JDK11 与 JDK8 特性差异浅谈
1.1 基于嵌套的访问控制
如果你在一个类中嵌套了多个类,各类中可以直接访问彼此的私有成员。
因为 JDK11 开始在 public 、protected 、private 的基础上,JVM 又提供了一种新的访问机制:Nest
我们先来看下 JDK11 之前的如下案例:
class Outer {
private int outerInt;
class Inner {
public void test() {
System.out.println("Outer int = " + outerInt);
}
}
}在 JDK11 之前 执行编译的最终结果的 class 文件形式如下:
class Outer {
private int outerInt;
public int access$000() {
return outerInt;
}
}
class Inner$Outer {
Outer outer;
public void test() {
System.out.println("Outer int = " + outer.access$000());
}
}以上方案虽然从逻辑上讲,内部类是与外部类相同的代码实体的一部分,但它被编译为一个单独的类。因此,它需要编译器创建合成桥接方法,以提供对外部类的私有字段的访问。
这种方案一个很大的坑是反射的时候会有问题。
当使用反射在内部类中访问外部类的私有成员 outerInt 时会报 IllegalAccessError 错误。这个是让人不能理解的,因为反射还是源码级访问的权限。
class Outer {
private int outerInt;
class Inner {
public void test() throws Exception {
System.out.println("Outer int = " + outerInt);
// JDK 11 之前,如下代码报出异常:IllegalAccessException
Class c = Outer.class ;
Field f = c.getDeclaredField("outerInt");
f.set(Outer.this, 23);
}
}
public static void main(String[] args) throws Exception {
new Outer().new Inner().test();
}
}JDK11 开始,嵌套是一种访问控制上下文,它允许多个 class 同属一个逻辑代码块,但是被编译成多个分散的 class 文件,它们访问彼此的私有成员无需通过编译器添加访问扩展方法,而是可以直接进行访问,如果上述代码可以直接通过反射访问外部类的私有成员,而不会出现权限问题,请看如下代码:
class Outer {
private int outerInt;
class Inner {
public void test() throws Exception {
System.out.println("Outer int = " + outerInt);
// JDK 11 之后,如下代码不会出现异常
Class c = Outer.class ;
Field f = c.getDeclaredField("outerInt");
f.set(Outer.this, 23);
}
}
public static void main(String[] args) throws Exception {
new Outer().new Inner().test();
}
}1.2 Java 平台级模块系统
Java9 的定义功能是一套全新的模块系统。当代码库越来越大,创建复杂,盘根错节的“意大利面条式代码”的几率呈指数级的增⻓。这时候就得面对两个基础的问题:很难真正地对代码进行封装,而系统并没有对不同部分(也就是 JAR 文件)之间的依赖关系有个明确的概念。每一个公共类都可以被类路径之下任何其它的公共类所访问到,这样就会导致无意中使用了并不想被公开访问的 API 。此外,类路径本身也存在问题:你如何知晓所有需要的 JAR 都已经有了,或者是不是会有重复的项呢?模块系统把这俩个问题都给解决了。
模块化的 JAR 文件都包含一个额外的模块描述器。在这个模块描述器中,对其它模块的依赖是通过 “ requires ” 来表示的。另外“ exports ”语句控制着哪些包是可以被其它模块访问到的。所有不被导出的包默认都封装在模块的里面。
Java 平台本身也使用自己的模块系统进行了模块化。通过封装 JDK 的内部类,平台更安全,持续改进也更容易。
以下是 Java9 平台级模块系统的优势:
- 代码内聚,容易维护:模块化可以帮助开发人员在构建、维护和改进软件系统(尤其是大型系统)时提高工作效率。
- 降低复杂度:模块化在包之上提供更高层次的聚合,使得代码更易于理解和管理。
- 提供更好的伸缩性和扩展性:模块化使得 JavaSE 程序更加容易轻量级部署,改进了组件间的依赖管理。
- 改进性能和安全性:模块中的包只有在模块显式导出时可供其他模块访问,即使如此,其他模块也无法使用这些包,除非它明确指出它需要其他模块的功能。由于潜在攻击者只可以访问较少的类别,因此提高了平台的安全性。
- 更佳的平台完整性:在 Java9 之前,您可以使用平台中许多不预期供应用使用的类别,通过强封装,这些内部API真正会被封装并隐藏在使用该平台的应用中。
- 可扩展的 Java 平台:现在,平台被模块化为 95 个模块(此数字可能随着 Java 的发展而变化),您可以创建定制运行时,其中仅包含应用所需的模块或目标设备。
1.3 JShell(交互式 Java REPL)
JDK9 中的 JShell 让 Java 具有交互式编程环境。现在可以从控制台启动 JShell ,并直接启动输入和执行 Java 代码。JShell 的即时反馈使它成为探索 API 和尝试语言特性的好工具。
jshell> int a = 5;
a ==> 5
jshell> int b = 10;
b ==> 10
jshell> System.out.println("The sum of " + a + " and " + b + " is " + sum);
The sum of 5 and 10 is 151.4 根证书颁发认证
根证书是一种特殊的证书,它在公开密钥基础设施( PKI )中,起着信任链的起点的角色。根证书是属于根证书颁发机构( CA )的公钥证书,这个机构的角色有如现实世界中的公证行,保证网络世界中电子证书持有人的身份。
具体来说,根证书是用来签发其他证书的,它自己的签发者就是它本身。许多应用软件(例如操作系统、网页浏览器)会预先安装可被信任的根证书,这代表用户授权了应用软件代为审核哪些根证书机构属于可靠。
OpenJDK 和 OracleJDK 在 JDK9 之前处理根证书方面有所不同,这会影响到它们的构建过程。通过改进根证书的颁发和认证,可以使 OpenJDK 对开发人员更具吸引力,并减少 OpenJDK 和 OracleJDK 构建之间的差异。
1.5 私有接口方法
JDK8 为我们带来了接口的默认方法。接口现在也可以包含行为,而不仅仅是方法签名。但是,如果在接口上有几个默认方法,代码几乎相同,会发生什么情况?通常,您将重构这些方法,调用一个可复用的私有方法。但默认方法不能是私有的。将复用代码创建为一个默认方法不是一个解决方案,因为该辅助方法会成为公共 API 的一部分。使用 JDK9 ,您可以向接口添加私有辅助方法来解决此问题。如果您使用默认方法开发 API ,那么私有接口方法可能有助于构建其实现。
1.6 增强的 try-with-resources
这是 JDK9 中引入的一项新特性,称为 " 增强的 try-with-resources "。在 JDK7 中引入的原始 try-with-resources 语句要求您在 try 语句中声明和初始化一个或多个资源。这些资源在 try 代码块结束时自动关闭。
然而,在 JDK9 中,如果您已经有一个资源是 final 或等效于 final 变量,您可以在 try-with-resources 语句中使用该变量,而无需在 try-with-resources 语句中声明一个新变量。
例如,以下是 JDK7 的 try-with-resources 语句:
try (BufferedReader br = new BufferedReader(new FileReader(path))) {
return br.readLine();
}在 JDK9 中,如果 br 已经被声明并初始化,那么你可以这样写:
BufferedReader br = new BufferedReader(new FileReader(path));
try (br) {
return br.readLine();
}在 JDK9 中增强的 try-with-resources 语句中,当 try 代码块执行完毕后,系统会自动调用资源对象的 close() 方法来关闭资源。这就是为什么我们使用 try-with-resources 语句,它可以帮助我们自动管理资源,避免因忘记关闭资源而导致的资源泄露问题。
如果你试图再次从 br 读取数据,将会抛出 IOException
1.7 实施 ChaCha20 和 Poly1305 加密算法
ChaCha20 是一种相对较新的流密码,可以取代旧的、不安全的 R4 流密码。ChaCha20 将与 Poly1305 验证器配对。
ChaCha20 和 Poly1305 加密算法在许多场景中都有应用,特别是在需要数据加密和数据完整性验证的场合。以下是一些具体的应用场景:
- 网络通信安全:ChaCha20 和 Poly1305 经常一起使用,形成了被广泛应用的 ChaCha20-Poly1305 加密方案。例如,Google 选择了伯恩斯坦设计的,带 Poly1305 消息认证码的 ChaCha20 ,作为 OpenSSL 中 RC4 的替代品,用以完成互联网的安全通信。Google 最初实现了 HTTPS (TLS/SSL) 流量在 Chrome 浏览器( Android 手机版)与 Google 网站之间的通信。
- 软件性能优化:由于 ChaCha20-Poly1305 在没有硬件加速的情况下,通常比 AES-GCM 有更快的软件性能,因此在需要高性能加密的软件中,ChaCha20-Poly1305 是一个很好的选择。
- 数据完整性验证:Poly1305 可以用作一次性消息认证码,用于验证单个消息的完整性和真实性,隐藏单个消息的内容。
1.8 局部变量 var 类型推断
在 JDK10 中引入的 var 关键字,允许编译器根据变量的初始赋值来推断出它的类型。这种类型推断可以使代码更简洁,提高代码的可读性。
var rs = "itheima";
System.out.println(rs);
就等于:
String rs = "itheima"局部变量推断对于较复杂的类型也有很好的简化作用,如下是对Map集合的遍历方式的简化:
public class Demo01 {
public static void main(String[] args) {
Map<String,Integer> maps = new HashMap<>();
// 1.添加元素:添加键值对元素
maps.put("iphoneX" , 1);
maps.put("huawei" , 8);
maps.put("Java" , 1);
/*
Set<Map.Entry<String, Integer>> entries = maps.entrySet();
for(Map.Entry<String,Integer> entry : entries){
String key = entry.getKey();
Integer value = entry.getValue();
}
*/
var entries = maps.entrySet();
for(var entry : entries){
String key = entry.getKey();
Integer value = entry.getValue();
}
}
}在 JDK11 中,var 关键字可以用于 lambda 表达式的参数。这意味着我们可以在 lambda 表达式的参数上添加注解。例如,我们可以使用 @Deprecated 注解来标记一个参数已经被废弃或不推荐使用。
需要注意的是,如果在lambda表达式中使用了 var 来声明参数,那么所有的参数都必须使用 var 来声明。
List<Integer> nums = new ArrayList<>();
Collections.addAll(nums , 9 , 10 , 3 );
nums.sort((@Deprecated var o2 , @Deprecated var o1) -> o2 - o1);var 局部变量语法注意事项:
- 不可以直接
var a;,因为无法推断。 - 类的属性的数据类型不可以使用 var 。
- var 不同于 js ,类型依然是静态类型,var 不可以在 lambda 表达式中混用。
(var a, b) -> a + b1.9 String 新增处理方法
如以下所示,JDK11 新增了一些对于 String 的处理方法。
// 判断字符串是否为空白
System.out.println(" ".isBlank()); // true
// 去除首尾空白
System.out.println(" itheima ".strip()); // 可以去除全角的空白字符
System.out.println(" itheima ".trim()); // 不能去除全角的空白字符
// 去除尾部空格
System.out.println(" itheima ".stripTrailing());
// 去除首部空格
System.out.println(" itheima ".stripLeading());
// 复制字符串
System.out.println( "itheima".repeat( 3 )); // itheimaitheimaitheima
// 行数统计
System.out.println("A\nB\nC".lines().count()); // 3 ;1.10 集合新增的 API
集合( List / Set / Map )都添加了 of 和 copyOf 方法,它们两个都用来创建不可变的集合。
// List的增强api
List<String> list = List.of("aa", "bb", "cc", "dd");
// Set的增强api
Set<Integer> set1 = Set.of(100, 30, 20, 15);
// Map的增强api
Map<String, Integer> map = Map.of("a", 1, "b", 2, "c", 3);使用 of() 方法创建的集合,为不可变集合,不能进行添加、删除、替换、排序等操作, 不然会报 java.lang.UnsupportedOperationException 异常。
// 把List集合转换成数组
// JDK 11 前的方式
Integer[] nums 1 = list.toArray(new Integer[ 0 ]);
// JDK 11 开始之后新增方式
Integer[] nums 2 = list.toArray(Integer[]::new);takeWhile:从集合开头提取符合条件的元素
public void test2() {
List<Integer> res = Stream.of( 1, 2, 3, 4, 0, 1 )
.takeWhile( n -> n < 4 )
.collect( Collectors.toList() );
}dropWhile:从集合开头移除前符合条件的元素
public void test3() {
List<Integer> res = Stream.of( 1, 2, 3, 4, 0, 1 )
.dropWhile( n -> n < 4 )
.collect( Collectors.toList() );
}1.11 Optional 新增的 API
Optional.orElseThrow():如果值存在,返回包含的值,否则抛出 NoSuchElementException 。
Optional<String> optional = Optional.of("java");
optional.orElseThrow(); // 返回 "java"Optional.stream():如果值存在,返回一个包含值的 Stream,否则返回一个空的 Stream 。
Optional<String> optional = Optional.of("java");
optional.stream().count(); // 返回 1Optional.or(Supplier):如果值存在,返回包含的值,否则返回从指定 Supplier 接口生成的值。
Optional<String> optional = Optional.ofNullable(null);
optional.or(() -> Optional.of("java")).get(); // 返回 "java"1.12 更方便的 IO
此前我们需要使用 Paths.get() 。现在,我们像其他类一样使用 of() 。
of(String, String...)writeString(Path, CharSequence) 我们可以使用该方法来保存一个 String 字符串。
Files.writeString(Path.of("test.txt"), "Hello!!!")
readString(Path) 我们可以使用该方法来读取一个 String 字符串。readString(Path) 我们可以使用该方法来读取一个 String 字符串。
Files.readString(Path.of("test.txt"), StandardCharsets.UTF_8);- nullReader() 使用该方法,我们可以得到一个不执行任何操作的 Reader 。
- nullWriter() 使用该方法,我们可以得到一个不执行任何操作的 Writer 。
- nullInputStream() 使用该方法,我们可以得到一个不执行任何操作的 InputStream 。
- nullOutputStream() 使用该方法,我们可以得到一个不执行任何操作的 OutputStream 。
- InputStream 还终于有了一个非常有用的方法:transferTo ,可以用来将数据直接传输到 OutputStream ,这是在处理原始数据流时非常常见的一种用法,如下示例:
try (var is = Demo01.class.getResourceAsStream("dlei.txt");
var os = new FileOutputStream("stream01.txt")) {
is.transferTo(os); // 把输入流中的所有数据直接自动地复制到输出流中
}1.13 Java HTTP 客户端
从 JDK9 开始引入了一个处理 HTTP 请求的的 HTTP Client API,不过当时一直处于孵化阶段,而在 JDK11 中已经为正式可用状态,作为一个标准API提供在java.net.http供大家使用,该 API 支持同步和异步请求,取代繁琐的 HttpURLConnection 的请求。
以下是 HTTP Client 的用法:
同步请求:
// 1 .创建HttpClient对象。
var client = HttpClient.newHttpClient();
// 2 .创建请求对象:request,封装请求地址和请求方式get.
var request = HttpRequest.newBuilder()
.uri(URI.create("http://api.com:8899/?appkey=10003&format=json"))
.GET().build();
// 3 .使用HttpClient对象发起request请求。得到请求响应对象response
HttpResponse<String> response = client.send(request, HttpResponse.BodyHandlers.ofString());
// 4 .得到响应的状态码信息
System.out.println(response.statusCode());
// 5 .得到响应的数据信息输出
System.out.println(response.body());异步请求:
// 1 .创建HttpClient对象。
var client = HttpClient.newHttpClient();
// 2 .创建请求对象:request,封装请求地址和请求方式get.
var request = HttpRequest.newBuilder()
.uri(URI.create("http://api.com:8899/?appkey=10003&format=json"))
.GET().build();
// 3 .使用HttpClient对象发起request异步请求。得到请求响应对象future
CompletableFuture<HttpResponse<String>> future =
client.sendAsync(request, HttpResponse.BodyHandlers.ofString());
// 4 .监听future对象的响应结果,并通过join方法进行异步阻塞式等待。
future.whenComplete((resp,ex) - > {
if(ex != null ){
ex.printStackTrace();
} else{
System.out.println(resp.statusCode());
System.out.println(resp.body());
}
}).join();1.14 Unicode10
目标:升级现有平台的 API ,支持 Unicode10 ,Unicode10 的标准请参考网站(http://unicode.org/versions/Unicode10.0.0)
目前支持最新的 Unicode 的类主要有
java.lang 包下的 Character、String
java.awt.font 下的相关类
java.text 包下的 Bidi、Normalizer 等
String 对 Unicode 的示例:
System.out.println("\uD83E\uDD93");
System.out.println("\uD83E\uDD92");
System.out.println("\uD83E\uDDDA");
System.out.println("\uD83E\uDDD9");
System.out.println("\uD83E\uDDD1");
System.out.println("\uD83E\uDDD8");
System.out.println("\uD83E\uDD95");
System.out.println("\uD83E\uDD2e");1.15 改进 Aarch64 函数
改进现有的字符串和数组函数,并在 Aarch64 处理器上为 java.lang.Math 下的 sin 、cos 和 log 函数实现新的内联函数。从而实现专用的 CPU 架构下提高应用程序的性能。
代码示例:
public static void main(String[] args) {
long startTime = System.nanoTime();
for(int i = 0 ; i < 10000000 ; i++ ){
Math.sin(i);
Math.cos(i);
Math.log(i);
}
long endTime = System.nanoTime();
// JDK 11 下耗时:1564 ms
// JDK 8 前耗时:10523 ms
}1.16 更简化的编译运行程序
增强 Java 启动器支持运行单个 Java 源代码文件的程序。
- JDK11 中,通过 java xxx.java 命令,就可直接运行源码文件程序,而且不会产生 .class 文件。
- 一个 Java 文件中包含多个类时,java xxx.java 执行排在最上面的一个类的 main 方法。
- java xxx.java 启动单个 Java 源代码文件的程序时,相关个类必须定义在同一个 Java 文件中。
JDK11 之前 :
javac Test.java
java TestJDK11 :
java Test.java1.17 Epsilon 垃圾收集器
Epsilon :无操作垃圾收集器( Epsilon :A No-Op Garbage Collector )
Epsilon 垃圾收集器主要用途
- 性能测试:EpsilonGC 可以帮助开发者理解在没有垃圾收集的情况下,工作负载的运行速度会有多快。
- 内存压力测试:使用 EpsilonGC ,开发者可以观察应用程序在内存压力下的表现。
- 虚拟机接口测试:EpsilonGC 可以用于测试和验证虚拟机的接口。
- 极短生命周期的任务:对于生命周期非常短的程序,使用 EpsilonGC 可以避免在程序结束时进行无用的垃圾收集。
- 极致的延迟改进:在某些对延迟特别敏感的情况下,使用 EpsilonGC 可以帮助减少延迟。
- 极致的吞吐量改进:在某些对吞吐量特别敏感的情况下,使用 EpsilonGC 可以帮助提高吞吐量。
需要注意的是,EpsilonGC 并不回收任何内存,一旦 Java 堆内存耗尽,JVM 将会关闭。因此,它并不适合用于常规的生产环境。在使用 EpsilonGC 时,需要确保可用的堆内存足够应用程序运行所需。
使用 Epsilon 垃圾收集器
UnlockExperimentalVMOptions :解锁隐藏的虚拟机参数
-XX:+UnlockExperimentalVMOptions -XX:+UseEpsilonGC -Xms100m -Xmx100m如果使用选项 -XX:+UseEpsilonGC ,程序很快就因为堆空间不足而退出。
运行程序后,结果如下:
Terminating due to java.lang.OutofMemoryError: Java heap space会发现很快就内存溢出了,因为 Epsilon 不会去回收对象。
1.18 ZGC 可伸缩低延迟垃圾收集器
ZGC 全称是 Z Garbage Collector ,ZGC 的设计目标是:支持TB级内存容量,暂停时间低( <10ms ),对整个程序吞吐量的影响小于 15% 。
应用程序同时为数千甚至数百万用户提供服务的情况并不少见。这些应用程序需要大量内存。但是,管理所有内存可能会轻易影响应用程序性能。为了解决这个问题,JDK11 引入了 Z垃圾收集器( ZGC )作为实验性垃圾收集器( GC )实现。
GC术语
为了理解 ZGC 如何匹配现有收集器,以及如何实现新 GC ,我们需要先了解一些术语。最基本的垃圾收集涉及识别不再使用的内存并使其可重用。现代收集器在几个阶段进行这一过程,对于这些阶段我们往往有如下描述:
- 并行:在 JVM 运行时,同时存在应用程序线程和垃圾收集器线程。并行阶段是由多个 GC 线程执行,即 GC 工作在它们之间分配。不涉及 GC 线程是否需要暂停应用程序线程。
- 串行:串行阶段仅在单个 GC 线程上执行。与之前一样,它也没有说明 gc 线程是否需要暂停应用程序线程。
- STW:STW 阶段,应用程序线程被暂停,以便 GC 执行其工作。当应用程序因为 GC 暂停时,这通常是由于 Stop The World 阶段。
- 并发:如果一个阶段是并发的,那么 GC 线程可以和应用程序线程同时进行。并发阶段很复杂,因为它们需要在阶段完成之前处理可能使工作无效。
- 增量:如果一个阶段是增量的,那么它可以运行一段时间之后由于某些条件提前终止,例如需要执行更高优先级的 GC 阶段,同时仍然完成生产性工作。增量阶段与需要完全完成的阶段形成鲜明对比。
工作原理
为了实现其目标,ZGC 给 Hotspot Garbage Collectors 增加了两种新技术:着色指针和读屏障。
着色指针
着色指针是一种将信息存储在指针(或使用 Java 术语引用)中的技术。因为在 64 位平台上( ZGC 仅支持 64 位平台),指针可以处理更多的内存,因此可以使用一些位来存储状态。ZGC 将限制最大支持 4Tb 堆( 42-bits ),那么会剩下 22 位可用,它目前使用了 4 位:finalizable 、remap 、mark0 和 mark1 。
着色指针的一个问题是,当您需要取消着色时,它需要额外的工作(因为需要屏蔽信息位)。像 SPARC 这样的平台有内置硬件支持指针屏蔽所以不是问题,而对于 x86 平台来说,ZGC 团队使用了简洁的多重映射技巧。
多重映射
要了解多重映射的工作原理,我们需要简要解释虚拟内存和物理内存之间的区别。物理内存是系统可用的实际内存,通常是安装的 DRAM 芯片的容量。虚拟内存是抽象的,这意味着应用程序对(通常是隔离的)物理内存有自己的视图。操作系统负责维护虚拟内存和物理内存范围之间的映射,它通过使用页表和处理器的内存管理单元( MMU )和转换查找缓冲器( TLB )来实现这一点,后者转换应用程序请求的地址。
多重映射涉及将不同范围的虚拟内存映射到同一物理内存。由于设计中只有一个 remap 、mark0 和 mark1 在任何时间点都可以为 1 ,因此可以使用三个映射来完成此操作。ZGC 源代码中有一个很好的图表可以说明这一点。
读屏障
读屏障是每当应用程序线程从堆加载引用时运行的代码片段( 即访问对象上的非原生字段 non-primitive field ):
void printName( Person person ) {
String name = person.name; // 这里触发读屏障,因为需要从heap读取引用
System.out.println(name); // 这里没有直接触发读屏障
}在上面的代码中,String name = person.name 访问了堆上的person引用,然后将引用加载到本地的 name 变量。此时触发读屏障。Systemt.out 那行不会直接触发读屏障,因为没有来自堆的引用加载( name 是局部变量,因此没有从堆加载引用 )。但是 System 或者 println 内部可能会触发其他读屏障。
这与其他 GC 使用的写屏障形成对比,例如 G1 。读屏障的工作是检查引用的状态,并在将引用(或者甚至是不同的引用)返回给应用程序之前执行一些工作。在 ZGC 中,它通过测试加载的引用来执行此任务,以查看是否设置了某些位。如果通过了测试,则不执行任何其他工作,如果失败,则在将引用返回给应用程序之前执行某些特定于阶段的任务。
GC循环
标记
GC 循环的第一部分是标记。标记包括查找和标记运行中的应用程序可以访问的所有堆对象,换句话说,查找不是垃圾的对象。
ZGC 的标记分为三个阶段。第一阶段是 STW ,其中 GC roots 被标记为活对象。GC roots 类似于局部变量,通过它可以访问堆上其他对象。如果一个对象不能通过遍历从 roots 开始的对象图来访问,那么应用程序也就无法访问它,则该对象被认为是垃圾。从 roots 访问的对象集合称为 Live 集。GC roots 标记步骤非常短,因为 roots 的总数通常比较小。
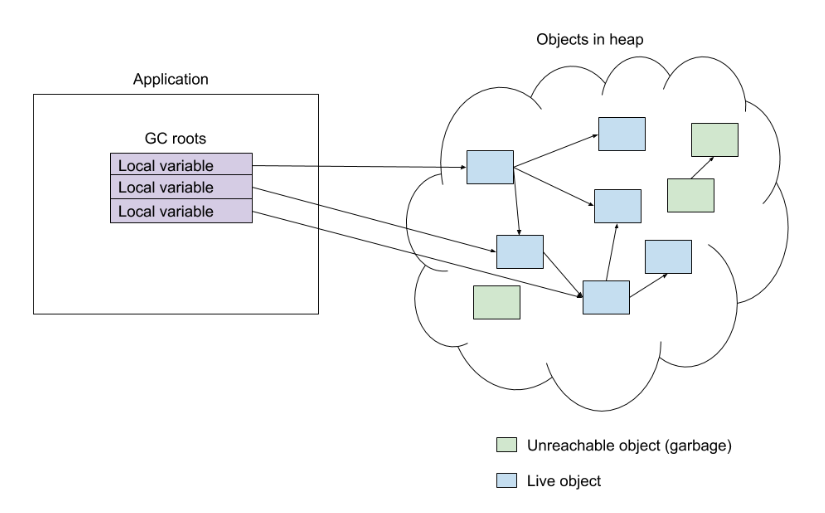
在遍历完成之后,有一个最终的、时间很短的 Stop The World 阶段,这个阶段处理一些边缘情况(我们现在将它忽略),该阶段完成之后标记阶段就完成了。
重定位
GC 循环的下一个主要部分是重定位。重定位涉及移动活动对象以释放部分堆内存。为什么要移动对象而不是填补空隙?有些 GC 实际是这样做的,但是它导致了一个不幸的后果,即分配内存变得更加昂贵,因为当需要分配内存时,内存分配器需要找到可以放置对象的空闲空间。相比之下,如果可以释放大块内存,那么分配内存就很简单,只需要将指针递增新对象所需的内存大小即可。
ZGC 将堆分成许多页面,在此阶段开始时,它同时选择一组需要重定位活动对象的页面。选择重定位集后,会出现一个 Stop The World 暂停,其中 ZGC 重定位该集合中 root 对象,并将他们的引用映射到新位置。与之前的 Stop The World 步骤一样,此处涉及的暂停时间仅取决于 root 的数量以及重定位集的大小与对象的总活动集的比率,这通常相当小。所以不像很多收集器那样,暂停时间随堆增加而增加。
移动 root 后,下一阶段是并发重定位。在此阶段,GC 线程遍历重定位集并重新定位其包含的页中所有对象。如果应用程序线程试图在 GC 重新定位对象之前加载它们,那么应用程序线程也可以重定位该对象,这可以通过读屏障(在从堆加载引用时触发)实现,如流程图如下所示:
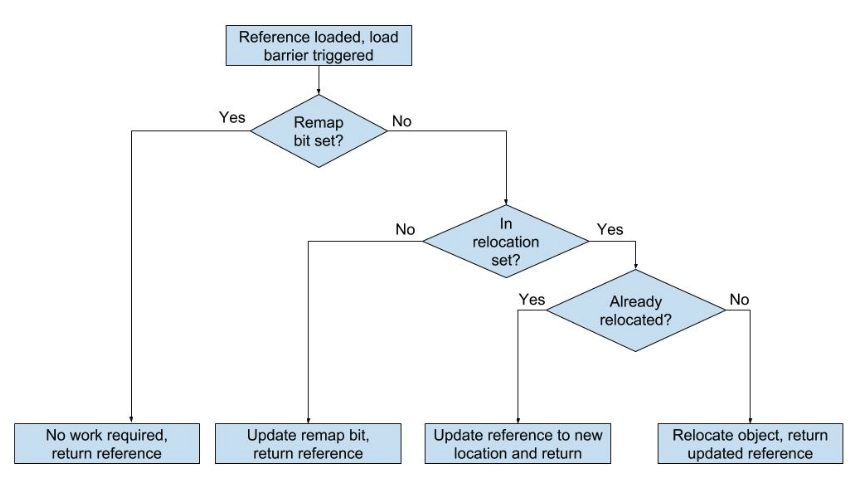
GC 线程最终将对重定位集中的所有对象重定位,然而可能仍有引用指向这些对象的旧位置。GC 可以遍历对象图并重新映射这些引用到新位置,但是这一步代价很高昂。因此这一步与下一个标记阶段合并在一起。在下一个 GC 周期的标记阶段遍历对象对象图的时候,如果发现未重映射的引用,则将其重新映射,然后标记为活动状态。
用法
运行我们的应用程序时,我们可以使用以下命令行选项启用 ZGC :
XX:+UnlockExperimentalVMOptions - XX:+UseZGC注意:因为ZGC还处于实验阶段,所以需要通过 JVM 参数 UnlockExperimentalVMOptions 来解锁这个特性。
平台支持
ZGC目前只支持 64 位的linux系统。
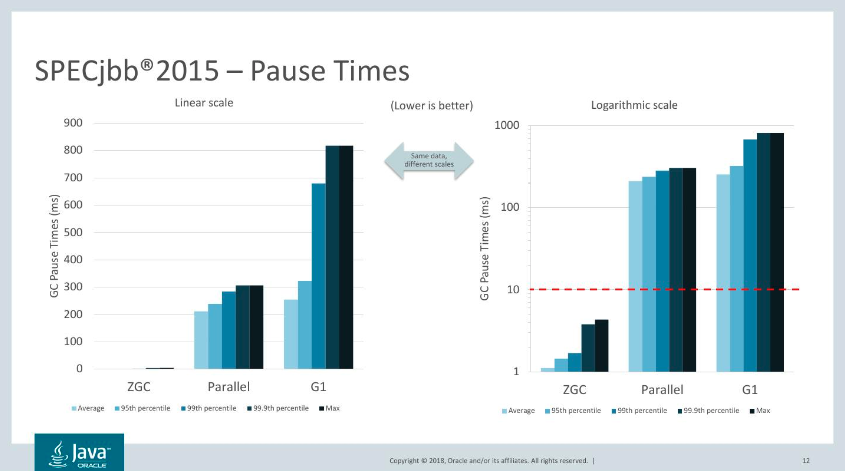
ZGC和G1停顿时间比较
ZGC
avg: 1.021 ms (+/- 0.215 ms)
95th percentile: 1.392 ms
99th percentile: 1.512 ms
99.9th percentile: 1.663 ms
99.99th percentile: 1.681 ms
max: 1.681 msG1
avg: 157.202 ms (+/- 71.126 ms)
95th percentile: 316.672 ms
99th percentile: 428.095 ms
99.9th percentile: 543.846 ms
99.99th percentile: 543.846 ms
max: 543.846 msStefan Karlsson 和 Per Liden 在早些时候的 Jfokus 演讲中给出了一些数字。ZGC 的 SPECjbb2015 吞吐量与 Parallel GC (优化吞吐量)大致相当,但平均暂停时间为 1ms ,最长为 4ms 。与之相比 G1 和 Parallel 有很多次超过 200ms 的 GC 停顿。
1.19 其他新特性
移除项
- 1 、移除了com.sun.awt.AWTUtilities
- 2 、移除了sun.misc.Unsafe.defineClass,使用java.lang.invoke.MethodHandles.Lookup.defineClass来替
- 代
- 3 、移除了Thread.destroy()以及 Thread.stop(Throwable)方法
- 4 、移除了sun.nio.ch.disableSystemWideOverlappingFileLockCheck、sun.locale.formatasdefault属性
- 5 、移除了jdk.snmp模块
- 6 、移除了javafx,openjdk估计是从java 10 版本就移除了,oracle jdk 10 还尚未移除javafx,而java 11 版本则oracle的jdk版本也移除了javafx
- 7 、移除了Java Mission Control,从JDK中移除之后,需要自己单独下载
- 8 、移除了这些Root Certificates:Baltimore Cybertrust Code Signing CA,SECOM ,AOL and Swisscom
废弃项
- 1 、-XX:+AggressiveOpts选项
- 2 、-XX:+UnlockCommercialFeatures
- 3 、-XX:+LogCommercialFeatures选项也不再需要
JEP320:移除Java EE和CORBA模块(Remove the Java EE and CORBA Modules)
- 1 、java.xml.ws,
- 2 、java.xml.bind,
- 3 、java.xml.ws,
- 4 、java.xml.ws.annotation,
- 5 、jdk.xml.bind,
- 6 、jdk.xml.ws被移除,
- 只剩下java.xml,java.xml.crypto,jdk.xml.dom这几个模块
- 7 、java.corba,
- 8 、java.se.ee,
- 9 、java.activation,
- 10 、java.transaction被移除,但是java 11 新增一个java.transaction.xa模块
JEP335:Deprecate the Nashorn JavaScript Engine
废除Nashorn javascript引擎,在后续版本准备移除掉。
JEP336:Deprecate the Pack200 Tools and API
JDK5 中带了一个压缩工具:Pack200,在 JDK11 中废除了 pack200 以及 unpack200 工具以及 java.util.jar 中的 Pack200 API 。因为 Pack200 主要是用来压缩 jar 包的工具,由于网络下载速度的提升以及 JDK9 引入模块化系统之后不再依赖 Pack200 ,因此这个版本将其移除掉。
JEP332:Transport Layer Security (TLS) 1.3
实现 TLS 协议 1.3 版本。( TLS 允许客户端和服务端通过互联网以一种防止窃听,篡改以及消息伪造的方式进行通信 )。
TLS1.3 是 TLS 协议的重大改进,与以前的版本相比,它提供了显着的安全性和性能改进。其他供应商的几个早期实现已经可用。我们需要支持 TLS1.3 以保持竞争力并与最新标准保持同步。这个特性的实现动机和 Unicode10 一样,也是紧跟历史潮流。
JEP328:Flight Recorder
排错、监控、性能分析是整个开发生命周期必不可少的一部分,但是某些问题只会在大量真实数据压力下才会发生在生产环境。
Flight Recorder 记录源自应用程序,JVM 和 OS 的事件。事件存储在一个文件中,该文件可以附加到错误报告中并由支持工程师进行检查,允许事后分析导致问题的时期内的问题。工具可以使用 API 从记录文件中提取信息。
1.20 总结
从 JDK8 到 JDK11 到 JDK17 再到目前的 JDK21 ,Java 的发展趋势显示出对性能优化、编程便利性和功能增强的持续关注。引入的新特性,如变量类型推断、官方 HTTP Client 和 String 处理增强,都是为了提高开发者的编程效率。同时,内部升级如更低的 GC 开销和时延,以及对 TLS1.3 的支持,都是为了提高 Java 应用的运行效率和安全性。这些改进和新特性的引入,都反映出 Java 在持续适应和引领现代编程需求的趋势。
1.21 参考
- Oracle JDK 官方文档
- Open JDK 官方文档
- JAVA 8与JAVA 11到底该怎么选?- Rooker - 博客园
- JDK8 和 JDK11 Java 两个主要版本的比较 - CSDN博客
- Java中JDK8、JDK11、JDK17,该怎么选择?- 阿里云开发者社区