Simhash在内容去重中的应用
一、背景
信息流个性化推荐场景中依赖爬虫抓取的海量新闻库,这些新闻中不乏互相抄袭的新闻,这些内容相似的文章,会造成内容的同质化并加重数据库的存储负担,更糟糕的是降低了信息流内容的体验。所以需要一种准确高效的文本去重算法。而最朴素的做法就是将所有文本进行两两比较,简单易理解,最符合人类的直觉,这种做法对于少量文本来说,实现起来很方便,但是对于海量文本来说是行不通的,所以应在尽可能保证准确性的同时,降低算法的时间复杂度。事实上,传统比较两个文本相似性的方法,大多是将文本分词之后,转化为特征向量距离的度量,比如常见的欧氏距离、海明距离或者余弦角度等等。下面以余弦相似度和simhash算法为例做简单介绍。
1.1余弦相似度
余弦相似度的核心思想是计算两个向量的夹角余弦值来判断两个句子的相似度,以下面两个句子为例:
第一步分词:
句子A:我/喜欢/看/电视,不/喜欢/看/电影
句子B:我/不/喜欢/看/电视,也/不/喜欢/看/电影
第二步列出所有词:
我,喜欢,看,电视,电影,不,也
第三步计算词频:
句子A:我1,喜欢2,看2,电视1,电影1,不1,也0
句子B:我1,喜欢2,看2,电视1,电影1,不2,也1
第四步,写出词向量:
句子A:[1,2,2,1,1,1,0]
句子B:[1,2,2,1,1,2,1]
到这里就可以将两个句子的相似度转换为两个向量的相似度,我们可以把这两个句子想象为空间中的两条线段,都是从原点[0,0,0...]出发,指向不同的方向,两条线段形成一个夹角,如果夹角为0,意味着方向相同线段重合,如果夹角为90度意味着形成直角,完全不相似,因此我们可以通过夹角来判断相似度,夹角越小就代表越相似。
余弦相似度得到的结果较为精确,但当面对大量文本时,计算文本向量的时间复杂度很高,这可能会影响性能。
1.2 simHash算法
simHash是谷歌提出来的一套用于文本去重的算法,将文本映射为一个01串,并且保证相似文本哈希之后得到的01串也是相似的,只在少数几个位置上的0和1不一样。
为了表征原始文本的相似度,可以计算两个01串之间在多少个位置上不同,这便是汉明距离,用来表征simHash算法下两个文本之间的相似度,通常来说,越相似的文本,对应simHash映射得到的01串之间的汉明距离越小。
举例:t1=“直击儿科急诊现状忙碌不止 儿科接诊进行时 ”t2=“儿科急诊现状直击不停忙碌 儿科接诊进行时 ”;可以看到,上面这两个字符串虽然只有几个字不同,但是通过简单的Hash算法得到的hash值可能就完全不一样了,因而无法利用得到的hash值来表征原始文本的相似性。
然而通过simHash算法的映射后,得到的simHash值便是如下:

这两个文本生成的两个64位的01串只有标红的3个位置不同。
通常来说,用于相似文本检测中的汉明距离判断标准就是3,也就是说,当两个文本对应的simHash之间的汉明距离小于或等于3,则认为这两个文本为相似,如果是要去重的话,就只能留下其中一个。
下图为在各种汉明距离的情况下simhash算法的准确和召回率变化趋势,可以看到在汉明距离为3时能够达到较好的平衡:
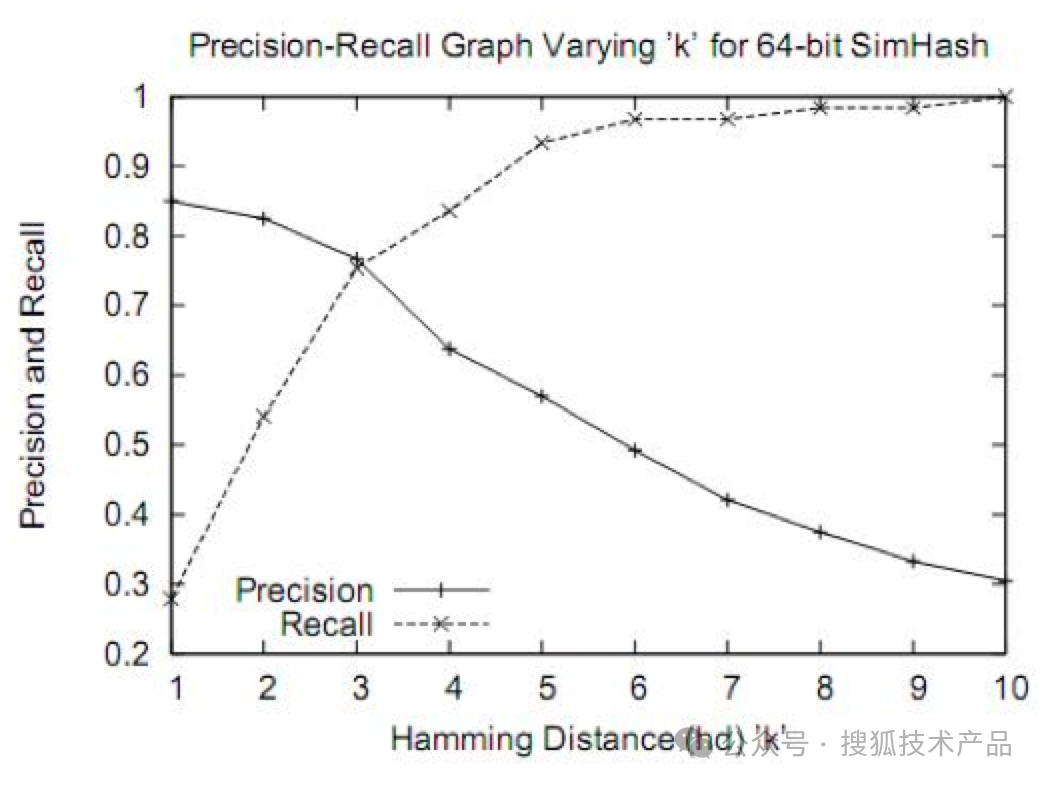
相比计算余弦相似度,simhash算法可以快速计算文本的哈希值,而且能够在哈希值之间计算汉明距离,从而衡量文本的相似度。simhash算法的优点是它能够快速处理大量文本,并且可以识别并过滤掉文本中的噪声和重复内容。
二、simhash实现步骤
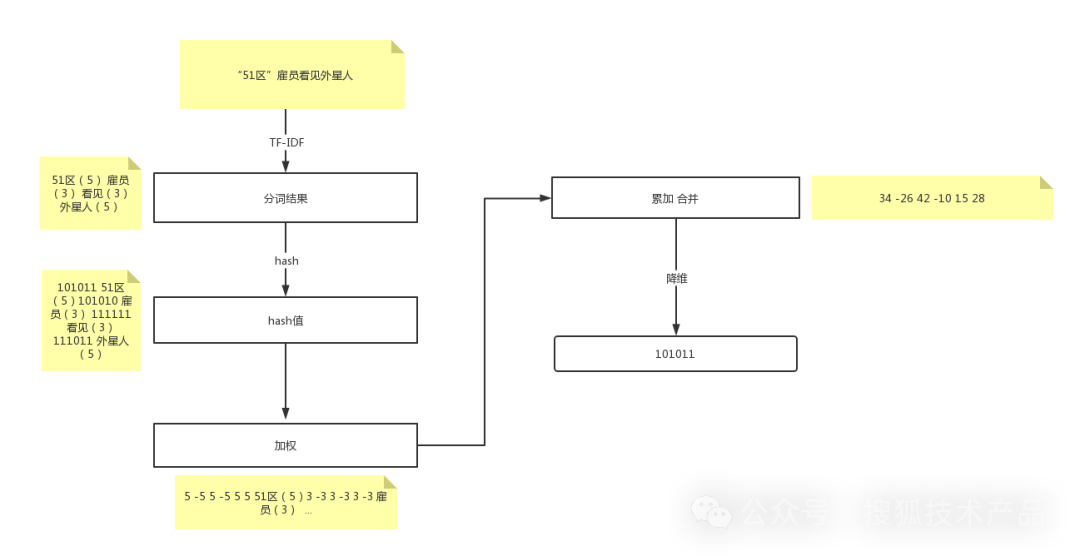
1、分词,把需要判重的文本分词,形成去掉噪音词的单词序列并为每个词加上权重。我们假设权重分为5个级别(1~5)。比如:“ 美国“51区”雇员称内部有9架飞碟,曾看见灰色外星人 ” ==> 分词后为 “ 美国(4) 51区(5) 雇员(3) 称(1) 内部(2) 有(1) 9架(3) 飞碟(5) 曾(1) 看见(3) 灰色(4) 外星人(5)”,括号里的权重代表重要程度,数字越大越重要,这里我们采用ansj分词器,tf-idf的方式计算权重。生成一个词和对应权重的map。
public static List\<String\> splitWords(String str) {
List\<String\> splitWords = new ArrayList\<String\>(1000);
Result terms = ToAnalysis.parse(str, forest);
for (int i = 0; i \< terms.size(); i++) {
Term term = terms.get(i);
String word = term.getName();
if (!"".equals(word.trim()) && !stopWords.contains(word)) {
splitWords.add(word);
}
}
return splitWords;
}
public Map\<String, Double\> extract(String str) {
List\<String\> words = WordsSegment.splitWords(str);
// 计算词频tf
int initialCapacity = Math.*max*((int) Math.*ceil*(words.size() / 0.75) + 1, 16);
Map\<String, Double\> wordmap = new HashMap\<String, Double\>(initialCapacity);
for (String word : words) {
if (!wordmap.containsKey(word)) {
wordmap.put(word, 1.0);
} else {
wordmap.put(word, wordmap.get(word) + 1);
}
}
Iterator\<Entry\<String, Double\>\> it = wordmap.entrySet().iterator();
while (it.hasNext()) {
Entry\<String, Double\> item = (Entry\<String, Double\>) it.next();
String word = item.getKey();
if (stopWords.contains(word) \|\| word.length() \< 2) {
it.remove();
continue;
}
// 计算权重idf
if (idfMap.containsKey(word)) {
double idf = wordmap.get(word) \* idfMap.get(word);
wordmap.put(word, idf);
} else {
double idf = wordmap.get(word) \* idfAverage;
wordmap.put(word, idf);
}
}
return wordmap;
}2、hash,通过hash算法把每个词变成hash值,比如“美国”通过hash算法计算为 100101,“51区”通过hash算法计算为 101011。这样我们的字符串就变成了一串串数字,还记得文章开头说过的吗,要把文章变为数字计算才能提高相似度计算性能,现在是降维过程进行时。
public static BigInteger fnv1aHash64(String str) {
BigInteger hash = FNV_64_INIT;
int len = str.length();
for (int i = 0; i \< len; i++) {
hash = hash.xor(BigInteger.valueOf(str.charAt(i)));
hash = hash.multiply(FNV_64_PRIME);
}
hash = hash.and(MASK_64);
return hash;
}3、加权,通过2步骤的hash生成结果,需要按照单词的权重形成加权数字串,比如“美国”的hash值为“100101”,通过加权计算为“4 -4 -4 4 -4 4”;“51区”的hash值为“101011”,通过加权计算为 “ 5 -5 5 -5 5 5”。
4、合并,把上面各个单词算出来的序列值累加,变成只有一个序列串。比如 “美国”的 “4 -4 -4 4 -4 4”,“51区”的 “ 5 -5 5 -5 5 5”, 把每一位进行累加, “4+5 -4+-5 -4+5 4+-5 -4+5 4+5” ==》 “9 -9 1 -1 1 9”。这里作为示例只算了两个单词的,真实计算需要把所有单词的序列串累加。
5、降维,把4步算出来的 “9 -9 1 -1 1 9” 变成 0 1 串,形成我们最终的simhash签名。如果每一位大于0 记为 1,小于0 记为 0。最后算出结果为:“1 0 1 0 1 1”。
private void analysis(String content) {
Map\<String, Double\> wordInfos = wordExtractor.extract(content);
Map\<String, Double\> newwordInfo = valueUpSort(wordInfos);
wordInfos.entrySet().stream()
.sorted(Collections.reverseOrder(Map.Entry.comparingByValue()))
.forEachOrdered(x -\> newwordInfo.put(x.getKey(), x.getValue()));
double[] featureVector = new double[FNVHash.HASH_BITS];
Set\<String\> words = wordInfos.keySet();
for (String word : words) {
BigInteger wordhash = FNVHash.fnv1aHash64(word);
for (int i = 0; i \< FNVHash.HASH_BITS; i++) {
BigInteger bitmask = BigInteger.ONE.shiftLeft(FNVHash.HASH_BITS - i - 1);
if (wordhash.and(bitmask).signum() != 0) {
featureVector[i] += wordInfos.get(word);
} else {
featureVector[i] -= wordInfos.get(word);
}
}
}
BigInteger signature = BigInteger.ZERO;
StringBuffer hashBuffer = new StringBuffer();
for (int i = 0; i \< FNVHash.HASH_BITS; i++) {
if (featureVector[i] \>= 0) {
signature = signature.add(BigInteger.ONE.shiftLeft(FNVHash.HASH_BITS - i - 1));
hashBuffer.append("1");
} else {
hashBuffer.append("0");
}
}
this.hash = hashBuffer.toString();
this.signature = signature;
}算法部分流程图如下:
三、空间换时间提高排重速度
通过这种特殊的局部敏感哈希算法看起来是解决了相似性对比的问题,但是,检索一条汉明距离小于给定阈值的simhash时间复杂度是O(n²) ,这在海量数据下使用的代价是昂贵的。
为了解决这个问题,可以采用空间换时间的思路,假定汉明距离<3时认为文档与给定文档相似;每一个simHash都从高位到低位均分成4段,每一段都是16位。
在建立倒排索引的过程中,这些截取出来的16位01串的片段,分别作为索引的key值,并将对应位置上具有这个片段的所有文本添加到这个索引的value域中。
直观上理解,首先有四个大桶,分别是1,2,3,4号(对应的是64位hash值中的第一、二、三、四段),在每一个大桶中,又分别有个小桶,这些小桶的编号从0000000000000000到1111111111111111.在建立索引时,每一个文本得到对应的simHash值后,分别去考察每一段(确定是1,2,3和4中的哪个大桶),再根据该段中的16位hash值,将文本放置到对应大桶中对应编号的小桶中。
索引建立好后,由于相似文本一定会存在于某一个16位hash值的桶中,因此针对这些分段的所有桶进行去重(可以并行做),便可以将文本集合中的所有相似文本去掉。
- 1、设汉明距离<n时认为文档与给定文档相似;
- 2、将simhash值分为n段,则汉明距离<n时两串simhash之间至少有一段完全相同;
- 3、将信息保存到哈希表中,其中n段中的每一段都作为key,simhash值作为value。
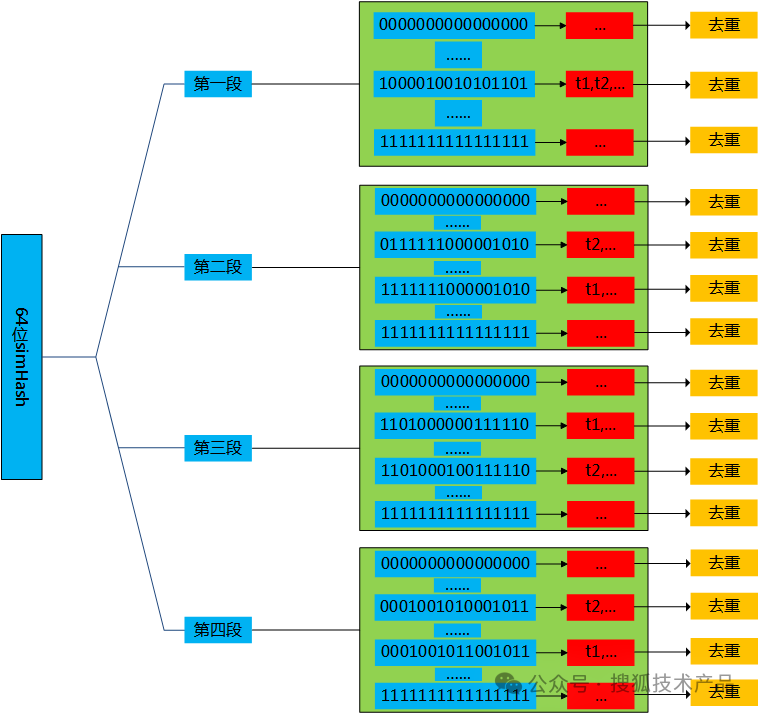
这样,检索速度最快为OO(1),最慢为O(n),远优于原本的O(n^2),缺点是空间膨胀到原来的n倍。通常n为4,是一个可以接受的膨胀倍率。
因此,我们把64位的01串分隔为4份,每份以key-list的结构存入redis中,当新的文章需要判断时,则分四段分别到索引中查找。
private void buildContenIndex(String docId, String simHash, String title, String url, String content_index_name, String eid, String oid) {
long storageTime = System.*currentTimeMillis*();
String simHashFragment1 = simHash.substring(0, 16);
String simHashFragment2 = simHash.substring(16, 32);
String simHashFragment3 = simHash.substring(32, 48);
String simHashFragment4 = simHash.substring(48, 64);
String redisKey1 = content_index_name + "_" + simHashFragment1;
String redisKey2 = content_index_name + "_" + simHashFragment2;
String redisKey3 = content_index_name + "_" + simHashFragment3;
String redisKey4 = content_index_name + "_" + simHashFragment4;
String value = docId + "\\001" + title + "\\001" + simHash + "\\001" + url + "\\001" + storageTime + "\\001" + eid;
NewRedisCrud.set2list(redisKey1, value, oid);
NewRedisCrud.set2list(redisKey2, value, oid);
NewRedisCrud.set2list(redisKey3, value, oid);
NewRedisCrud.set2list(redisKey4, value, oid);
}四、总结
内容去重有很多应用场景,simhash作为谷歌选来作为网页内容去重的一种算法,在海量数据去重的效率上有着明显的速度优势,相对传统文本相似性方法,simhash的降维解决了计算量庞大的问题,但对短文本的去重准确率上有较明显的欠缺,因此我们在了解业务的背景和需求后才能做出相对合理的选择。