图数据库由浅入深
- 一、什么是图数据库
- 1.1概念
- 1.2安装部署
- 二、Dgraph基本语法
- 2.1 Dgraph4j
- 2.3设置 schema
- 2.4查询
- 2.5突变
- 2.6数据监视
- 三、股权关系探索
- 四、图数据库的应用场景
- 五、参考资料
一、什么是图数据库
1.1概念
世间万物互联,关系无处不在。
我们都知道数据库是用来存储数据的一个系统,那么图数据库到底是什么?要想知道图数据库是什么,就需要对图的概念有所了解。
图( graph )是一种非线性结构,主要分为有向图和无向图,通常用邻接矩阵来存储图。

虽然可以用一个二维矩阵来存储图,但却非常的浪费空间;如果用关系型数据库来存储一组具有关系的数据时,通常至少需要两张表,一张存储关联关系,一张存储基本数据,这同样会造成空间的浪费。
而图数据库却可以方便地存储具有关联关系的数据,且不会造成空间的浪费,对于关系越复杂的数据,图数据库有着明显的存储优势,因为传统关系型数据库对于超过3张表关联的查询十分低效并且难以胜任。
所以,你现在可以理解,图数据库是专门存储具有”图“结构数据的一种非关系型数据库。
图数据库也有很多,包括:Dgraph、Neo4j、Nebula Graph、JanusGraph 等,而本文选择Dgraph。
1.2安装部署
Dgraph 的安装也比较简单,这里推荐使用 docker 的方式来部署
首先需要获取 Dgraph 核心组件镜像和 Dgraph 本地可视化终端镜像(可视化终端主要用于通过本地可视化界面来操作数据库)
拉取 Dgraph 核心组件镜像:
docker pull dgraph/standalone拉取 Dgraph 本地可视化终端镜像:
docker pull dgraph/ratel启动 docker 容器:
分别用以下命令启动 Dgraph 核心组件和可视化终端
docker run -it -p "8080:8080" -p "9080:9080" -v ~/dgraph:/dgraph "dgraph/standalone:latest" #启动核心组件docker run -it -p "8000:8000" "dgraph/ratel:latest" #启动可视化终端访问可视化终端:
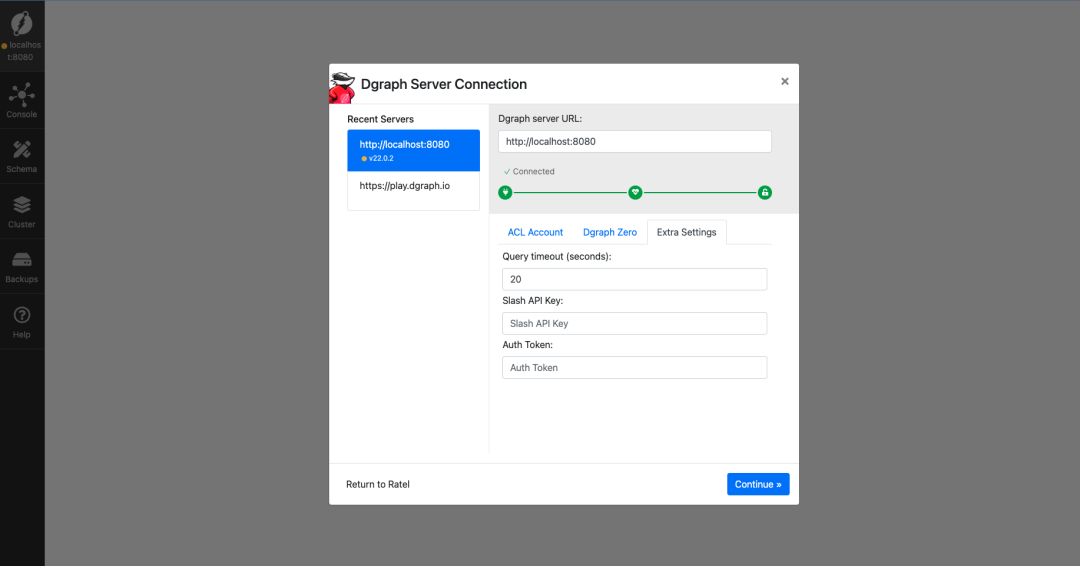
启动完成 Dgraph 可视化终端之后,可访问 http://localhost:8000 来进行相关操作(默认端口为8000,也可以手动指定),出现以下页面则说明Dgraph启动成功啦
二、Dgraph基本语法
Dgraph 操作可以在可视化页面上进行,也可以通过后端来操作。页面上的操作比较简单,本文主要介绍如何在后端操作 Dgraph。
2.1 Dgraph4j
Dgraph 底层源码采用 go 语言来实现,但通过 Dgraph4j 也可以通过 Java 来操作 Dgraph 数据库。Dgraph4j 采用 gRPC 来实现,使用起来非常方便。
添加依赖

添加依赖完成之后,就可以对 Dgraph 服务端进行连接了。
2.2连接 Dgraph4j
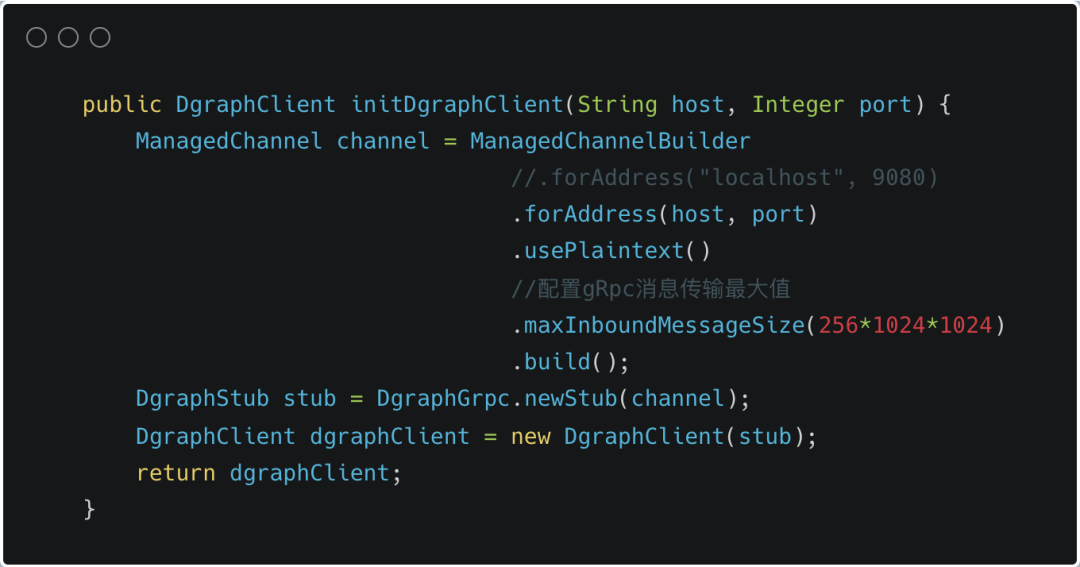
连接 Dgraph 时,可以根据实际情况进行配置。比如配置多个 Dgraph 服务,配置异步/同步客户端,配置 gRpc 消息传输最大值,配置指定的线程池等等。
配置完成之后,就可以通过 Java 操作 Dgraph 服务端进行增删改查了。
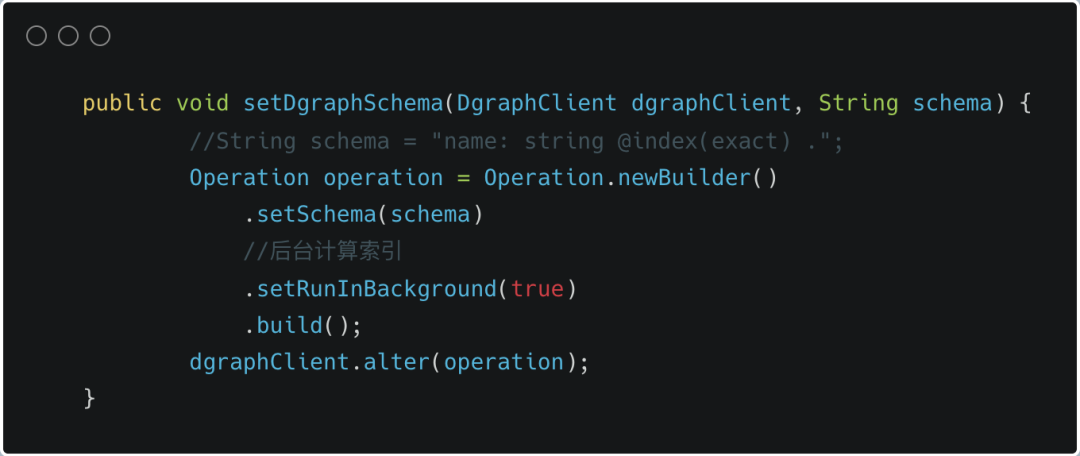
2.3设置 schema
2.4查询
通过 Dgraph4j 查询的语法有两种,一种是 JSON,一种是 RDF 语法。
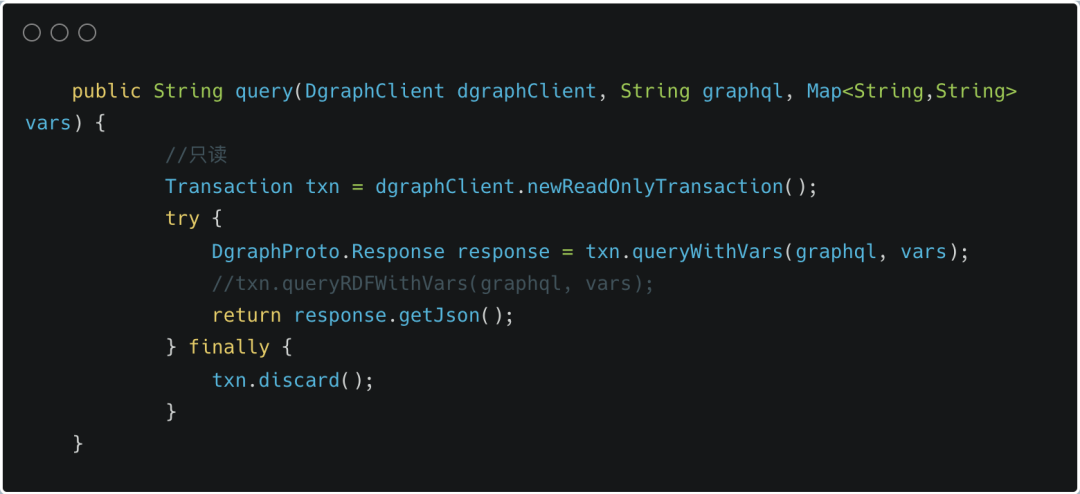
Dgraph4j 支持普通事务和只读事务,对于查询来说,使用只读事务性能会更好。如果想使用 RDF 格式的查询语法,只需使用 txn.queryRDFWithVars() 方法即可。比如,想查询名称等于"zcy"的节点信息,那么可以传入的 graphql 内容为:
{
result(func: eq(, "zcy")) {
uid
name
//其它属性
}
}2.5突变
在 Dgraph4j 中,添加/删除/修改都属于突变( mutation )。Dgraph 中的节点数据 uid 是唯一的,因此,如果突变过程中,传入指定的 uid,如果数据库内有数据就进行更新操作,没有数据就进行新增操作;如果不传入指定的 uid,那么节点 uid 就会由 Dgraph 自动分配,因此你要执行的添加/修改都会在数据库中新增一个节点。
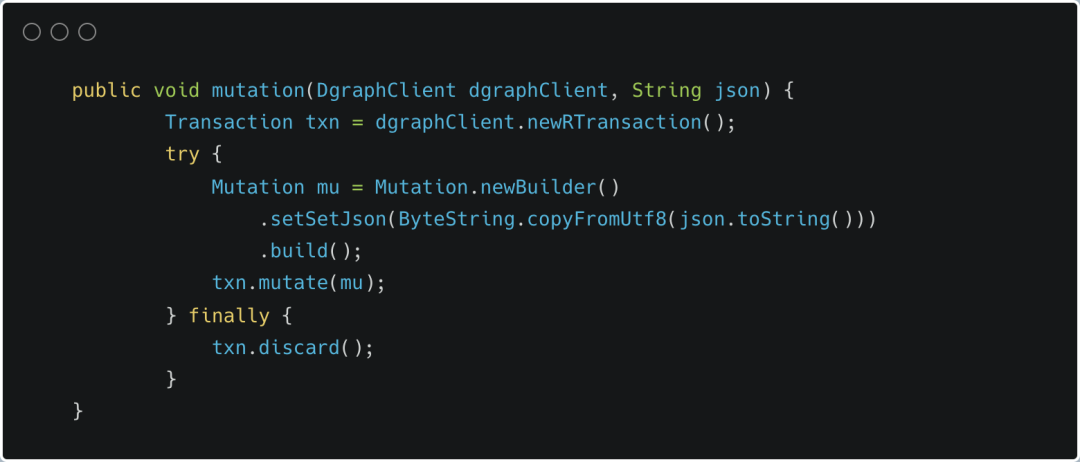
2.5.1 upsert
另外一种比较好用的突变方式是 upsert
upsert block 包含了一个 query block 和多个 mutation blocks,query block 中定义的变量可以通过 val()和 uid()在 mutation blocks 中使用。
query block 中的变量可以定义多个 uid,并使用 uid 来接收他们。执行 query block时,有两种可能的结果:
1):如果查询条件匹配不到任何节点,name 返回的变量就是空的,uid()会返回一个新的 uid,类似于空白节点。对于删除操作,它不会返回 uid,并且这个操作会默认被忽略,不会执行。
2):如果变量中存储了多个 uid,那么 uid()函数会将所有 uid 返回,并对所有 uid 执行操作。
可根据实际应用场景来选择,毕竟如果数据库存在 uid 不一样的两条相同数据,对业务还是会有一定影响的。(因为多数情况下,业务可能并不是根据 uid 来查询,如果根据其他信息如名字,就会查出多条数据,从而对业务有一定影响)。
2.6数据监视
如果想要在数据发生变化(添加/更新/删除)时进行监听,可以使用 @lambdaOnMutate 指令。
根据定义的事件和突发事件的发生情况,@lambdaOnMutate 会触发在给定 lambda 服务器上实现的相应 lambda 函数。
要设置一个 lambda webhook,需要在 GraphQL schema 中使用 @lambdaOnMutate来定义,并定义要监听的突变时间(添加、更新、删除),但是只能监听根节点的突变。比如想要对 Author 节点进行监视:
type Author @lambdaOnMutate(add: true, update: true, delete: true) {
id: ID!
name: String! @search(by: [hash, trigram])
dob: DateTime
reputation: Float
}三、股权关系探索
对于政府采购业务来说,采购流程每一步都要遵循法律法规,因此维护一个"公平、平开、公正"的政府采购环境是非常必要的。
在采购流程中,供应商的股权关系是非常重要的一组数据,如果能够在开标之前将有股权关联的供应商筛选出来进行预警,这对于政府采购环境是很大的改善。
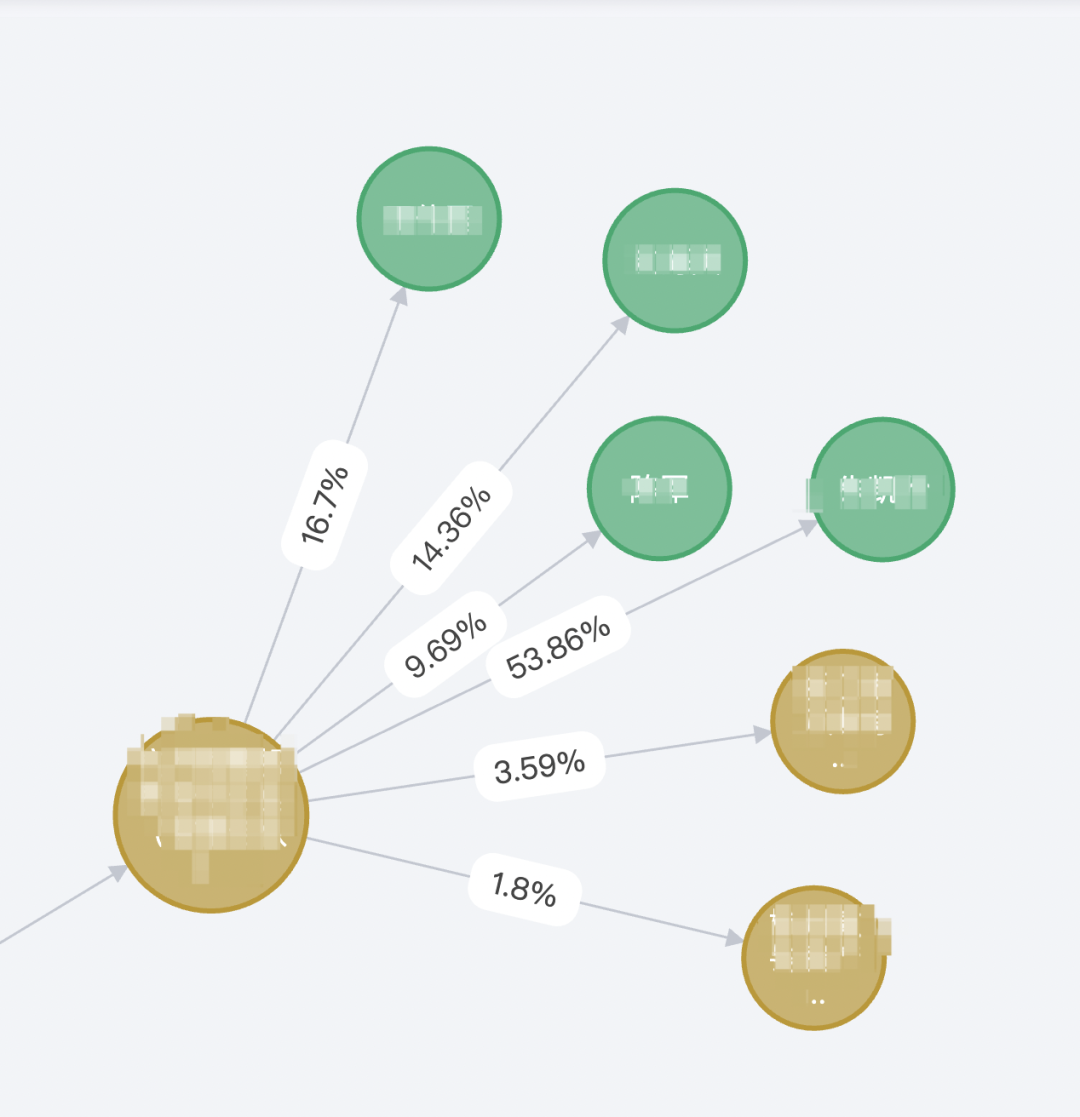
我司已基于图数据库构建股权关系相关服务,通过对相关供应商的股权数据进行分析,在开标前进行预警和提示,提高了采购监管效率和智能化。
四、图数据库的应用场景
在图数据库中,数据是一切的基础,关系才是应用的关键;数据本身并没有价值,将数据关联起来才能发掘数据本身或者潜在的价值。一样的数据,构造不同的数据模型,也能应用在不同的场景。
1、数据大屏可视化
2、股权关系
3、大数据分析
有了数据,通过构造关系将大量数据连接起来,再结合人工智能等手段更有利于分析和发掘数据的价值。
五、参考资料
- dgraph4j
- dgraph官方
- dgraph中文版
- 图数据技术调研以及业务实践