETED && bizAction === BizAction.REVOKE) {
return 'flow_revoke';
}
if (bizStatus === BizStatus.COMPLETED) {
return 'flow_completed';
}
return 'flow_forward';
};当然,这个例子稍微有点特别。你一定想它也可以使用类型定义的套路来处理试试。而这里bizStatus为COMPLETED时,也是可以考虑再次函数提取。这取决于要处理的代码的复杂度。
小结
简化合并条件表达式、卫语句、策略模式以及前面提到的映射表的方式是时常可以应到到分支逻辑处理中,来提高代码的可读性和可维护性的工具。流水不腐,户枢不蠹。代码常更新,工具也要常用。
变更封装的套路
在业务需求中,常常遇到一些需求经常发生调整的场景。例如新人引导步骤、菜单红点位置、功能性弹窗内容上线后需要多次修改等等。
那如何应对类似的需求变更呢?配置化是个很好用的工具。
配置化是将程序的配置信息存储在外部文件中的一种方法。通过设计,将配置和逻辑分离,在逻辑中实现配置驱动。这样,在需求变更时可以轻松地通过修改配置来达成目的,避免繁琐的代码修改和线上变更。
例子
例如这样一个新手任务的列表页面需求,向符合条件的新手展示任务列表,任务点击后页面会有多种行为:
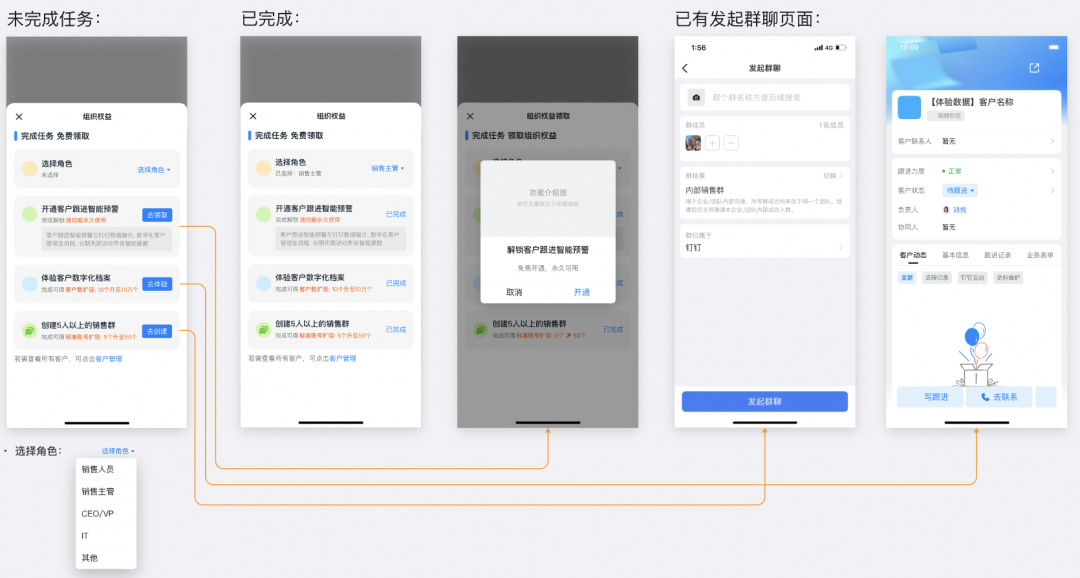
考虑到后续任务项可能发生变更,使用配置化来实现。先经过通用化抽象,明确能力要求,例如这个需求可描述为:
- 任务列表的任务不同时期会发生数量和内容的变化。
- 弹窗的内容和按钮点击后的行为会根据不同的任务发生变化。
- 任务列表页的按钮点击行为目前是这三种:打开弹窗、调用接口或JSAPI、打开新页面。
需求描述清楚后,再使用合适的数据类型定义来描述视图,将数据进行配置,定义例如:
interface ITaskModel {
key: string;
iconUrl: string;
title: string;
subTitle: IDescriptionModel[];
desc: IDescriptionModel[];
status: ITaskStatusEnum;
action: ITaskActionModel;
utParams: IUTParamsModel;
}
interface ITaskActionModel {
type: ITaskActionComponentType;
name: string;
targetConfig: IActionTargetModel;
}
interface IActionTargetModel {
type: ITaskActionType;
value: string;
targetConfig: IActionTargetModel;
}最后就是数据驱动的逻辑实现了。
小结
配置化可以看做是更大范围的类型定义套路的应用。它通常需要先将业务需求通过抽象转化为通用化需求,再使用合适的数据类型来定义数据,将业务逻辑和数据分离,来实现在需求变更时通过修改配置快速响应的目的。
篇幅关系更多的要留待下次更新,便借句话来结尾:输时不悲,赢时不谦。手中握剑,心中有义。见海辽远,就心生豪迈。见花盛开,不掩心中喜悦。
前路有险,却不知所畏。有友在旁,就想醉酒高歌。人间道理万卷书,但求随心随性行。
正值乱花渐欲迷人眼的好时节,不如约上三五好友出游,切莫负了这好时光。