使用懒加载 + 零拷贝后,程序的秒开率提升至99.99%
一、5秒钟加载一个页面的真相
今天在修改前端页面的时候,发现程序中有一个页面的加载速度很慢,差不多需要5秒,这其实是难以接受的,我也不知道为什么上线这么长时间了,没人提过这个事儿。
我记得有一个词儿,叫秒开率。
秒开率是指能够在1秒内完成页面的加载。
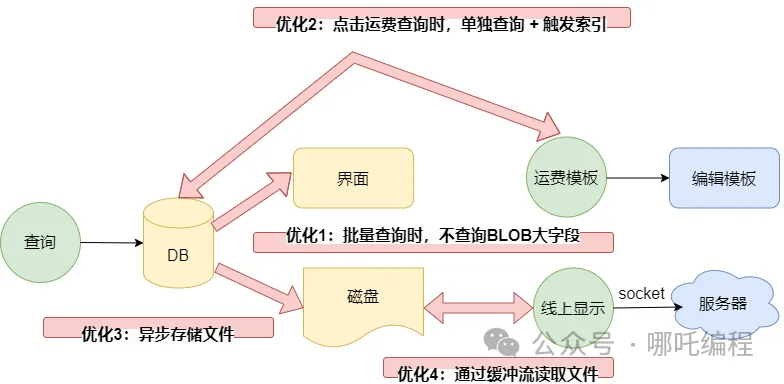
追踪代码,看看啥问题,最后发现问题有三:
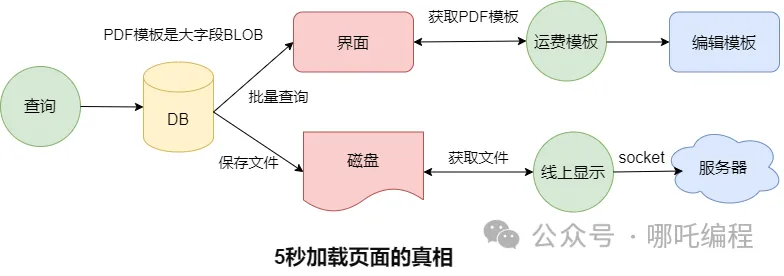
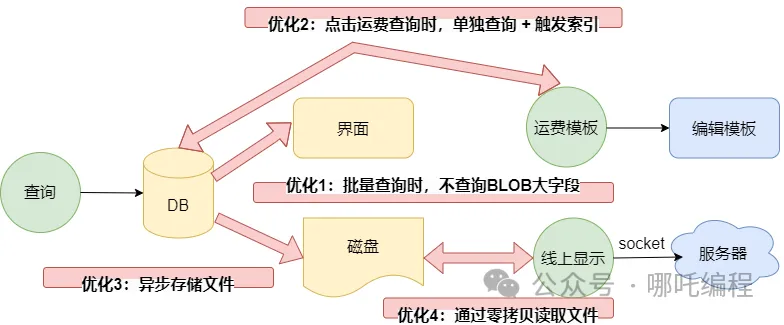
- 表中有一个BLOB大字段,存储着一个PDF模板,也就是上图中的运费模板;
- 查询后会将这个PDF模板存储到本地磁盘
- 点击线上显示,会读取本地的PDF模板,通过socket传到服务器。
大字段批量查询、批量文件落地、读取大文件并进行网络传输,不慢才怪,这一顿骚操作,5秒能加载完毕,已经烧高香了。
国内直接使用ChatGPT4o:
用官方一半价格的钱,用跟官方 ChatGPT4.0 一模一样功能的工具,而且不需要魔法,直接使用,不用担心网络问题。
国内直接使用ChatGPT4o:
- 无需魔法,同时支持电脑、手机,浏览器直接使用
- ChatGPT3.5永久免费,提供免费共享GPT3.5授权码
- 支持**Chat**GPT-4o文本对话、 Copilot编程、DALL-E AI绘画、AI语音对话等
长按识别下方二维码,备注ai,无需魔法,国内直接使用ChatGPT4o


二、优化四步走
1、“懒加载”
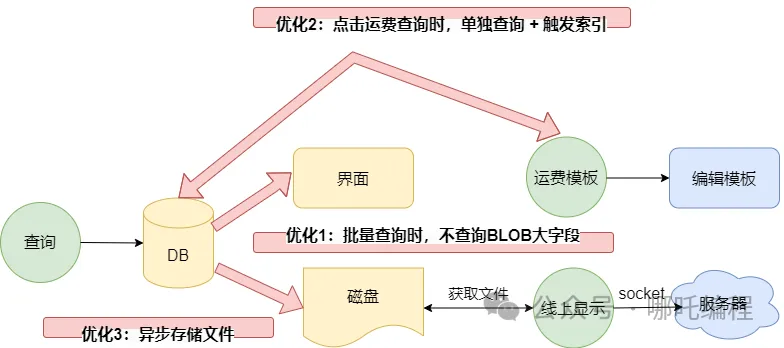
经过调查发现,这个PDF模板只有在点击运费模板按钮时才会使用。
- 优化1: 在点查询按钮时,不查询PDF模板;
- 优化2: 点击运费模板时,根据uuid去查询,这样既能触发索引,也不用按时间排序,只是查询单条,速度快了很多很多,我愿称你为“懒加载”。
- 优化3: 通过异步,将文件保存到磁盘中。
2、线上显示 = 就读取一个文件,为什么会慢呢?
打开代码一看,居然是通过FileReader读取的,我了个乖乖~
这有什么问题吗?都是从百度拷贝过来的,百度还会有错吗?而且也测试了,没问题啊。
嗯,对,是没问题,是可以实现需求,可是,为什么用这个?不知道。更别说效率问题了~
优化4:通过缓冲流读取文件
三、先从上帝视角,了解一下啥子是IO流
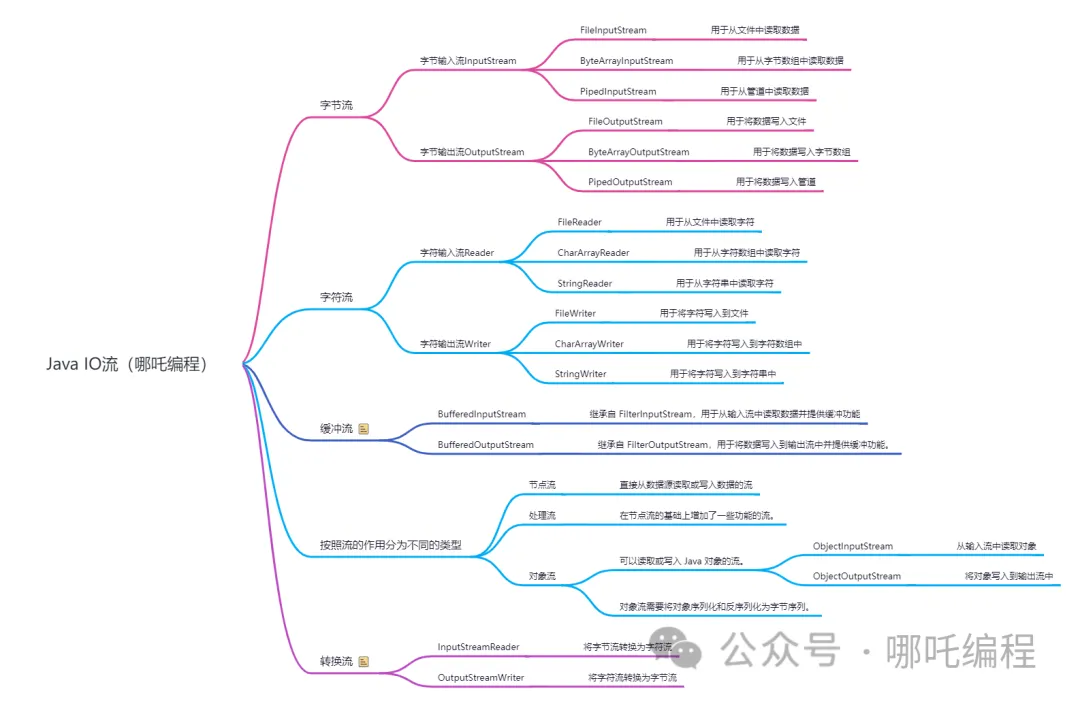
Java I/O (Input/Output) 是对传统 I/O 操作的封装,它是以流的形式来操作数据的。
- InputStream 代表一个输入流,它是一个抽象类,不能被实例化。InputStream 定义了一些通用方法,如 read() 和 skip() 等,用于从输入流中读取数据;
- OutputStream 代表一个输出流,它也是一个抽象类,不能被实例化。OutputStream 定义了一些通用方法,如 write() 和 flush() 等,用于向输出流中写入数据;
- 除了字节流,Java 还提供字符流,字符流类似于字节流,不同之处在于字符流是按字符读写数据,而不是按字节。Java 中最基本的字符流是 Reader 和 Writer,它们是基于 InputStream 和 OutputStream 的转换类,用于完成字节流与字符流之间的转换。
- BufferedInputStream 和 BufferedOutputStream 是 I/O 包中提供的缓冲输入输出流。它们可以提高 I/O 操作的效率,具有较好的缓存机制,能够减少磁盘操作,缩短文件传输时间。使用 BufferedInputStream 和 BufferedOutputStream 进行读取和写入时,Java 会自动调整缓冲区的大小,使其能够适应不同的数据传输速度。
- 可以读取或写入 Java 对象的流,比较典型的对象流包括ObjectInputStream 和 ObjectOutputStream,将 Java 对象转换为字节流进行传输或存储;
其中Buffered缓冲流就属于复用优化的一种,这个页面的查询完全可以通过复用优化优化一下。
四、写个栗子,测试一下
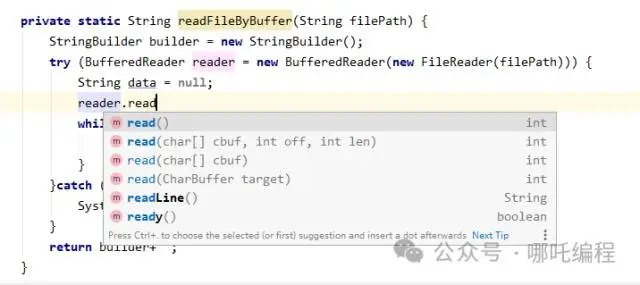
1、通过字符输入流FileReader读取
FileReader连readLine()方法都没有,我也是醉了~
private static int readFileByReader(String filePath) {
int result = 0;
try (Reader reader = new FileReader(filePath)) {
int value;
while ((value = reader.read()) != -1) {
result += value;
}
} catch (Exception e) {
System.out.println("readFileByReader异常:" + e);
}
return result;
}2、通过缓冲流BufferedReader读取
private static String readFileByBuffer(String filePath) {
StringBuilder builder = new StringBuilder();
try (BufferedReader reader = new BufferedReader(new FileReader(filePath))) {
String data = null;
while ((data = reader.readLine())!= null){
builder.append(data);
}
}catch (Exception e) {
System.out.println("readFileByReader异常:" + e);
}
return builder+"";
}通过循环模拟了150000个文件进行测试,FileReader耗时8136毫秒,BufferedReader耗时6718毫秒,差不多相差1秒半的时间,差距还是相当大的,俗话说得好,水滴石穿。
同样是read方法,只不过是包了一层,有啥不同呢?
BufferedReader 是一个缓冲字符输入流,可以对 FileRead 进行包装,提供了一个缓存数组,将数据按照一定规则读取到缓存区中,输入流每次读取文件数据时都需要将数据进行字符编码,而 BufferedReader 的出现,降低了输入流访问数据源的次数,将一定大小的数据一次读取到缓存区并进行字符编码,从而提高 IO 的效率。
如果没有缓冲,每次调用 read() 或 readLine() 都可能导致从文件中读取字节,转换为字符,然后返回,这可能非常低效。
就像取快递一样,在取快递的时候,肯定是想一次性的取完,避免再来一趟。
- FileReader就相当于一件一件的取,乐此不疲;
- BufferedReader就相当于,你尽可能多的拿你的快递,可是这也有个极限,比如你一次只能拿5件快递,这个 5 就相当于缓冲区,效率上,提升数倍。
对 FileRead 进行包装变成了BufferedReader缓冲字符输入流,其实,Java IO流就是最典型的装饰器模式,装饰器模式通过组合替代继承的方式在不改变原始类的情况下添加增强功能,主要解决继承关系过于复杂的问题,之前整理过一篇装饰器模式,这里就不论述了。
3、再点进源码瞧瞧。
(1)FileReader.read()源码很简单,就是直接读取
public int read(char cbuf[], int off, int len) throws IOException {
return in.read(cbuf, off, len);
}(2)BufferedReader.read()的源码就较为复杂了,看一下它的核心方法fill()
private void fill() throws IOException {
int dst;
if (markedChar <= UNMARKED) {
/* No mark */
dst = 0;
} else {
/* Marked */
int delta = nextChar - markedChar;
if (delta >= readAheadLimit) {
/* Gone past read-ahead limit: Invalidate mark */
markedChar = INVALIDATED;
readAheadLimit = 0;
dst = 0;
} else {
if (readAheadLimit <= cb.length) {
/* Shuffle in the current buffer */
System.arraycopy(cb, markedChar, cb, 0, delta);
markedChar = 0;
dst = delta;
} else {
/* Reallocate buffer to accommodate read-ahead limit */
char ncb[] = new char[readAheadLimit];
System.arraycopy(cb, markedChar, ncb, 0, delta);
cb = ncb;
markedChar = 0;
dst = delta;
}
nextChar = nChars = delta;
}
}
int n;
do {
n = in.read(cb, dst, cb.length - dst);
} while (n == 0);
if (n > 0) {
nChars = dst + n;
nextChar = dst;
}
}核心方法fill():
- 字符缓冲输入流,底层有一个8192个元素的缓冲字符数组,当缓冲区的内容读完时,将使用 fill() 方法从硬盘中读取数据填充缓冲数组;
- 字符缓冲输出流,底层有一个8192个元素的缓冲字符数组,使用flush方法将缓冲数组中的内容写入到硬盘当中;
- 使用缓冲数组之后,程序在运行的大部分时间内都是内存和内存直接的数据交互过程。内存直接的操作效率是比较高的。并且降低了CPU通过内存操作硬盘的次数;
- 关闭字符缓冲流,都会首先释放对应的缓冲数组空间,并且关闭创建对应的字符输入流和字符输出流。
既然缓冲这么好用,为啥jdk将缓冲字符数组设置的这么小,才8192个字节?
这是一个比较折中的方案,如果缓冲区太大的话,就会增加单次读写的时间,同样内存的大小也是有限制的,不可能都让你来干这个一件事。
很多小伙伴也肯定用过它的read(char[] cbuf),它内部维护了一个char数组,每次写/读数据时,操作的是数组,这样可以减少IO次数。
(3)buffer四大属性
- mark:标记
- position:位置,下一个要被读或写的元素的索引, 每次读写缓冲区数据时都会改变改值, 为下次读写作准备
- limit:表示缓冲区的当前终点,不能对缓冲区 超过极限的位置进行读写操作。且极限 是可以修改的
- capacity:容量,即可以容纳的最大数据量;在缓 冲区创建时被设定并且不能改变。
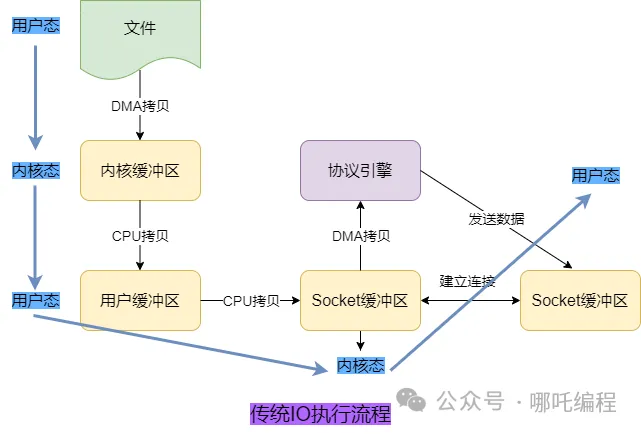
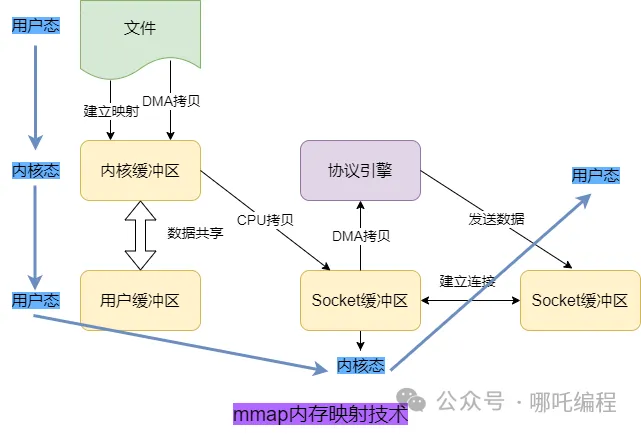
4、缓冲流:4 次上下文切换 + 4 次拷贝
传统 IO 执行的话需要 4 次上下文切换(用户态 -> 内核态 -> 用户态 -> 内核态 -> 用户态)和 4 次拷贝。
- 磁盘文件 DMA 拷贝到内核缓冲区
- 内核缓冲区 CPU 拷贝到用户缓冲区
- 用户缓冲区 CPU 拷贝到 Socket 缓冲区
- Socket 缓冲区 DMA 拷贝到协议引擎。
五、NIO之FileChannel
NIO中比较常用的是FileChannel,主要用来对本地文件进行 IO 操作。
1、FileChannel 常见的方法有
- read,从通道读取数据并放到缓冲区中;
- write,把缓冲区的数据写到通道中;
- transferFrom,从目标通道 中复制数据到当前通道;
- transferTo,把数据从当 前通道复制给目标通道。
2、关于Buffer 和 Channel的注意事项和细节
- ByteBuffer 支持类型化的put 和 get, put 放入的是什么数据类型,get就应该使用 相应的数据类型来取出,否则可能有 BufferUnderflowException 异常;
- 可以将一个普通Buffer 转成只读Buffer;
- NIO 还提供了 MappedByteBuffer, 可以让文件直接在内存(堆外的内存)中进 行修改, 而如何同步到文件由NIO 来完成;
- NIO 还支持 通过多个 Buffer (即 Buffer 数组) 完成读写操作,即 Scattering 和 Gathering。
3、Selector(选择器)
- Java 的 NIO,用非阻塞的 IO 方式。可以用一个线程,处理多个的客户端连 接,就会使用到Selector(选择器);
- Selector 能够检测多个注册的通道上是否有事件发生,如果有事件发生,便获取事件然 后针对每个事件进行相应的处理。这样就可以只用一个单线程去管理多个 通道,也就是管理多个连接和请求。
- 只有在 连接/通道 真正有读写事件发生时,才会进行读写,就大大地减少了系统开销,并且不必为每个连接都创建一个线程,不用去维护多个线程。
- 避免了多线程之间的上下文切换导致的开销。
4、selector的相关方法
- open();//得到一个选择器对象
- select(long timeout);//监控所有注册的通道,当其 中有 IO 操作可以进行时,将 对应的 SelectionKey 加入到内部集合中并返回,参数用来 设置超时时间
- selectedKeys();//从内部集合中得 到所有的 SelectionKey。
六、内存映射技术mmap
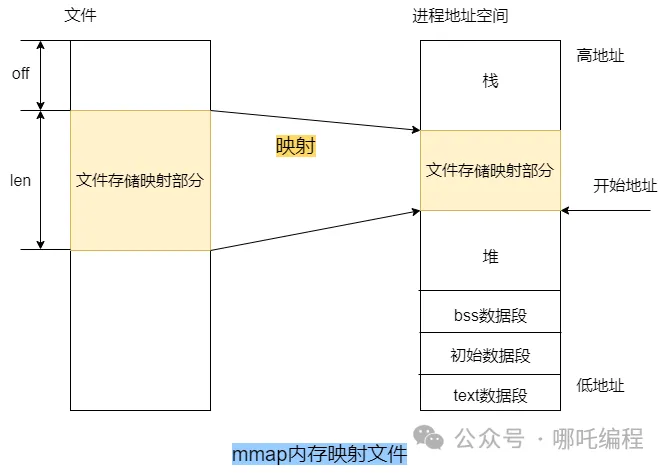
1、文件映射
传统的文件I/O操作可能会变得很慢,这时候mmap就闪亮登场了。
mmap(Memory-mapped files)是一种在内存中创建映射文件的机制,它可以使我们像访问内存一样访问文件,从而避免频繁的文件I/O操作。
使用mmap的方式是在内存中创建一个虚拟地址,然后将文件映射到这个虚拟地址上,这个映射的过程是由操作系统完成的。
实现映射后,进程就可以采用指针的方式读写操作这一段内存,系统会自动回写到对应的文件磁盘上,这样就完成了对文件的读取操作,而不用调用 read、write 等系统函数。
内核空间对这段区域的修改也会直接反映用户空间,从而可以实现不同进程间的文件共享。
2、Java中使用mmap
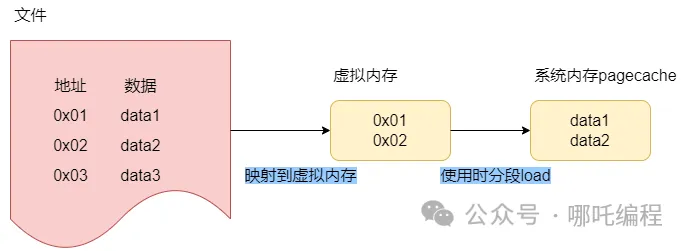
在 Java 中,mmap 技术主要使用了 Java NIO (New IO)库中的 FileChannel 类,它提供了一种将文件映射到内存的方法,称为 MappedByteBuffer。MappedByteBuffer 是 ByteBuffer 的一个子类,它扩展了 ByteBuffer 的功能,可以直接将文件映射到内存中。
根据文件地址创建了一层缓存当作索引,放在虚拟内存中,使用时会根据的地址,直接找到磁盘中文件的位置,把数据分段load到系统内存(pagecache)中。
public static String readFileByMmap(String filePath) {
File file = new File(filePath);
String ret = "";
StringBuilder builder = new StringBuilder();
try (FileChannel channel = new RandomAccessFile(file, "r").getChannel()) {
long size = channel.size();
// 创建一个与文件大小相同的字节数组
ByteBuffer buffer = ByteBuffer.allocate((int) size);
// 将通道上的所有数据都读入到buffer中
while (channel.read(buffer) != -1) {}
// 切换为只读模式
buffer.flip();
// 从buffer中获取数据并处理
byte[] data = new byte[buffer.remaining()];
buffer.get(data);
ret = new String(data);
} catch (IOException e) {
System.out.println("readFileByMmap异常:" + e);
}
return ret;
}3、内存映射技术mmap:4 次上下文切换 + 3 次拷贝
mmap 是一种内存映射技术,mmap 相比于传统的 缓冲流 来说,其实就是少了 1 次 CPU 拷贝,变成了数据共享。
虽然减少了一次拷贝,但是上下文切换的次数还是没变。
因为存在一次CPU拷贝,因此mmap并不是严格意义上的零拷贝。
RocketMQ 中就是使用的 mmap 来提升磁盘文件的读写性能。
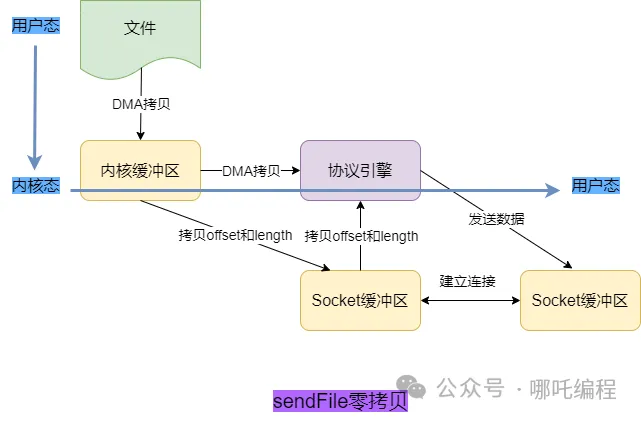
七、sendFile零拷贝
零拷贝将上下文切换和拷贝的次数压缩到了极致。
1、传统IO流
- 将磁盘中的文件拷贝到内核空间内存;
- 将内核空间的内容拷贝到用户空间内存;
- 用户空间将内容写入到内核空间内存;
- socket读取内核空间内存,将内容发送给第三方服务器。

2、sendFile零拷贝
在内核的支持下,零拷贝少了一个步骤,那就是内核缓存向用户空间的拷贝,这样既节省了内存,也节省了 CPU 的调度时间,让效率更高。
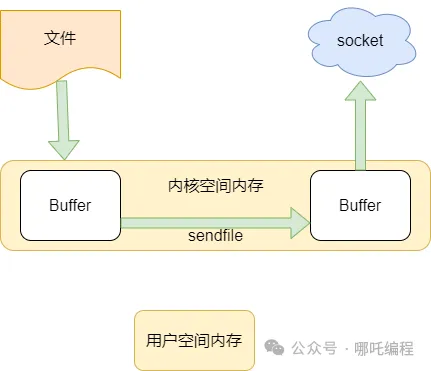
3、sendFile零拷贝:2 次上下文切换 + 2次拷贝
直接将用户缓冲区干掉,而且没有CPU拷贝,故得名零拷贝。
重置优化4:通过零拷贝读取文件
八、总结
经过4次优化,将页面的加载时间控制在了1秒以内,实打实的提升了程序的秒开率。
- 批量查询时,不查询BLOB大字段;
- 点击运费查询时,单独查询+触发索引,实现“懒加载”;
- 异步存储文件
- 通过 缓冲流 -> 内存映射技术mmap -> sendFile零拷贝 读取本地文件;
通过一次页面优化,收获颇丰:
- 通过业务优化,将BLOB大字段进行“懒加载”;
- 异步存储文件;
- 系统的学习了Java IO流,输入输出流、字符流、字符流、转换流;
- 通过NIO的FileChannel读取文件时,较于缓冲流性能上显著提升;
- 内存映射技术mmap 相比于传统的 缓冲流 来说,其实就是少了 1 次 内核缓冲区到用户缓冲区的CPU 拷贝,将其变成了数据共享;
- sendFile零拷贝,舍弃了用户空间内存,舍弃了CUP拷贝,完美的零拷贝方案。
- 通过代码实例,横向对比了FileReader、BufferedReader、NIO之FileChannel、内存映射技术mmap、sendFile零拷贝之间的性能差距;