数据分片算法有哪些?
我们经常需要处理海量数据。通常,我们需要将数据分割成更小、更易于管理的片段或 "碎片"。下面是一些常用的数据分片算法:
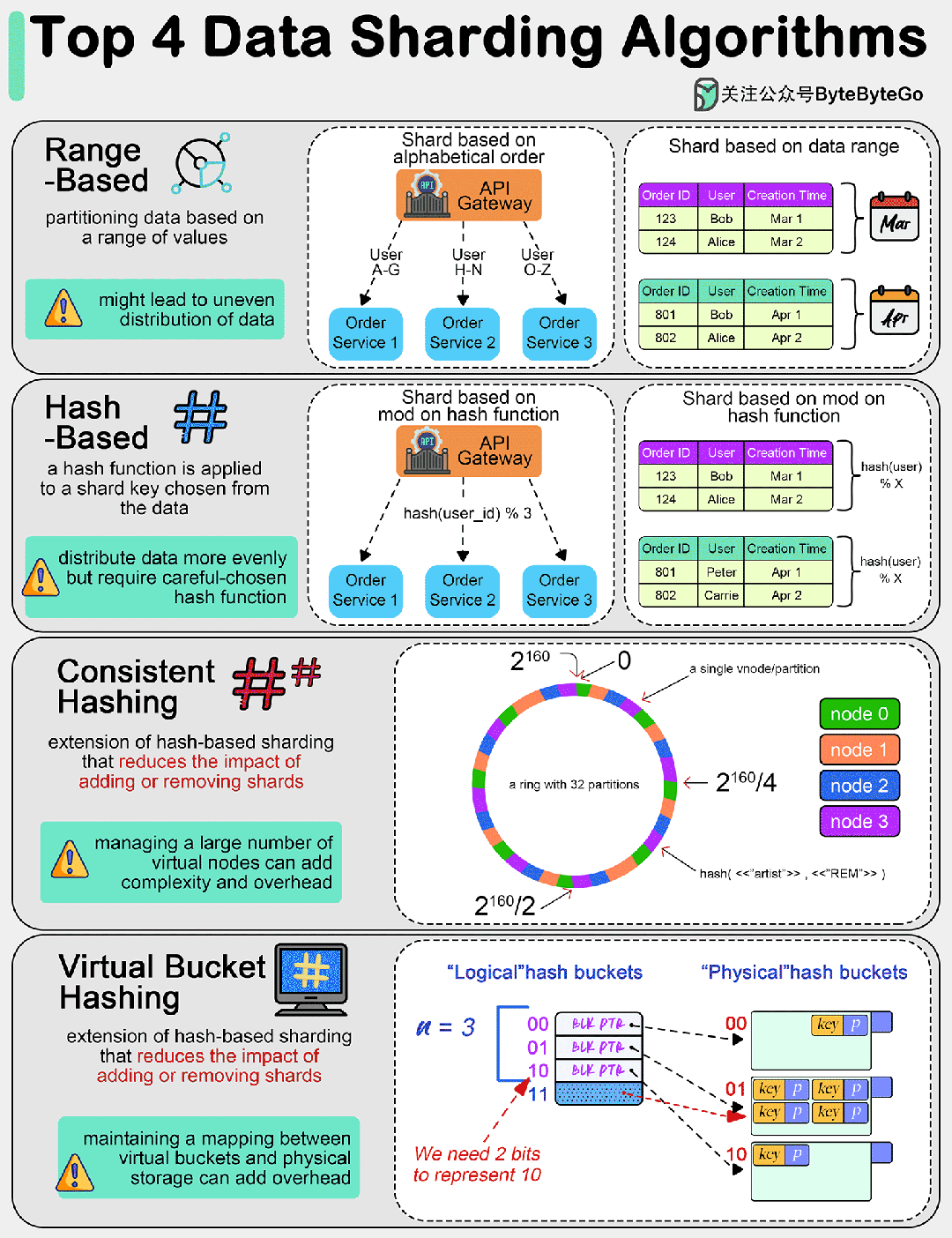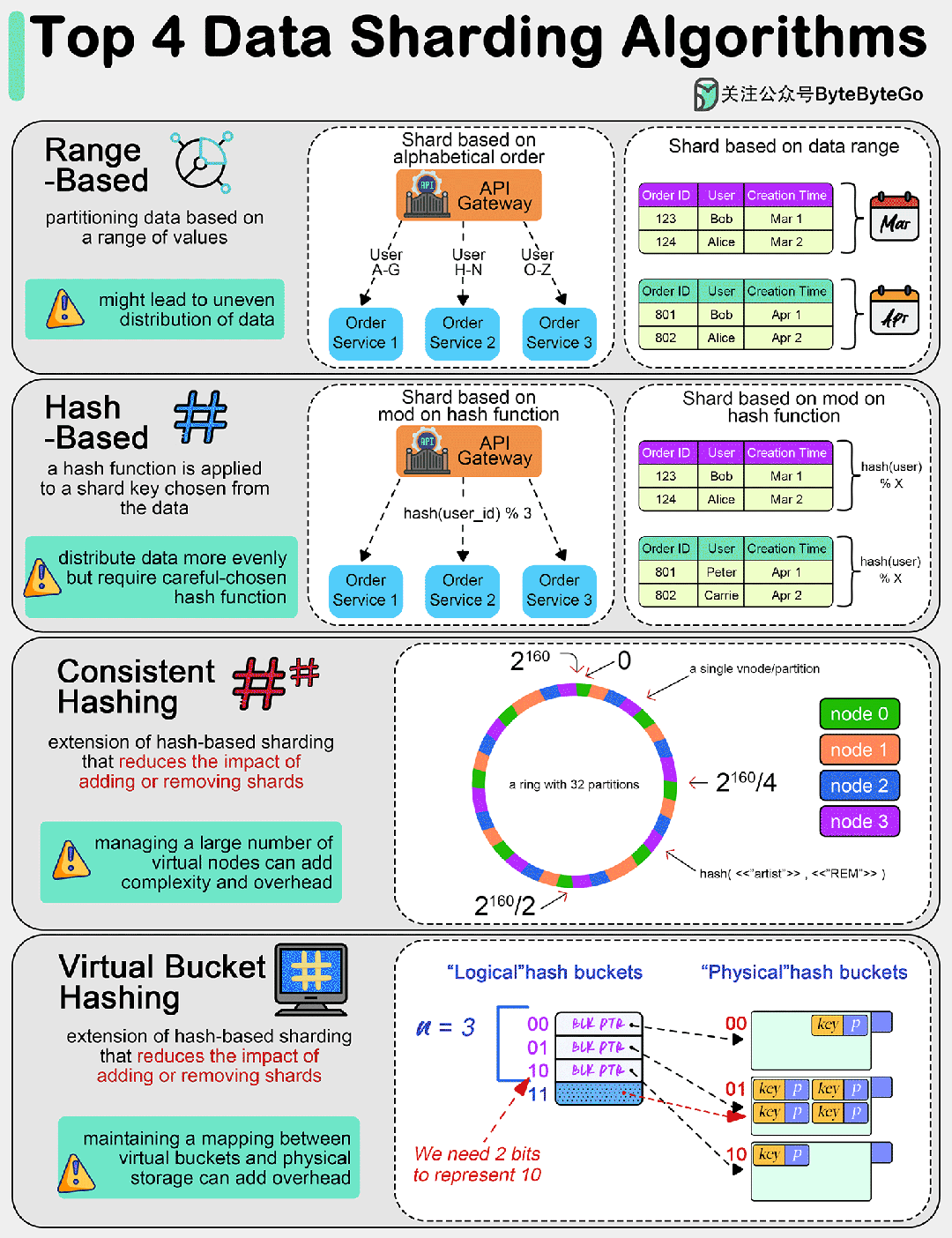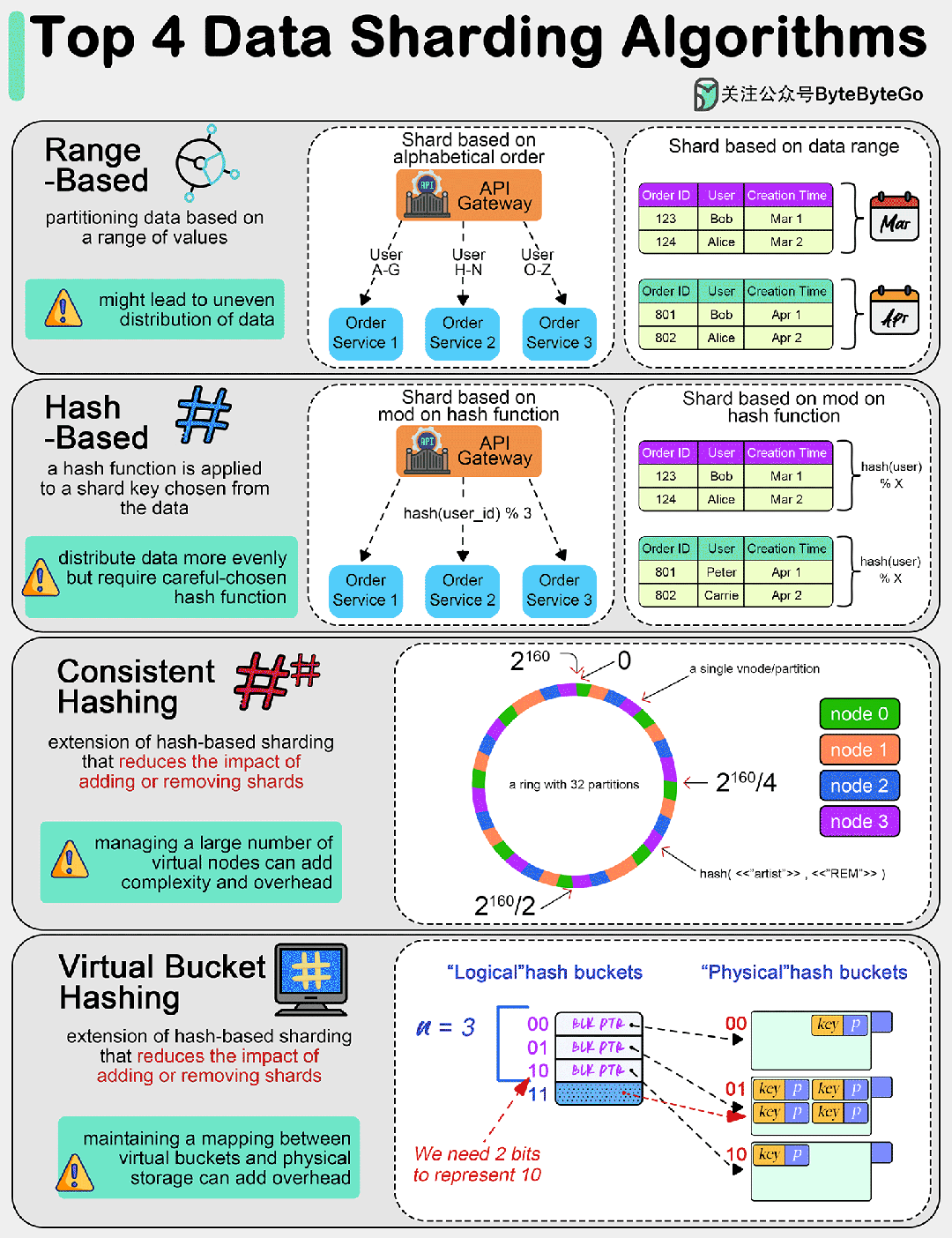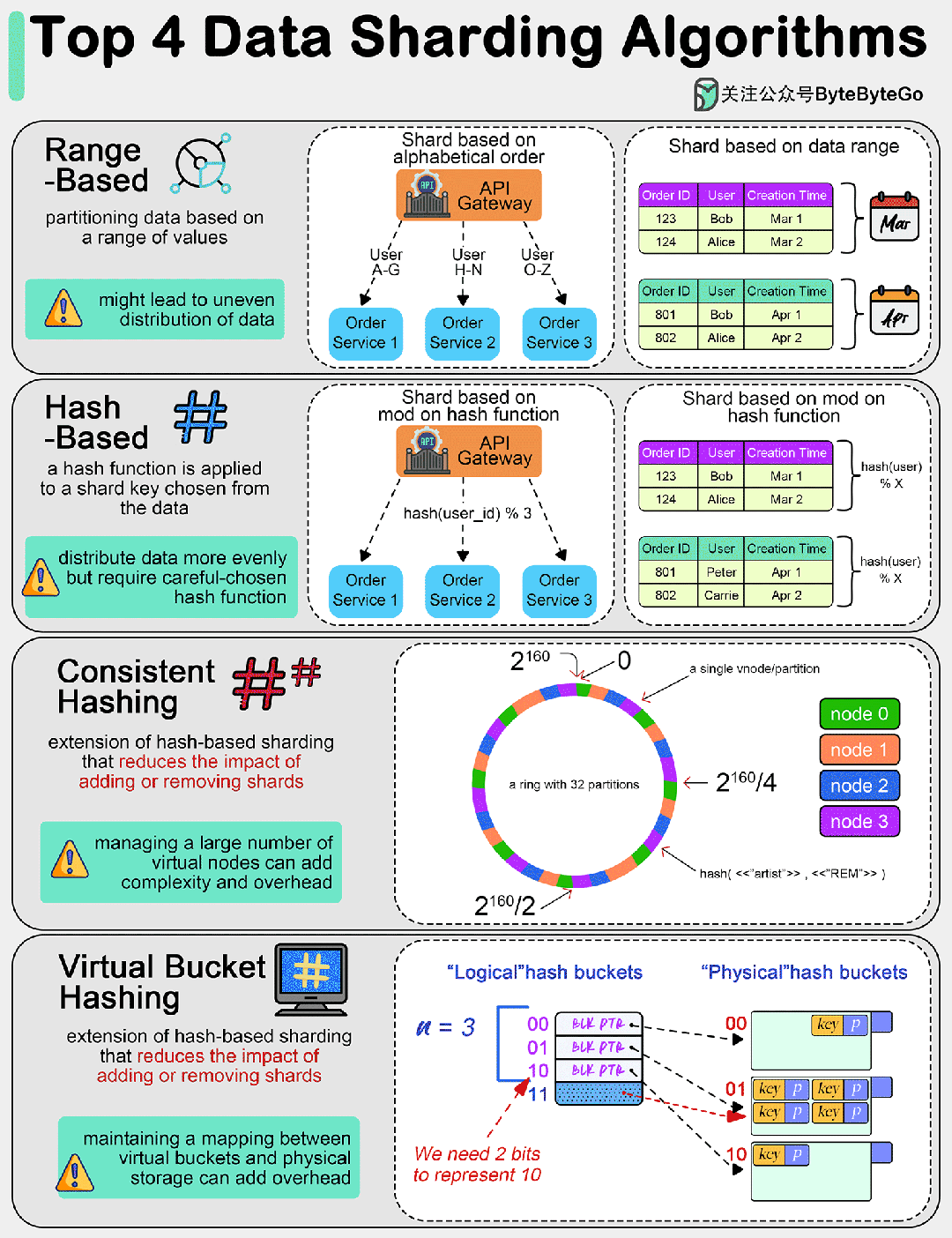
01 基于范围的分片
这种方法根据数值范围分割数据。例如,可以根据姓氏的字母顺序对客户数据进行分片,或者根据日期范围对交易数据进行分片。
这种方法简单明了,但会导致数据分布不均匀,即所谓的 "分片偏斜"(shard skew)。
02 基于散列的分片
在这种方法中,散列函数适用于从数据中选择的分片键(如客户 ID 或交易 ID)。结果决定了数据将进入哪个分片。
与基于范围的分片法相比,这种方法往往能将数据更均匀地分配到各个分片。不过,我们需要选择一个合适的散列函数,以避免发生散列冲突。
03 一致散列
这是基于散列分片的扩展,可以减少添加或删除分片的影响。它能更均匀地分配数据,并最大限度地减少添加或删除分片时需要重新定位的数据量。
一致散列的主要思想是将散列空间想象成一个固定的圆环。环上的每个点都对应一个散列值。
网络中的每个服务器(或节点)都会根据其标识符(如 IP 地址、服务器名称)的散列值在环上分配一个位置。这种散列方式应使服务器均匀分布在散列环上。
同样,每个数据项(或键值)都会根据其散列值在散列环上分配一个位置。要找到特定密钥在网络中的位置,系统会先找到环上的位置,然后顺时针走,直到找到第一台服务器。
当添加新服务器时,它会在不影响整个系统的情况下占据圆环上的位置。只有位于新服务器和下一个顺时针相邻服务器之间的键值需要转移到新服务器上,其他键值不受影响。同样,当一台服务器被移除时,只有它的键值需要重新分配给顺时针方向的下一台服务器。
04 虚拟桶分片
数据被映射到虚拟桶,然后这些桶又被映射到物理分片。这种两级映射可实现更灵活的分片管理和再平衡,而无需大量数据移动。