深度解读UUID:结构、原理以及生成机制
What 是 UUID
UUID (Universally Unique IDentifier) 通用唯一识别码 ,也称为 GUID (Globally Unique IDentifier) 全球唯一标识符。
UUID是一个长度为128位的标志符,能够在时间和空间上确保其唯一性。UUID最初应用于Apollo网络计算系统,随后在Open Software Foundation(OSF)的分布式计算环境(DCE)中得到应用。可让分布式系统可以不借助中心节点,就可以生成唯一标识, 比如唯一的ID进行日志记录。
并被微软Windows平台采用。 Windows 举例2个使用场景:
- COM组件通过GUID 来定义类标识符(CLSID)、接口标识符(IID)以及其他重要的标识,确保在整个系统中不会发生命名冲突。
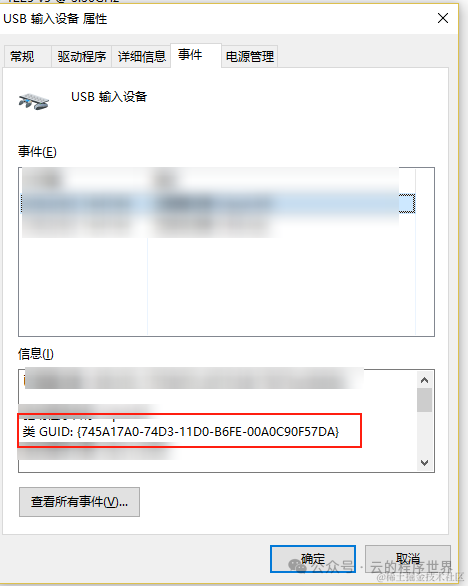
- Windows注册表中很多项都使用GUID作为子键名,以便为特定程序或功能提供一个全球唯一的注册表路径。
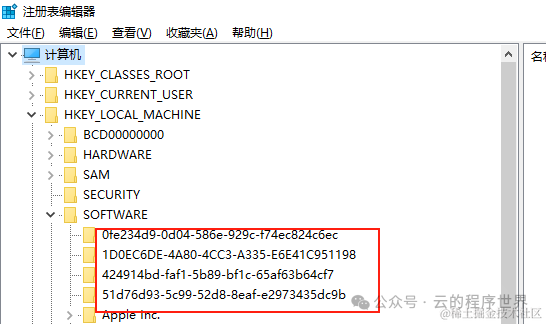
UUID之所以被广泛采用,主要原因之一是它们的分配不需要中心管理机构介入。其具有唯一性和持久性,它们非常适合用作统一资源名称(URN)。UUID能够无需注册过程就能生成新的标识符的独特优点,使得UUID成为创建成本最低的URN类型之一。
那么UUID会重复嘛,由于UUID具有固定的大小并包含时间字段,在特定算法下,随着时间推移,理论上在大约公元3400年左右会出现值的循环,所以问题不大。
由于UUID是一个128位的长的标志符,为了便于阅读和显示,通常会将这个大整数转换成32(不包含连接符)个十六进制字符组成的字符串形式。如下
crypto.randomUUID()
// 4d93f326-3f48-4a43-929d-b6489f4754b5
`${crypto.randomUUID()}`.length
// 长度:36
`${crypto.randomUUID()}`.replace(/-/g, '').length
// 去掉连接符:32这128位的组成,以及是怎么变成32位的十六进制字符的,继续往下看:
UUID 的结构
UUID看似杂乱无章,其实内有乾坤,慢慢道来。
必须了解的
- 比特(bit):二进制数字系统中的基本单位。一个比特可以代表二进制中的一个0或1。
- 位(通常情况下与比特同义):二进制数系统中的一位,同样表示0或1。
- 字节(Byte):字节是计算机中更常用的单位,用于衡量数据存储容量和传输速率。1字节等于8个比特。
总结起来就是:
- 1 字节 = 8 位
- 1 位 = 1 比特
128位转为32个十六进制字符, 这个十六进制字符是什么呢,其专业名字为hexDigit,是UUID中我们肉眼可见的最小单元。
hexDigit
hexDigit , 十六进制数字字符,是一个长度为4比特,可以表示0(0b000)到15(0b1111)之间数值。其能转为16进制的相对应符号,其取值范围为 0-9,a-f, A-F, 即0123456789abcdefABCDEF某一个值。
所以, hexDigit 可以粗暴的理解为 0123456789abcdefABCDEF某一个值。
(0b1000).toString(16) // 8
(0b1111).toString(16) // F此外,还有一个hexOctet, 两个连续hexDigit组成的序列, 占8个比特,即一个字节。
UUID基本结构
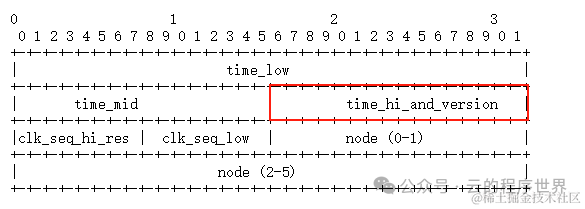
在协议 RFC 4122: A Universally Unique IDentifier (UUID) URN Namespace[1] 的 4.1.2. Layout and Byte Order[2] 有结构图:
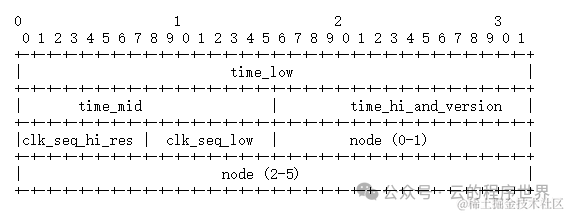
这个图有点小迷惑, 最上面的 0,1,2,3 不是表示位数,就是简单的表示10位数的值,9之后就是 10, 11, 12等等。
这图不太好理解,换一张手工画的图(UUID 10类型的V4版本):10类型和V4版本后续会解释
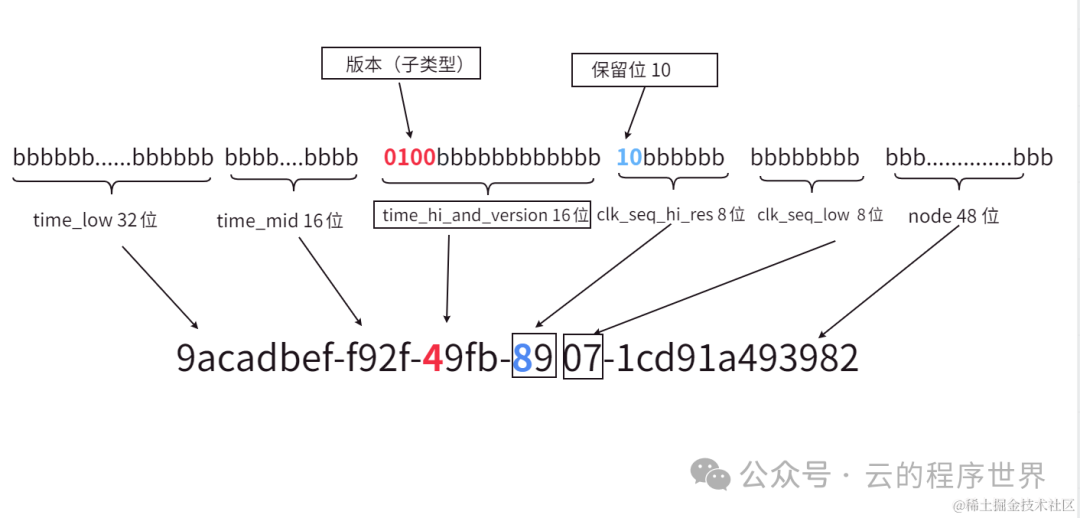
128比特,16个字节即 16 hexOctet,就被如下瓜分了。
| 字段 | hexOctet(字节) | 位置 | 备注 |
|---|---|---|---|
| time_low | 4 | 0-3 | 时间戳的低位部分 |
| time_mid | 2 | 4-5 | 时间戳的中间部分 |
| time_hi_and_version | 2 | 6-7 | 版本4位则用来标识UUID的版本号时间戳高位部分与字段,其中12位代表时间戳的高12位, |
| clock_seq_hi_and_reserved | 1 | 8 | 时钟序列保留位高位与 |
| clock_seq_low | 1 | 9 | 时钟序列低位 |
| node | 6 | 10-15 | 节点标识符,提供空间唯一性,通常基于MAC地址或随机数生成,以确保全局范围内的唯一性 |
要想完整理解这个 6 部分组成,必然要理解备注中被加粗的几个概念。
保留位,版本, 时间戳, 时钟序列 ,节点标志符。
类型(变体) 和保留位
UUID可以分为四种类型(变体),怎么识别是哪种类型(变体呢),UUID有对应的Variant字段去标记,可以参见协议的 4.1.1. Variant[3]部分。
variant字段位于UUID的第8个字节 即 clock_seq_hi_and_reserved 部分的第6-7位。
以外所有其他位的含义都是依据variant字段中的比特位设置来解读的。从这个意义上讲,variant字段更准确地说可以被称作类型字段;然而为了与历史文档兼容,仍沿用“variant”这一术语。
下表列出了variant字段可能的内容,其中字母"x"表示无关紧要或不关心的值:
- Msb0(最高有效位0):此为最高位。
- Msb1:次高位。
- Msb2:第三高位。
| Msb0 | Msb1 | Msb2 | 描述 |
|---|---|---|---|
| 0 | x | x | 保留,用于NCS(Network Computing System)向后兼容 |
| 1 | 0 | x | 此文档中指定的variant变体 |
| 1 | 1 | 0 | 保留,用于微软公司系统的向后兼容 |
| 1 | 1 | 1 | 保留供未来定义 |
类型(变体)的标志符可以是 2位也可是3位,本文围绕的的是 RFC4122: A Universally Unique IDentifier (UUID) URN Namespace[4] 类型(变体), 即上面表格的第二行,其第三高位 为 x,表示该值并无意义,所以该版本只需要10 即可。
10开头的 hexDigit 十六进制数字字符,其只有四个值。
0b1000 => 8
0b1001 => 9
0b1010 => a
0b1011 => b用简单的图示表示,就是 下面y的部分只会是这 四个值 8, 9, a, b其中的某个值。
xxxxxxxx-xxxx-xxxx-yxxx-xxxxxxxxxxxx
简单测一测,
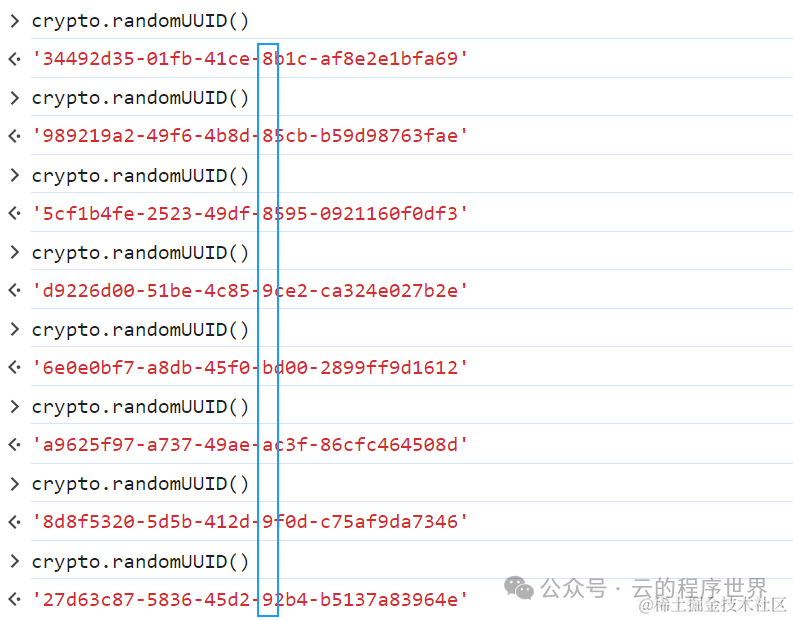
所以呢,一个RFC4122[5]版本的 UUID正宗不正宗,这么验证也是一种手段。
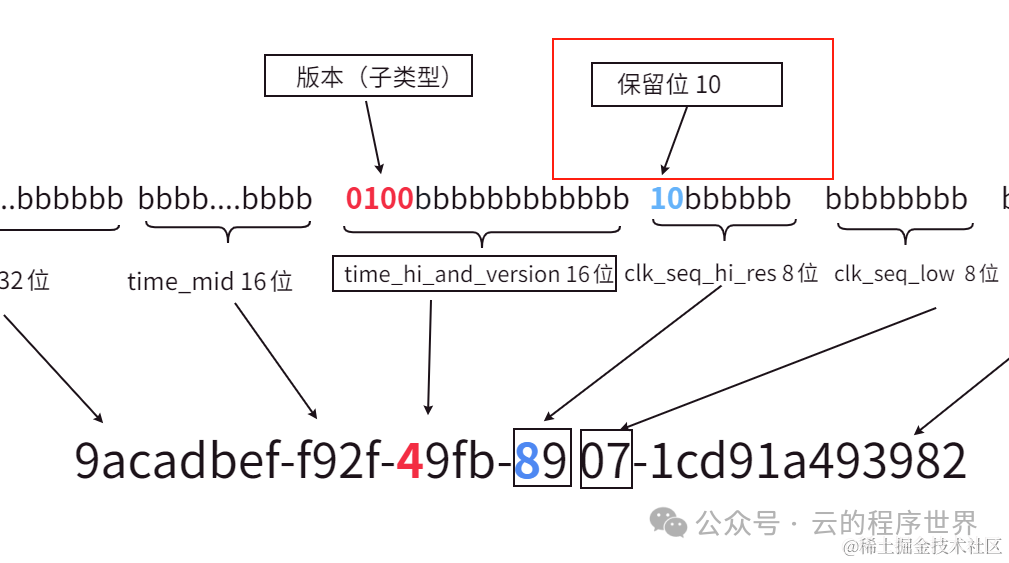
版本(子类型)
上面提到了UUID的类型(变体), 而这里版本,可以理解为某个类型(变体)下的不同子类型。 当然本文讨论的是 变体 10 即RFC4122[6] 下的版本(子类型)。 UUID的类型(变体)有字段标记,当然 这里的版本也有。
即版本号time_hi_and_version 的第12至15位
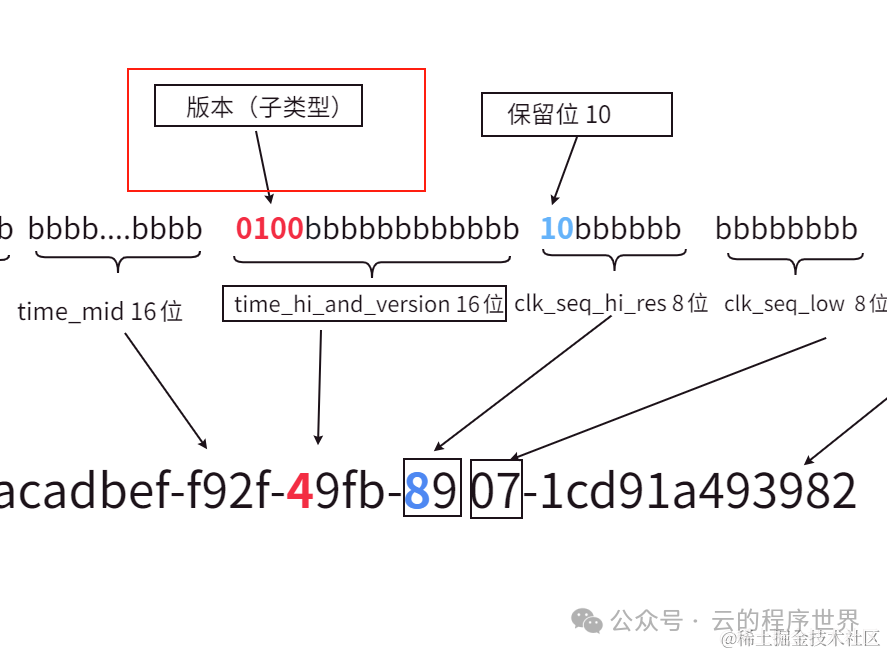
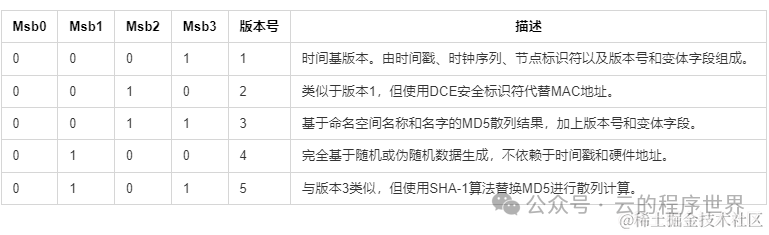
V的部分只会是这 五个值 1, 2, 3, 4, 5其中的某个值。
xxxxxxxx-xxxx-Vxxx-yxxx-xxxxxxxxxxxx
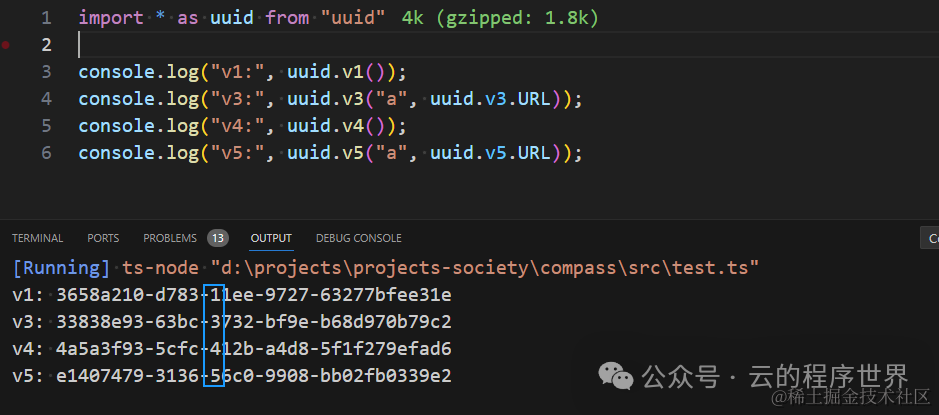
借用uuid 库演示一下:
时间戳
先回顾一下两张图

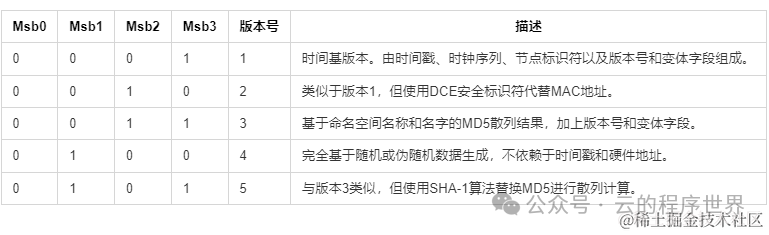
第一张是UUID 各部分的组成,time_low ,time_mid, time_hi_and_version 包含了时间戳的不同部分。
第二张是UUID的五个版本,但是只有 V1 和 V2 提到了时间戳,也确实是这样,除了V1和V2版本真正用了时间戳,其余版本通过不同手段生成了数据填充了time_low ,time_mid, time_hi_and_version 这三个部分。
那这个时间戳 是 开发者们 常用的 Date.now() 这个时间戳嘛, 答案当然不是。
这里的时间戳是一个60位长度的数值。对于UUID版本1和2,它通过协调世界时(UTC)表示,即从1582年10月15日0点0分0秒开始算起的100纳秒间隔计数。
比如 2024年1月1日0时0分0秒,这个值时间戳怎么算呢
const startOfUuidEpoch = new Date('1582-10-15T00:00:00.000Z');
const uuidTimestampFromDate = (date) => {
// 直接计算给定日期距离UUID纪元开始的毫秒数
const msSinceUuidEpoch = date.getTime() - startOfUuidEpoch.getTime();
// 将毫秒转换为100纳秒的整数倍, 1 毫秒=1000000 纳秒
const uuidTimestampIn100Ns = Math.floor(msSinceUuidEpoch * 10000); // 每毫秒乘以10,000得到100纳秒
return uuidTimestampIn100Ns;
};
// 计算2024年1月1日对应的UUID V1版本时间戳
const targetDate = new Date('2024-01-01T00:00:00.000Z');
const uuidV1Timestamp = uuidTimestampFromDate(targetDate);
// 139233600000000000要保存为60位, 并划分高位(12),中间(16),低位三部分(32)
uuidV1Timestamp.toString(2).padStart(60,'0')
// 000111101110101010000011100010110100110011001000000000000000
time-high time-mid time-low
000111101110 1010100000111000 10110100110011001000000000000000在不具备UTC功能但拥有本地时间的系统中,只要在整个系统内保持一致,也可以使用本地时间替代UTC。然而,这种方法并不推荐,因为仅需要一个时区偏移量即可从本地时间生成UTC时间。
对于UUID版本3或5,时间戳是一个根据4.3 Algorithm for Creating a Name-Based UUID[7],由名称构建的60位值, V3和V5 区别是在算法上。
而对于UUID版本4,时间戳则是一个随机或伪随机生成的60位值,具体细节参见第4.4 Algorithms for Creating a UUID from Truly Random or Pseudo-Random Numbers[8]
小结一下,
- 时间戳是即从1582年10月15日0点0分0秒开始算起的100纳秒间隔计数,是一个60位值,被分为 高位,中间,低位三部分填充到UUID中。
- 只有V1和V2 真正意义上用了时间戳
- V3和V5 由名字构建而成的60位值
- V4随机或伪随机生成的60位值
时钟序列
时钟序列(clock sequence)用于帮助避免因系统时间被设置回溯或节点ID发生变化时可能出现的重复标识符。
举个实例,手动把系统的时间设置为一个过去的时间,那么就可能导致生成重复的UUID.
协议考虑到了这点,就增加了时钟序列,增加一个变数,让结果不一样,当然如果序列也是不变的,那么还是可能重复,所以这个时钟序列也是会变化的。
如果系统时钟被设置为向前的时间点之前,或者可能已经回溯(例如,在系统关机期间),并且UUID生成器无法确定在此期间没有生成时间戳更大的UUID,则需要更改时钟序列。若已知先前时钟序列的值,可以直接递增;否则应将其设置为一个随机或高质量的伪随机值。
同样,当节点ID发生变化(比如因为网络适配器在不同机器间移动),将时钟序列设置为随机数可以最大限度地降低由于各机器之间微小时间设置差异导致重复UUID的可能性。尽管理论上知道与变更后的节点ID关联的时钟序列值后可以直接递增,但这种情况在实际操作中往往难以实现。
时钟序列必须在其生命周期内首次初始化为随机数,以减少跨系统间的关联性。这提供了最大程度的保护,防止可能会快速在系统间迁移或切换的节点标识符产生问题。初始值不应与节点标识符相关联。
同样的,这个时间序列只在 V1和V2 是真的按照上面的规则或者约定来执行的。
对于UUID版本3或5,时钟序列是一个由第4.3 Algorithm for Creating a Name-Based UUID[9]节描述的名称构建的14位值。
而对于UUID版本4,时钟序列则是一个如第4.4 Algorithms for Creating a UUID from Truly Random or Pseudo-Random Numbers[10]节所述随机或伪随机生成的14位值。
节点标志符
空间唯一节点标识符,用来确保即便在同一时间生成的UUID也能在特定网络或物理位置上保持唯一性。
对于UUID V1,这个节点标识符通常基于网络适配器的MAC地址或者在没有硬件MAC地址可用时由系统自动生成一个伪随机数。它的目的是反映生成UUID的设备在网络或物理空间中的唯一性,即使在相同的时序和时钟序列条件下,不同的设备也会因为其独特的节点标识符而产生不同的UUID。
在UUID V2中,虽然不常用,但节点标识符的概念同样适用,用于标识系统的唯一性,只不过这里的“空间”更多地指向组织结构或其他逻辑意义上的空间划分。
总之,空间唯一节点标识符是为了保证在分布式系统环境下,即使时间戳相同的情况下也能生成唯一的UUID,以区分不同物理节点上的事件或资源。
对于UUID版本3或5: 节点字段(48位)是根据第4.3节描述的方法,从一个名称构造而来。 对于UUID版本4: 节点字段(同样是48位)是一个随机或伪随机生成的值。
小结
从V1和V2版本来看, UUID最后是想通过 时间和空间 上两层手段保证其唯一性:
- 时间: 时间戳 + 时钟时序
- 空间: 节点标志符(比如MAC地址)
同时考虑了 类型(变体) 和 版本(子类型),即下面这些组信息组成了UUID
- 时间戳
- 时钟序列
- 节点标志符
- 保留位:即类型(变体)信息
- 版本:V1到V5
因为保留位和版本信息本身是固定的,是可以从最后的32位16进制字符是可以直接或者间接看到的。
再回顾这张图,是不是比较清晰了
UUID 的 生成
协议中有具体描述V1, V3和V5, 以及V4的基本流程或者约束。
v4
浏览器和nodejs内置的了V4的生成函数, 而且其生成规则相对简单。 对应着协议 4.4. Algorithms for Creating a UUID from Truly Random or Pseudo-Random Numbers[11]。
版本4的UUID旨在通过真正的随机数或伪随机数生成UUID。其生成算法相对简单,主要依赖于随机性:
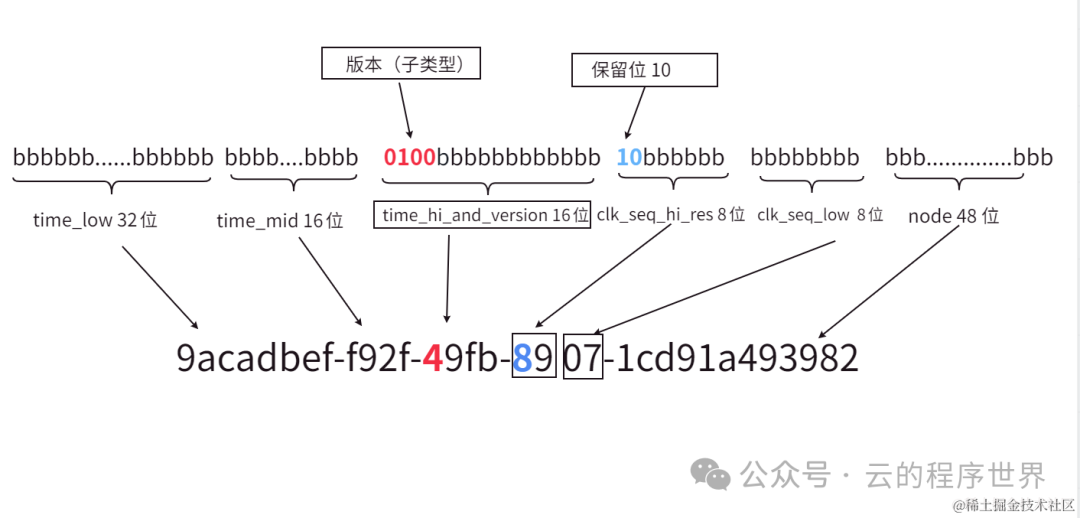
生成算法步骤如下:
- 在UUID结构中的
clock_seq_hi_and_reserved部分,将最高两位有效位(即第6位和第7位)分别设置为0和1。 - 在UUID结构中的
time_hi_and_version字段,将最高四位有效位(即第12位至第15位)设置为来自第 4.1.3节[12] 的4位版本号,对于版本4 UUID,这个版本号是固定的0100。 - 将除了以上已设定的位之外的所有其他位设置为随机(或伪随机)选取的值。
不好理解,就看这张图:
关于随机性安全要求, 引用了BCP 106[13]标准文档,即 RFC 4086[14]。RFC 4086是一份由IETF制定的最佳当前实践(Best Current Practice, BCP)文档,其标题为“Security Requirements for Randomness”,该文档详细阐述了在实现安全协议与系统时所需的随机数生成器的要求和特性,确保生成的随机数具有足够的不可预测性和熵,能满足各类安全应用,包括但不限于密码学应用中的随机性需求。
总之,生成版本4 UUID的过程中,首先对特定字段的几位进行固定设置以标明版本和时钟序列特征,然后其余所有位均通过随机或伪随机过程填充数值,以此确保生成的UUID具备全球唯一性和较强的随机性。
至于v2怎么生成,协议貌似没有提到, v1 , v3 和 v5均有提到,这边就直接翻译过来,有兴趣的可以看看大致逻辑。不敢兴趣的直接跳到后续章节
V1
对应这协议 4.2.2. Generation Details[15] ,按照以下步骤生成的:
- 确定时间戳和时钟序列:遵循第 4.2.1 节描述的方法,获取基于 UTC 的时间戳以及用于 UUID 的时钟序列。
- 处理时间戳和时钟序列:将时间戳视为一个 60 位无符号整数,时钟序列视为一个 14 位无符号整数,并按顺序编号每个字段中的位,最低有效位从0开始计数。
- 设置时间低位字段(time_low field):将其设置为时间戳的最低有效 32 位(位 0 到 31),保持相同的位权重顺序。
- 设置时间中间字段(time_mid field):将其设置为时间戳中的位 32 到 47,同样保持位权重顺序一致。
- 设置时间高位及版本字段(time_hi_and_version field)的低 12 位(位 0 到 11):将其设置为时间戳的位 48 到 59,保持位权重顺序一致。
- 设置时间高位及版本字段的高 4 位:将这 4 位(位 12 到 15)设置为对应于所创建 UUID 版本的 4 位版本号。
- 设置时钟序列低位字段(clock_seq_low field):将其设置为时钟序列的最低有效 8 位(位 0 到 7),同样保持位权重顺序一致。
- 设置时钟序列高位及保留字段的低 6 位(clock_seq_hi_and_reserved field 的位 0 到 5):将其设置为时钟序列的最高有效 6 位(位 8 到 13),保持相同位权重顺序。
- 设置时钟序列高位及保留字段的高 2 位:将这 2 位(位 6 和 7)分别设置为 0 和 1,以满足版本 1 UUID 的标准格式要求。
- 设置节点字段(node field):将其设置为 48 位的 IEEE MAC 地址,地址中的每一位都保持原有的位权重顺序
V3 和 V5
对应协议的 4.3. Algorithm for Creating a Name-Based UUID[16]
版本3或5的UUID设计用于从特定 命名空间(name space) 内的且在该命名空间内唯一的 名字(names) 生成UUID。这里的名字(names)和命名空间(name space)的概念应该广泛理解,不仅限于文本名称。例如,一些命名空间包括域名系统(DNS)、统一资源定位符(URLs)、ISO对象标识符(OIDs)、X.500区别名(DNs)以及编程语言中的保留字等。在这些命名空间内分配名称和确保其唯一性的具体机制或规则不在本规范的讨论范围内。
对于这类UUID的要求如下:
- 在同一命名空间内,使用相同名称在不同时间生成的UUID必须完全相同。
- 在同一命名空间内,使用两个不同名称生成的UUID应当是不同的(概率极高)。
- 在两个不同命名空间内,使用相同名称生成的UUID也应当是不同的(概率极高)。
- 如果两个由名称生成的UUID相同,则它们几乎肯定是由同一命名空间内的相同名称生成的。
生成基于名称和命名空间的UUID的具体算法步骤如下:
- 为给定命名空间内所有由名称生成的UUID分配一个作为“命名空间ID”的UUID;参见附录C[17]中预定义的一些值。
- 选择MD5 [4[18]] 或SHA-1 [8[19]] 其中的一种哈希算法;如果不考虑向后兼容性,建议优先使用SHA-1。
- 将名称转换为其命名空间规定的标准化字节序列形式,并将命名空间ID以网络字节序排列。
- 计算命名空间ID与名称连接后的哈希值。
- 将哈希值的前四个八位组(octets 0-3)赋给时间低位字段(time_low field)的前四个八位组。
- 将哈希值的第五和第六个八位组赋给时间中间字段(time_mid field)的前两个八位组。
- 将哈希值的第七和第八个八位组赋给时间高位及版本字段(time_hi_and_version field)的前两个八位组。
- 将时间高位及版本字段的四位最显著位(bit 12 至 15)设置为第4.1.3节中指定的相应4位版本号。
- 将哈希值的第八个八位组赋给时钟序列高位及保留字段(clock_seq_hi_and_reserved field)。
- 将时钟序列高位及保留字段的两位最显著位(bit 6 和 7)分别设置为0和1。
- 将哈希值的第九个八位组赋给时钟序列低位字段(clock_seq_low field)。
- 将哈希值的第十至第十五个八位组赋给节点字段(node field)的前六个八位组。
- 最后,将生成的UUID转换成本地字节序
获取 UUID V4
这里就只介绍V4版本,因为V4是基于 随机或者伪随机来实现的,只要保证 保留位 和 版本号 的固定,其他的随机生成就好。
正则 + Math.random
利用Math.random() 方法生成随机数。
function uuidv4() {
return 'xxxxxxxx-xxxx-4xxx-yxxx-xxxxxxxxxxxx'.replace(/[xy]/g, function(c) {
var r = (Math.random() * 16 | 0), v = c == 'x' ? r : (r & 0b0011 | 0b1000);
return v.toString(16);
});
}先固定好格式,执行replace,整体代码不难,唯一需要提一下的是 (r & 0b0011 | 0b1000) 操作,这里的作用就是设置保留位的值10
r & 0b0011 // 高位,即2,3位 变为 00
r & 0b0011 | 0b1000 // 高位,即2,3位 变为 10举个例子, 用9为例,其二进制 0b1001 &
0b1001 & 0b0011 => 0b0011
0b0011 | 0b1000 => 0b1011crypto.randomUUID
现代浏览器也内置 Crypto: randomUUID() method[20] , nodejs 15.6.0 版本以上就内置了crypto.randomUUID([options])[21]
crypto.randomUUID()
// 4d93f326-3f48-4a43-929d-b6489f4754b5URL.createObjectURL
function uuid() {
const url = URL.createObjectURL(new Blob([]));
// const uuid = url.split("/").pop();
const uid = url.substring(url.lastIndexOf('/')+ 1);
URL.revokeObjectURL(url);
return uid;
}
uuid()
// blob:http://localhost:3000/ff46f828-1570-4cc9-87af-3d600db71304上面方式产生的都是 v4版本,如果v4版本满足需求,就没有必要去引入第三方库了。
你是否真的需要UUID
在前端,有序后需要给数据添加一个id作为组件的key,这时候理大多数情况是不需要UUID, 也许下面的函数就满足了你的需求。
let id = 0;
function getId () {
return id++;
}后起之秀 NanoID
npm网站, NanoID是这么自我介绍的:
Nano ID 是一个精巧高效的 JavaScript 库,用于生成短小、唯一且适合放在 URL 中的标识符字符串。这个工具提供了几个关键特性:
- 体积小巧:Nano ID 的最小化和压缩版本非常紧凑,大小仅为 116 字节。
- 安全性:该库使用硬件随机数生成器来确保生成的 ID 具有高安全性,可以在集群环境中安全使用。
- 短小 ID:相较于 UUID(通常包含 A-Z、a-z、0-9 以及 - 符号,共 36 个字符),Nano ID 使用了更大的字符集(包括 A-Za-z0-9_-),从而将 ID 的长度从 36 个符号减少到了 21 个,更便于在有限空间中使用。
- 可移植性:Nano ID 已被移植到超过 20 种编程语言中,具有良好的跨平台适用性。
从最新的一周的下载量来对比,首先都是绝对的热门库,其次NanoID势头很盛。
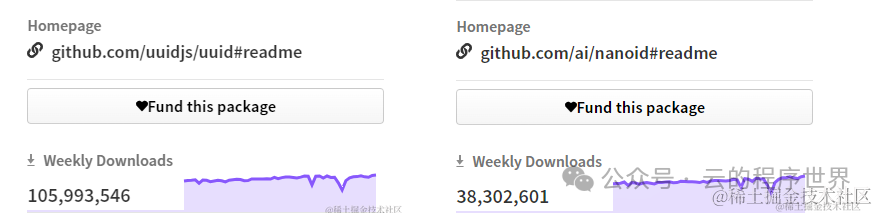
借用 阿通 给的对比文案:
Nano ID 和 UUID(Universally Unique Identifier)都是用于生成唯一标识符的机制,但它们之间存在一些关键差异:
- 长度与格式:
- UUID:标准UUID由32个十六进制数字组成,分为5组,每组之间用短横线
-分隔,例如xxxxxxxx-xxxx-Mxxx-Nxxx-xxxxxxxxxxxx,总长度为36个字符(包括连字符)。 - Nano ID:Nano ID 可配置长度,但默认生成的是较短的字符串,通常包含21个字符,并且可以自定义字符集(默认为
A-Za-z0-9_-)。
- 唯一性保证:
- UUID:基于时间戳、MAC地址(对于v1 UUID)、随机数(对于v4 UUID)等多种因素生成,理论上全球范围内几乎不可能重复。
- Nano ID:虽然也致力于生成唯一的ID,但由于其较短的长度,在没有额外存储或算法保证的情况下,唯一性风险相对较大。不过,通过增大字符集和适当增加ID长度,Nano ID也能实现很高的唯一性概率。
- 应用场景:
- UUID:广泛应用于数据库键、资源标识符、网络协议等需要全局唯一性的场景,尤其在网络间不同系统间的交互中常见。
- Nano ID:更适合于对ID长度要求严格的场合,如URL友好、前端显示或者存储空间有限的情况。
- 性能与存储成本:
- UUID:由于较长的字符串长度,存储和传输时可能会占用更多空间。
- Nano ID:因其短小,Nano ID在存储和带宽消耗上更有优势。
- 安全性:
- UUID v4 是基于强随机性生成的,因此安全性较高,不易被预测。
- Nano ID 也可以使用安全的随机源生成,同样能够达到较高的安全性,但在默认设置下,考虑到生成长度和字符集的选择,如果不在生成逻辑上做特殊处理以增加熵,其安全性可能不及UUID。
综上所述,选择Nano ID还是UUID取决于具体的应用需求,如果重视存储效率和简洁性,同时能接受合理的唯一性保证策略,则Nano ID可能更为合适;而在需要绝对唯一性和不考虑存储效率的场景下,UUID往往是更好的选择。
参考资料
- [1] RFC 4122: A Universally Unique IDentifier (UUID) URN Namespace: https://www.rfc-editor.org/rfc/rfc4122
- [2] 4.1.2. Layout and Byte Order: https://www.rfc-editor.org/rfc/rfc4122#section-4.1.2
- [3] 4.1.1. Variant: https://www.rfc-editor.org/rfc/rfc4122#section-4.1.1
- [4] RFC4122: A Universally Unique IDentifier (UUID) URN Namespace: https://www.rfc-editor.org/rfc/rfc4122
- [5] RFC4122: https://www.rfc-editor.org/rfc/rfc4122
- [6] RFC4122: https://www.rfc-editor.org/rfc/rfc4122
- [7] 4.3 Algorithm for Creating a Name-Based UUID: https://www.rfc-editor.org/rfc/rfc4122#section-4.3
- [8] 4.4 Algorithms for Creating a UUID from Truly Random or Pseudo-Random Numbers: https://www.rfc-editor.org/rfc/rfc4122#section-4.4
- [9] 4.3 Algorithm for Creating a Name-Based UUID: https://www.rfc-editor.org/rfc/rfc4122#section-4.3
- [10] 4.4 Algorithms for Creating a UUID from Truly Random or Pseudo-Random Numbers: https://www.rfc-editor.org/rfc/rfc4122#section-4.4
- [11] 4.4. Algorithms for Creating a UUID from Truly Random or Pseudo-Random Numbers: https://www.rfc-editor.org/rfc/rfc4122#section-4.4
- [12] 4.1.3节: https://www.rfc-editor.org/rfc/rfc4122#section-4.1.3
- [13] BCP 106: https://www.rfc-editor.org/info/bcp106
- [14] RFC 4086: https://www.rfc-editor.org/rfc/rfc4086
- [15] 4.2.2. Generation Details: https://www.rfc-editor.org/rfc/rfc4122#section-4.2.2
- [16] 4.3. Algorithm for Creating a Name-Based UUID: https://www.rfc-editor.org/rfc/rfc4122#section-4.3
- [17] 附录C: https://www.rfc-editor.org/rfc/rfc4122#appendix-C
- [18] [4: https://www.rfc-editor.org/rfc/rfc4122#ref-4
- [19] [8: https://www.rfc-editor.org/rfc/rfc4122#ref-8
- [20] Crypto: randomUUID() method: https://developer.mozilla.org/en-US/docs/Web/API/Crypto/randomUUID
- [21] crypto.randomUUID([options]): https://nodejs.org/docs/latest/api/crypto.html#cryptorandomuuidoptions
- [22] RFC4122: A Universally Unique IDentifier (UUID) URN Namespace: https://www.rfc-editor.org/rfc/rfc4122
- [23] UUID那些事: https://www.cnblogs.com/yjf512/p/9045341.html