C++使用ProtoBuf实现序列化操作
在移动互联网时代,手机流量、电量是最为有限的资源,而移动端的即时通讯应用无疑必须得直面这两点。解决流量过大的基本方法就是使用高度压缩的通信协议,而数据压缩后流量减小带来的自然结果也就是省电:因为大数据量的传输必然需要更久的网络操作、数据序列化及反序列化操作,这些都是电量消耗过快的根源。
当前即时通讯应用中最热门的通信协议无疑就是Google的Protobuf了,基于它的优秀表现,微信和手机QQ这样的主流IM应用也早已在使用它。本文将详细介绍Protobuf的使用、原理等。
protobuf(protocol buffer)是一种高效的二进制协议缓冲区,用于在计算机之间传输数据。它由谷歌开发并开源,现已成为数据传输领域的事实标准之一。本文将介绍protobuf的概念、应用场景、基本原理以及使用方法,带你轻松入门protobuf世界。
一、protobuf简介
Protobuf是Protocol Buffers的简称,它是Google公司开发的一种数据描述语言,是一种轻便高效的结构化数据存储格式,可以用于结构化数据串行化,或者说序列化 。它很适合做数据存储或 RPC 数据交换格式。可用于通讯协议、数据存储等领域的语言无关、平台无关、可扩展的序列化结构数据格式。目前提供了 C++、Java、Python 三种语言的 API。
- protobuf是类似与json一样的数据描述语言(数据格式)
- protobuf非常适合于RPC数据交换格式
注意:protobuf本身并不是和gRPC绑定的。它也可以被用于非RPC场景,如存储等。
protobuf的优劣势
1)优势:
- 序列化后体积相比Json和XML很小,适合网络传输
- 序列化反序列化速度很快,快于Json的处理速度
- 消息格式升级和兼容性还不错
- 支持跨平台多语言
2)劣势:
- 应用不够广(相比xml和json)
- 二进制格式导致可读性差
- 缺乏自描述
protoc安装(windows)
protoc就是protobuf的编译器,它把proto文件编译成不同的语言
(1)下载安装protoc编译器(protoc)
下载protobuf:https://github.com/protocolbuffers/protobuf/releases/download/v3.20.1/protoc-3.20.1-win64.zip解压后,将目录中的 bin 目录的路径添加到系统环境变量,然后打开cmd输入protoc查看输出信息,此时则安装成功
(2)安装protocbuf的go插件(protoc-gen-go)
由于protobuf并没直接支持go语言需要我们手动安装相关插件
protocol buffer编译器需要一个插件来根据提供的proto文件生成 Go 代码,Go1.16+要使用下面的命令安装插件:
go install google.golang.org/protobuf/cmd/protoc-gen-go@latest // 目前最新版是v1.3.0(3)安装grpc(grpc)
go get -u -v google.golang.org/grpc@latest // 目前最新版是v1.53.0(4)安装grpc的go插件(protoc-gen-go-grpc)
说明:在http://google.golang.org/protobuf中,protoc-gen-go纯粹用来生成pb序列化相关的文件,不再承载gRPC代码生成功能,所以如果要生成grpc相关的代码需要安装grpc-go相关的插件:protoc-gen-go-grpc
go install google.golang.org/grpc/cmd/protoc-gen-go-grpc@latest // 目前最新版是v1.3.0二、protobuf数据类型
创建 FileName.proto文件,后缀名称必须是.proto。一般一个文件就代表一个 proto对象。在文件中定义 proto 对象的属性。通过 .proto文件可以生成不同语言的类,用于结构化的数据序列化、反序列化。
定义一个 proto 对象的属性,基本格式如下:
字段标签(可选) 字段类型 字段名称 字段标识符 字段默认值(可选)
关于字段编号(标识符),是字段中唯一且必须的,以 1开始,不能重复,不能跳值,这个是和编译有关系的。
2.1基本数据类型
常见基本数据类型:
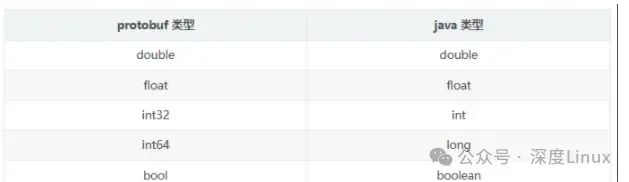
- string:默认为空字符串
- byte:默认值为空字节
- bool:默认为false
- 数值:默认为0
- enum:默认为第一个元素
示例如下:
syntax = "proto3";
//创建一个 SearchRequest 对象
message SearchRequest {
string query = 1;
int32 page_number = 2;
int32 results_per_page = 3;
}(1).proto文件
syntax = "proto3";
//生成 proto 文件所在包路径(一般不指定, 生成java类之后人为手动加即可)
//package com.example.xxx.model;
//生成 proto 文件所在 java包路径(一般不指定,因为生成的java_outer_classname类中使用到它会使用全限定名)
//option java_package = "com.example.xxx.model";
//生成 proto java文件名(一般指定,文件名+自定义。如果不指定,默认时文件名+OuterClass)
option java_outer_classname = "UserProtoBuf";
message User {
int32 age = 1;
int64 timestamp = 2;
bool enabled = 3;
float height = 4;
double weight = 5;
string userName = 6;
string Full_Address = 7;
}生成 Java类。注意:proto没有指定 package xxx; 所以,我们将 java类放到目标包下面时,记得手动导包。
protobuf数据(字节数组)序列化、反序列化。
public class UserTest {
public static void main(String[] args) throws Exception {
// 将数据序列化
byte[] byteData = getClientPush();
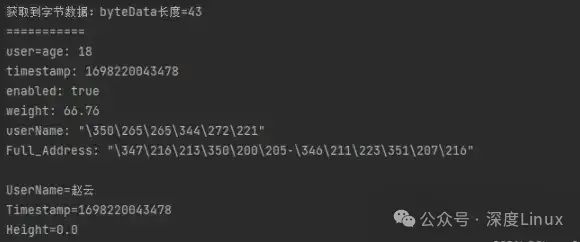
System.out.println("获取到字节数据:byteData长度="+ byteData.length);
System.out.println("===========");
/**
* 接收数据反序列化:将字节数据转化为对象数据。
*/
UserProtoBuf.User user = UserProtoBuf.User.parseFrom(byteData);
System.out.println("user=" + user);
System.out.println("UserName=" + user.getUserName());
System.out.println("Timestamp=" + user.getTimestamp());
System.out.println("Height=" + user.getHeight());
}
/**
* 模拟发送方,将数据序列化后发送
* @return
*/
private static byte[] getClientPush() {
// 按照定义的数据结构,创建一个对象。
UserProtoBuf.User.Builder user = UserProtoBuf.User.newBuilder();
user.setAge(18);
user.setTimestamp(System.currentTimeMillis());
user.setEnabled(true);
//user.setHeight(1.88F);
user.setWeight(66.76D);
user.setUserName("赵云");
user.setFullAddress("王者-打野");
/**
* 发送数据序列化:将对象数据转化为字节数据输出
*/
UserProtoBuf.User userBuild = user.build();
byte[] bytes = userBuild.toByteArray();
return bytes;
}
}
2.2复杂数据类型
下面通过 Java数据类型来理解定义的 proto属性。并引入 protobuf-java依赖:
<!-- https://mvnrepository.com/artifact/com.google.protobuf/protobuf-java -->
<dependency>
<groupId>com.google.protobuf</groupId>
<artifactId>protobuf-java</artifactId>
<version>3.19.1</version>
</dependency>(1)集合List字段
Java String、Integer List 在 protobuf 的定义。
message User{
//list Int
repeated int32 intList = 1;
//list String
repeated string strList = 2;
}(2)Map字段
Java String、Integer Map 在 protobuf 的定义。
message User{
// 定义简单的 Map string
map<string, int32> intMap = 7;
// 定义复杂的 Map 对象
map<string, string> stringMap = 8;
}(3)对象字段
Java 对象 List 在 protobuf 的定义。
message User{
//list 对象
repeated Role roleList = 6;
}(4)Map对象值字段
Java 对象 Map 在 protobuf 的定义。
message User{
// 定义复杂的 Map 对象
map<string, MapVauleObject> mapObject = 8;
}
// 定义 Map 的 value 对象
message MapVauleObject {
string code = 1;
string name = 2;
}(5) 嵌套对象字段
Java 实体类中使用另一个实体类作为字段在 protobuf 的定义。
message User{
// 对象
NickName nickName = 4;
}
// 定义一个新的Name对象
message NickName {
string nickName = 1;
}三、protobuf的使用流程
(1)protobuf在Linux下的安装过程
$ sudo apt-get install autoconf automake libtool curl make g++ unzip
$ git clone https://github.com/google/protobuf.git
$ cd protobuf
$ git submodule update --init --recursive
$ ./autogen.sh
$ ./configure
$ make
$ make check
$ sudo make install
$ sudo ldconfig(2)定义proto文件
message Person {
string name = 1;
int32 id = 2;
string email = 3;
enum PhoneType {
MOBILE = 0;
HOME = 1;
WORK = 2;
}
message PhoneNumber {
string number = 1;
PhoneType type = 2;
}
repeated PhoneNumber phone = 4;
}message是消息体,包含了多个fields(数据项),每一个fields都是key-value类型。
(3)protoc编译器
使用proto文件定义好结构数据后,可以使用protoc编译器生成结构数据的源代码,这些源代码提供了读写结构数据的接口,从而能够构造、初始化、读取、序列化、反序列化结构数据。使用以下命令生成相应的接口代码:
// $SRC_DIR: .proto所在的源目录
// --cpp_out: 生成C++代码
// $DST_DIR: 生成代码的目标目录
// xxx.proto: 要针对哪个proto文件生成接口代码
protoc -I=$SRC_DIR --cpp_out=$DST_DIR $SRC_DIR/xxx.proto编译完成后将会生成一个xxx.pb.h和xxx.pb.cpp文件,会提供类似SerializeToOstream()、set_name()、name()等方法。
(4)调用接口进行序列化、反序列化
/*
下面的代码即为protoc编译器生成的原结构数据的接口,
提供了构造函数、初始化、序列化、反序列化和读取数据的方法,
因此可以调用这些接口进行序列化与反序列化。
*/
// 构造函数
Person person;
// 初始化
person.set_name("John Doe");
person.set_id(1234);
person.set_email("jdoe@example.com");
fstream output("myfile", ios::out | ios::binary);
// 序列化结构数据到文件中
person.SerializeToOstream(&output);
fstream input("myfile", ios::in | ios::binary);
Person person;
// 从文件中反序列化出结构数据
person.ParseFromIstream(&input);
// 读取结构数据
cout << "Name: " << person.name() << endl;
cout << "E-mail: " << person.email() << endl;四、protobuf的应用场景
- 网络通信:Protobuf 可以在客户端和服务器之间进行高效的数据传输,减少网络带宽和处理时间的开销。
- 数据存储:Protobuf 可以将结构化数据序列化为二进制格式,使得数据在存储和读取过程中更加紧凑、高效,并且具备跨平台的特性。
- 分布式系统:Protobuf 在分布式系统中可以作为消息传递的格式,实现不同节点之间的通信和数据交换。
- 配置文件:Protobuf 可以作为配置文件格式使用,在各种软件或系统中定义配置选项,并且方便解析和修改。
- 日志记录:通过使用 Protobuf 格式记录日志,可以减少磁盘空间占用并提高日志记录和分析的效率。
- RPC(远程过程调用):Protobuf 提供了与多种 RPC 框架集成的支持,例如 gRPC。通过定义服务接口和消息格式,实现跨进程、跨语言的方法调用
五、C++使用protobuf实现序列化的示例
在protobuf源码中的 /examples 目录下有官方提供的protobuf使用示例:addressbook.proto
参考官方示例实现C++使用protobuf进行序列化和反序列化 addressbook.proto :
syntax = "proto3";
package tutorial;
option optimize_for = LITE_RUNTIME;
message Person {
string name = 1;
int32 id = 2;
string email = 3;
enum PhoneType {
MOBILE = 0;
HOME = 1;
WORK = 2;
}
message PhoneNumber {
string number = 1;
PhoneType type = 2;
}
repeated PhoneNumber phones = 4;
}生成的addressbook.pb.h 文件内容摘要:
namespace tutorial {
class Person;
class Person_PhoneNumber;
};
class Person_PhoneNumber : public MessageLite {
public:
Person_PhoneNumber();
virtual ~Person_PhoneNumber();
public:
//string number = 1;
void clear_number();
const string& number() const;
void set_number(const string& value);
//int32 id = 2;
void clear_id();
int32 id() const;
void set_id(int32 value);
//string email = 3;
//...
};add_person.cpp :
#include <iostream>
#include <fstream>
#include <string>
#include "pbs/addressbook.pb.h"
using namespace std;
void serialize_process() {
cout << "serialize_process" << endl;
tutorial::Person person;
person.set_name("Obama");
person.set_id(1234);
person.set_email("1234@qq.com");
tutorial::Person::PhoneNumber *phone1 = person.add_phones();
phone1->set_number("110");
phone1->set_type(tutorial::Person::MOBILE);
tutorial::Person::PhoneNumber *phone2 = person.add_phones();
phone2->set_number("119");
phone2->set_type(tutorial::Person::HOME);
fstream output("person_file", ios::out | ios::trunc | ios::binary);
if( !person.SerializeToOstream(&output) ) {
cout << "Fail to SerializeToOstream." << endl;
}
cout << "person.ByteSizeLong() : " << person.ByteSizLong() << endl;
}
void parse_process() {
cout << "parse_process" << endl;
tutorial::Person result;
fstream input("person_file", ios::in | ios::binary);
if(!result.ParseFromIstream(&input)) {
cout << "Fail to ParseFromIstream." << endl;
}
cout << result.name() << endl;
cout << result.id() << endl;
cout << result.email() << endl;
for(int i = 0; i < result.phones_size(); ++i) {
const tutorial::Person::PhoneNumber &person_phone = result.phones(i);
switch(person_phone.type()) {
case tutorial::Person::MOBILE :
cout << "MOBILE phone : ";
break;
case tutorial::Person::HOME :
cout << "HOME phone : ";
break;
case tutorial::Person::WORK :
cout << "WORK phone : ";
break;
default:
cout << "phone type err." << endl;
}
cout << person_phone.number() << endl;
}
}
int main(int argc, char *argv[]) {
serialize_process();
parse_process();
google::protobuf::ShutdownProtobufLibrary(); //删除所有已分配的内存(Protobuf使用的堆内存)
return 0;
}输出结果:
[serialize_process]
person.ByteSizeLong() : 39
[parse_process]
Obama
1234
1234@qq.com
MOBILE phone : 110
HOME phone : 119protobuf提供的序列化和反序列化的API接口函数:
class MessageLite {
public:
//序列化:
bool SerializeToOstream(ostream* output) const;
bool SerializeToArray(void *data, int size) const;
bool SerializeToString(string* output) const;
//反序列化:
bool ParseFromIstream(istream* input);
bool ParseFromArray(const void* data, int size);
bool ParseFromString(const string& data);
};三种序列化的方法没有本质上的区别,只是序列化后输出的格式不同,可以供不同的应用场景使用,序列化的API函数均为const成员函数,因为序列化不会改变类对象的内容, 而是将序列化的结果保存到函数入参指定的地址中。
.proto文件中的 option 选项:
.proto文件中的option选项用于配置protobuf编译后生成目标语言文件中的代码量,可设置为 SPEED, CODE_SIZE, LITE_RUNTIME 三种。
默认option选项为 SPEED,常用的选项为 LITE_RUNTIME。
三者的区别在于:
① SPEED(默认值):
表示生成的代码运行效率高,但是由此生成的代码编译后会占用更多的空间。
② CODE_SIZE:
与SPEED恰恰相反,代码运行效率较低,但是由此生成的代码编译后会占用更少的空间,
通常用于资源有限的平台,如Mobile。
③ LITE_RUNTIME:
生成的代码执行效率高,同时生成代码编译后的所占用的空间也非常少。
这是以牺牲Protobuf提供的反射功能为代价的。
因此我们在C++中链接Protobuf库时仅需链接libprotobuf-lite,而非protobuf。SPEED 和 LITE_RUNTIME相比,在于调试级别上,例如 msg.SerializeToString(&str); 在 SPEED 模式下会利用反射机制打印出详细字段和字段值,但是 LITE_RUNTIME 则仅仅打印字段值组成的字符串。
因此:可以在调试阶段使用 SPEED 模式,而上线以后提升性能使用 LITE_RUNTIME 模式优化。
最直观的区别是使用三种不同的 option 选项时,编译后产生的 .pb.h 中自定义的类所继承的 protobuf类不同:
//1. SPEED模式:(自定义的类继承自 Message 类)
// .proto 文件:
option optimize_for = SPEED;
// .pb.h 文件:
class Person : public ::PROTOBUF_NAMESPACE_ID::Message {};
//2. CODE_SIZE模式:(自定义的类继承自 Message 类)
// .proto 文件:
option optimize_for = CODE_SIZE;
// .pb.h 文件:
class Person : public ::PROTOBUF_NAMESPACE_ID::Message {};
//3. LITE_RUNTIME模式:(自定义的类继承自 MessageLite 类)
// .proto 文件:
option optimize_for = LITE_RUNTIME;
// .pb.h 文件:
class Person : public ::PROTOBUF_NAMESPACE_ID::MessageLite {};