Rust在数据工程领域中的应用
近年来,数据工程领域发生了重大变化。数据系统日益复杂,对实时处理的需求,以及对可靠性和性能的不断需求,促使人们寻找更健壮的编程语言。这就是Rust的用武之地,Rust的增长速度非常快:
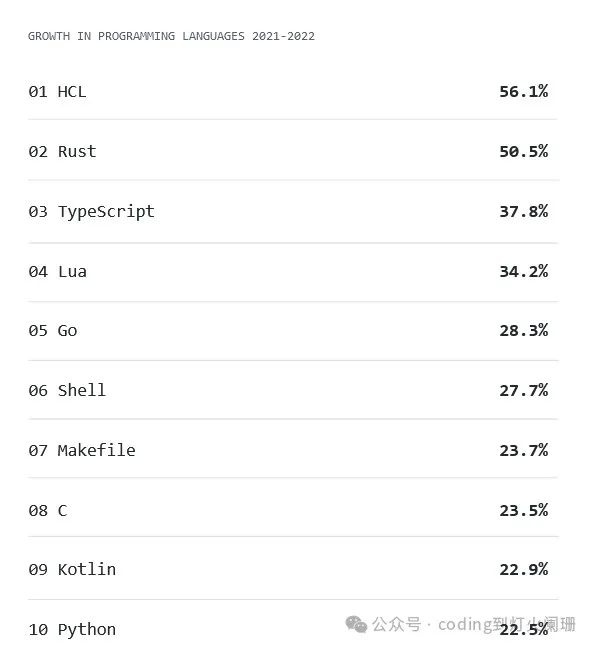
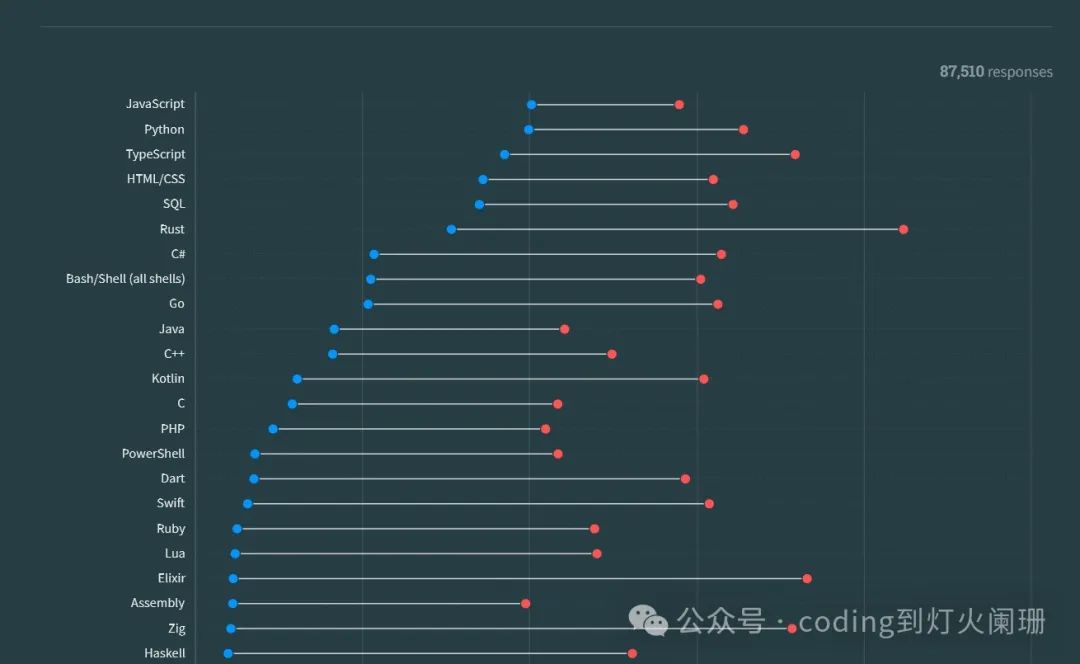
在这些竞争者中,Rust在2024年作为数据工程师的强大工具出现了,它承诺内存安全性、并发性和高效性。但是,究竟是什么让Rust成为数据工程的合适选择,以及如何在这个领域有效地利用它?
Rust在数据工程领域越来越受欢迎的一些关键原因:
1,内存安全:Rust的所有权系统确保在编译时捕获空指针解引用和缓冲区溢出等内存错误,从而降低运行时崩溃的风险。
2,并发性:凭借其轻量级并发模型和严格的编译时检查,Rust使编写既安全又高效的并发程序变得更容易,这是数据密集型应用程序的关键需求。
3,性能:Rust的性能与C和C++相当,适合高吞吐量的数据处理任务。
4,生态系统:Rust生态系统虽然相对年轻,但随着库和工具的不断成熟,它们越来越支持数据工程任务。
Rust构建数据工程的模块
为了在数据工程中有效地利用Rust,有必要了解构建模块以及它们如何适应更广泛的数据管道。
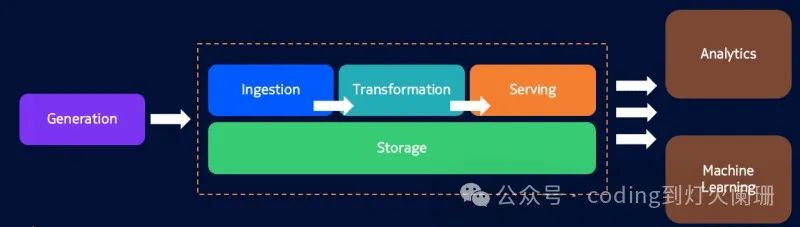
1 数据摄取
数据摄取是任何数据管道中的第一步,它包括从各种来源收集原始数据,并为进一步处理做好准备。Rust的并发能力在这里派上了用场。像HTTP请求的request和kafka-rust这样的库可以进行高效和安全的数据摄取。
例子:
use reqwest::Client;
use tokio::stream::StreamExt;
#[tokio::main]
async fn main() {
let client = Client::new();
let urls = vec!["http://example.com/data1", "http://example.com/data2"];
let fetches = futures::stream::iter(urls)
.map(|url| {
let client = client.clone();
async move {
let resp = client.get(url).send().await?;
let body = resp.text().await?;
Ok(body)
}
})
.buffer_unordered(5);
fetches
.for_each(|res| async {
match res {
Ok(data) => println!("Fetched data: {}", data),
Err(e) => eprintln!("Error: {}", e),
}
})
.await;
}2,数据转换
一旦数据被摄取,下一步就是处理。这可能涉及转换、聚合和过滤。Rust强大的迭代器系统和函数式编程范例支持富有表现力和高效的数据处理。
例子:
let data = vec![1, 2, 3, 4, 5];
let processed_data: Vec<_> = data
.into_iter()
.filter(|&x| x % 2 == 0)
.map(|x| x * 2)
.collect();
println!("Processed data: {:?}", processed_data);3,数据存储
有效地存储处理过的数据对于任何数据管道都是至关重要的。Rust支持与各种数据库交互,包括SQL和NoSQL,确保数据可以可靠地存储和快速检索。SQL数据库的diesel和MongoDB的mongodb等库提供了必要的抽象。
例子:
use diesel::prelude::*;
use diesel::sqlite::SqliteConnection;
fn establish_connection() -> SqliteConnection {
SqliteConnection::establish("test.db").expect("Error connecting to database")
}
fn main() {
let connection = establish_connection();
// Insert and query data using Diesel ORM
}4,数据服务
使用serde以及强大而简单的API框架(如axum),可以简单的进行序列化和反序列化操作,以有效地提供数据,使得为数据请求提供API服务变得容易。
例子:
use axum::{routing::get, Json, Router};
use serde::Serialize;
use std::net::SocketAddr;
#[derive(Serialize)]
struct HelloWorld {
message: String,
}
#[tokio::main]
async fn main() {
let app = Router::new().route("/", get(hello_world));
let addr = SocketAddr::from(([127.0.0.1], 3000));
axum::Server::bind(&addr)
.serve(app.into_make_service())
.await
.unwrap();
}
async fn hello_world() -> Json<HelloWorld> {
Json(HelloWorld {
message: "Hello, World!".to_string(),
})
}5,数据挖掘
数据分析通常需要处理大型数据集和执行复杂的计算。Rust的数据操作库(如polars)越来越多地用于这些任务,并且比现有的Python库(如pandas)更加高效和高性能。
例子:
use polars::prelude::*;
use std::fs::File;
use std::io::BufReader;
fn main() -> Result<()> {
let file = File::open("path/to/your/data.csv").expect("Failed to open file");
let reader = BufReader::new(file);
let df = CsvReader::new(reader)
.infer_schema(None)
.has_header(true)
.finish()?;
// Print the first few rows of the DataFrame
println!("DataFrame preview:");
println!("{:?}", df.head(Some(5)));
// Example: Calculate the mean and sum of a column named "value"
let mean_value = df
.lazy()
.select([col("value").mean().alias("mean_value")])
.collect()?
.column("mean_value")?
.get(0);
println!("Mean of 'value' column: {:?}", mean_value);
let sum_value = df
.lazy()
.select([col("value").sum().alias("sum_value")])
.collect()?
.column("sum_value")?
.get(0);
println!("Sum of 'value' column: {:?}", sum_value);
// Example: Group by a column named "category" and calculate aggregate metrics
let grouped_df = df
.lazy()
.groupby([col("category")])
.agg([
col("value").mean().alias("mean_value"),
col("value").sum().alias("sum_value"),
col("value").count().alias("count"),
])
.collect()?;
println!("Grouped DataFrame with aggregate metrics:");
println!("{:?}", grouped_df);
Ok(())
}数据工程的游戏规则改变者:DataFusion
DataFusion是Rust数据工程生态系统中最突出的项目之一,它是一个可扩展的查询执行框架。DataFusion为构建高性能的分布式数据处理系统提供了基础,是Apache Arrow生态系统的一部分,它专注于内存中的列数据处理。
DataFusion的主要优点
1,内存处理:DataFusion利用Apache Arrow的列式进行内存处理,与传统的基于行的存储相比,这大大加快了分析查询的速度。
2,SQL支持:DataFusion支持SQL,使熟悉基于SQL数据操作的广泛用户可以访问它。
3,可扩展性:它的模块化设计允许开发人员可以根据他们的特定需求扩展和定制它,添加对新数据源、自定义函数等的支持。
4,并发性和并行性:DataFusion基于Rust,自然继承了Rust在并发性和并行性方面的优势,能够在大型数据集上高效地执行复杂查询。
为了说明如何使用DataFusion,我们看一个需要在大型数据集上执行SQL查询的场景:
use datafusion::prelude::*;
use arrow::record_batch::RecordBatch;
#[tokio::main]
async fn main() -> datafusion::error::Result<()> {
// 创建一个新的执行上下文
let mut ctx = ExecutionContext::new();
// 注册CSV文件
ctx.register_csv("example", "path/to/csv/file", CsvReadOptions::new()).await?;
// 执行SQL查询
let df = ctx.sql("SELECT * FROM example WHERE column_name > 100").await?;
// 收集结果
let batches: Vec<RecordBatch> = df.collect().await?;
// Print the results
for batch in batches {
println!("{:?}", batch);
}
Ok(())
}由于DataFusion的出现,新的库如ballista将取代Spark在数据处理方面的地位,Ballista是一个用Rust编写的分布式计算平台,专为高性能、大规模数据处理而设计。它利用Apache Arrow实现高效的内存列数据表示,利用DataFusion实现查询执行,允许开发人员以分布式方式执行复杂的数据转换和分析。
Ballista旨在为传统的大数据框架(如Apache Spark)提供一个现代的、可扩展的替代方案,重点关注安全性、并发性和性能。
例子:
use ballista::prelude::*;
use tokio;
#[tokio::main]
async fn main() -> Result<()> {
// 创建一个Ballista上下文
let ctx = BallistaContext::local();
// 注册CSV文件
ctx.register_csv("example", "path/to/your/data.csv", CsvReadOptions::new()).await?;
// 执行SQL查询
let df = ctx.sql("SELECT * FROM example WHERE some_column > 100").await?;
// 收集并打印结果
let batches = df.collect().await?;
for batch in batches {
println!("{:?}", batch);
}
Ok(())
}总结
Rust提供了令人信服的安全性、高性能和高并发性的结合,使其成为现代数据工程任务的有力候选者,它对于数据工程的各种任务都非常有用。