ART运行时Compacting GC为新创建对象分配内存的过程分析
ART运行时Compacting GC为新创建对象分配内存的过程分析
在引进Compacting GC后,ART运行时优化了堆内存分配过程。最显著特点是为每个ART运行时线程增加局部分配缓冲区(Thead Local Allocation Buffer)和在OOM前进行一次同构空间压缩(Homogeneous Space Compact)。前者可提高堆内存分配效率,后者可解决内存碎片问题。本文就对ART运行时引进Compacting GC后的堆内存分配过程进行分析。
从接口层面上看,除了提供常规的对象分配接口AllocObject,ART运行时的堆还提供了一个专门用于分配非移动对象的接口AllocNonMovableObject,如图1所示:
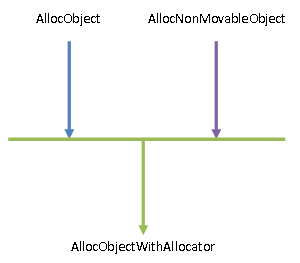
图1 ART运行时堆提供的对象分配接口
非移动对象指的是保存在前面ART运行时Compacting GC堆创建过程分析一篇文章提到的Non-Moving Space的对象,主要包括那些在类加载过程中创建的类对象(Class)、类方法对象(ArtMethod)和类成员变量对象(ArtField)等,以及那些在经历过若干次Generational Semi-Space GC之后仍然存活的对象。前者是通过AllocNonMovableObject接口分配的,而后者是在执行Generational Semi-Space GC过程移动过去的。本文主要关注通过AllocNonMovableObject接口分配的非移动对象。
无论是通过AllocObject接口分配对象,还是通过AllocNonMovableObject接口分配对象,最后都统一调用了另外一个接口AllocObjectWithAllocator进行具体的分配过程,如下所示:
class Heap {
public:
......
// Allocates and initializes storage for an object instance.
template <bool kInstrumented, typename PreFenceVisitor>
mirror::Object* AllocObject(Thread* self, mirror::Class* klass, size_t num_bytes,
const PreFenceVisitor& pre_fence_visitor)
SHARED_LOCKS_REQUIRED(Locks::mutator_lock_) {
return AllocObjectWithAllocator<kInstrumented, true>(self, klass, num_bytes,
GetCurrentAllocator(),
pre_fence_visitor);
}
template <bool kInstrumented, typename PreFenceVisitor>
mirror::Object* AllocNonMovableObject(Thread* self, mirror::Class* klass, size_t num_bytes,
const PreFenceVisitor& pre_fence_visitor)
SHARED_LOCKS_REQUIRED(Locks::mutator_lock_) {
return AllocObjectWithAllocator<kInstrumented, true>(self, klass, num_bytes,
GetCurrentNonMovingAllocator(),
pre_fence_visitor);
}
template <bool kInstrumented, bool kCheckLargeObject, typename PreFenceVisitor>
ALWAYS_INLINE mirror::Object* AllocObjectWithAllocator(
Thread* self, mirror::Class* klass, size_t byte_count, AllocatorType allocator,
const PreFenceVisitor& pre_fence_visitor)
SHARED_LOCKS_REQUIRED(Locks::mutator_lock_);
AllocatorType GetCurrentAllocator() const {
return current_allocator_;
}
AllocatorType GetCurrentNonMovingAllocator() const {
return current_non_moving_allocator_;
}
......
private:
......
// Allocator type.
AllocatorType current_allocator_;
const AllocatorType current_non_moving_allocator_;
......
};这五个函数定义在文件art/runtime/gc/heap.h
在Heap类的成员函数AllocObject和AllocNonMovableObject中,参数self描述的是当前线程,klass描述的是要分配的对象所属的类型,参数num_bytes描述的是要分配的对象的大小,最后一个参数pre_fence_visitor是一个回调函数,用来在分配对象完成后在当前执行路径中执行初始化操作,例如分配完成一个数组对象,通过该回调函数立即设置数组的大小,这样就可以保证数组对象的完整性和一致性,避免多线程环境下通过加锁来完成相同的操作。
Heap类的成员函数AllocObjectWithAllocator需要另外一个额外的类型为AllocatorType的参数来描述分配器的类型,也就是描述要在哪个空间分配对象。AllocatorType是一个枚举类型,它的定义如下所示:
// Different types of allocators.
enum AllocatorType {
kAllocatorTypeBumpPointer, // Use BumpPointer allocator, has entrypoints.
kAllocatorTypeTLAB, // Use TLAB allocator, has entrypoints.
kAllocatorTypeRosAlloc, // Use RosAlloc allocator, has entrypoints.
kAllocatorTypeDlMalloc, // Use dlmalloc allocator, has entrypoints.
kAllocatorTypeNonMoving, // Special allocator for non moving objects, doesn't have entrypoints.
kAllocatorTypeLOS, // Large object space, also doesn't have entrypoints.
};这个枚举类型定义在文件/art/runtime/gc/allocator_type.h。
AllocatorType一共有六个值,它们的含义如下所示:
kAllocatorTypeBumpPointer:表示在Bump Pointer Space中分配对象。
kAllocatorTypeTLAB:表示要在由Bump Pointer Space提供的线程局部分配缓冲区中分配对象。
kAllocatorTypeRosAlloc:表示要在Ros Alloc Space分配对象。
kAllocatorTypeDlMalloc:表示要在Dl Malloc Space分配对象。
kAllocatorTypeNonMoving:表示要在Non Moving Space分配对象。
kAllocatorTypeLOS:表示要在Large Object Space分配对象。
Heap类的成员函数AllocObject和AllocNonMovableObject使用的分配器类型分别是由成员变量current_allocator_和current_non_moving_allocator_决定的。前者的值与当前使用的GC类型有关。当GC类型发生变化时,就会调用Heap类的成员函数ChangeCollector来修改当前使用的GC,同时也会调用另外一个成员函数ChangeAllocator来修改Heap类的成员变量current_allocator_的值。由于ART运行时只有一个Non-Moving Space,因此后者的值就固定为kAllocatorTypeNonMoving。
Heap类的成员函数ChangeCollector的实现如下所示:
void Heap::ChangeCollector(CollectorType collector_type) {
// TODO: Only do this with all mutators suspended to avoid races.
if (collector_type != collector_type_) {
......
collector_type_ = collector_type;
gc_plan_.clear();
switch (collector_type_) {
case kCollectorTypeCC: // Fall-through.
case kCollectorTypeMC: // Fall-through.
case kCollectorTypeSS: // Fall-through.
case kCollectorTypeGSS: {
gc_plan_.push_back(collector::kGcTypeFull);
if (use_tlab_) {
ChangeAllocator(kAllocatorTypeTLAB);
} else {
ChangeAllocator(kAllocatorTypeBumpPointer);
}
break;
}
case kCollectorTypeMS: {
gc_plan_.push_back(collector::kGcTypeSticky);
gc_plan_.push_back(collector::kGcTypePartial);
gc_plan_.push_back(collector::kGcTypeFull);
ChangeAllocator(kUseRosAlloc ? kAllocatorTypeRosAlloc : kAllocatorTypeDlMalloc);
break;
}
case kCollectorTypeCMS: {
gc_plan_.push_back(collector::kGcTypeSticky);
gc_plan_.push_back(collector::kGcTypePartial);
gc_plan_.push_back(collector::kGcTypeFull);
ChangeAllocator(kUseRosAlloc ? kAllocatorTypeRosAlloc : kAllocatorTypeDlMalloc);
break;
}
default: {
LOG(FATAL) << "Unimplemented";
}
}
......
}
}这个函数定义在文件ime/gc/heap.cc中。
从这里我们就可以看到,对于Compacting GC,它们使用的分配器类型只可能为kAllocatorTypeTLAB或者kAllocatorTypeBumpPointer,取决定Heap类的成员变量use_tlab_的值。Heap类的成员变量use_tlab_的值默认为false,但是可以通过ART运行时启动选项-XX:UseTLAB来设置为true。对于Mark-Sweep GC来说,它们使用的分配器类型只可能为kAllocatorTypeRosAlloc或者kAllocatorTypeDlMalloc,取决于常量kUseRosAlloc的值。
此外,我们还可以看到,根据当前使用的GC不同,Heap类的成员变量gc_plan_会被设置为不同的值,用来表示在分配对象过程中遇到内存不足时,应该执行的GC粒度。对于Compacting GC来说,只有一种GC粒度可执行,那就是kGcTypeFull,实际上就是说对Bump Pointer Space的所有不可达对象进行回收。对于Mark-Sweep GC来说,有三种GC粒度可执行,分别是kGcTypeSticky、kGcTypePartial和kGcTypeFull。这三者的含义可以参考前面ART运行时垃圾收集(GC)过程分析一文。后面我们继续对象分配过程时,也可以看到Heap类的成员变量gc_plan_的用途。
Heap类的成员函数ChangeAllocator的实现如下所示:
void Heap::ChangeAllocator(AllocatorType allocator) {
if (current_allocator_ != allocator) {
......
current_allocator_ = allocator;
MutexLock mu(nullptr, *Locks::runtime_shutdown_lock_);
SetQuickAllocEntryPointsAllocator(current_allocator_);
......
}
}这个函数定义在文件ime/gc/heap.cc中。
Heap类的成员函数ChangeAllocator除了设置成员变量current_allocator_的值之外,还会调用函数SetQuickAllocEntryPointsAllocator来修改提供给Native Code的用来分配对象的入口点函数,以便Native Code可以在ART运行时切换GC时使用正常的接口来分配对象。这里所谓的Native Code,就是APK在安装时通过翻译DEX字节码得到的本地机器指令。
了解了分配器的类型之后,接下来我们就继续分析Heap类的成员函数AllocObjectWithAllocator的实现,如下所示:
template <bool kInstrumented, bool kCheckLargeObject, typename PreFenceVisitor>
inline mirror::Object* Heap::AllocObjectWithAllocator(Thread* self, mirror::Class* klass,
size_t byte_count, AllocatorType allocator,
const PreFenceVisitor& pre_fence_visitor) {
......
if (kCheckLargeObject && UNLIKELY(ShouldAllocLargeObject(klass, byte_count))) {
return AllocLargeObject<kInstrumented, PreFenceVisitor>(self, klass, byte_count,
pre_fence_visitor);
}
mirror::Object* obj;
......
if (allocator == kAllocatorTypeTLAB) {
byte_count = RoundUp(byte_count, space::BumpPointerSpace::kAlignment);
}
if (allocator == kAllocatorTypeTLAB && byte_count <= self->TlabSize()) {
obj = self->AllocTlab(byte_count);
......
obj->SetClass(klass);
......
pre_fence_visitor(obj, usable_size);
......
} else {
obj = TryToAllocate<kInstrumented, false>(self, allocator, byte_count, &bytes_allocated,
&usable_size);
if (UNLIKELY(obj == nullptr)) {
bool is_current_allocator = allocator == GetCurrentAllocator();
obj = AllocateInternalWithGc(self, allocator, byte_count, &bytes_allocated, &usable_size,
&klass);
if (obj == nullptr) {
bool after_is_current_allocator = allocator == GetCurrentAllocator();
// If there is a pending exception, fail the allocation right away since the next one
// could cause OOM and abort the runtime.
if (!self->IsExceptionPending() && is_current_allocator && !after_is_current_allocator) {
// If the allocator changed, we need to restart the allocation.
return AllocObject<kInstrumented>(self, klass, byte_count, pre_fence_visitor);
}
return nullptr;
}
}
......
obj->SetClass(klass);
......
pre_fence_visitor(obj, usable_size);
......
}
......
if (AllocatorHasAllocationStack(allocator)) {
PushOnAllocationStack(self, &obj);
}
......
if (AllocatorMayHaveConcurrentGC(allocator) && IsGcConcurrent()) {
CheckConcurrentGC(self, new_num_bytes_allocated, &obj);
}
......
return obj;
}这个函数定义在文件art/runtime/gc/heap-inl.h中。
Heap类的成员函数AllocObjectWithAllocator分配对象的主要逻辑如图2所示:
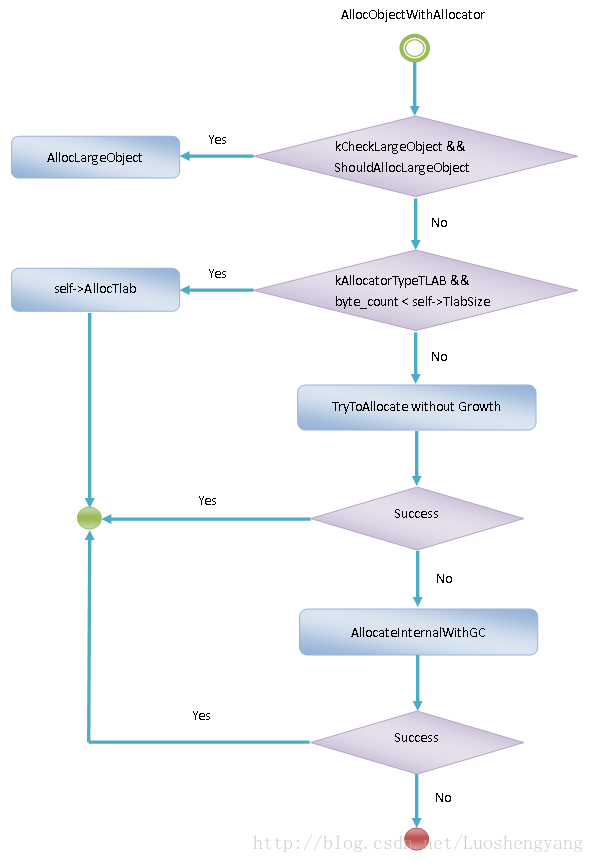
图2 AllocObjectWithAllocator分配对象过程
首先,如果模板参数kCheckLargeObject等于true,并且要分配的是一个原子类型数组,且该为数组的大小大于预先设置的值,那么忽略掉参数allocator,而是调用Heap类的另外一个成员函数AllocLargeObject直接在Large Object Space中分配内存。后一个条件是通过调用Heap类的成员函数ShouldAllocLargeObject来判断是否满足的,它的实现如下所示:
inline bool Heap::ShouldAllocLargeObject(mirror::Class* c, size_t byte_count) const {
// We need to have a zygote space or else our newly allocated large object can end up in the
// Zygote resulting in it being prematurely freed.
// We can only do this for primitive objects since large objects will not be within the card table
// range. This also means that we rely on SetClass not dirtying the object's card.
return byte_count >= large_object_threshold_ && c->IsPrimitiveArray();
}这个函数定义在文件art/runtime/gc/heap-inl.h中。
Heap类的成员变量large_object_threshold_初始化为kDefaultLargeObjectThreshold,后者又定义为3个内存页大小。也就是说,当分配的原子类型数组大小大于等于3个内存页时,就在Large Object Space中进行分配。
回到Heap类的成员AllocObjectWithAllocator中,如果指定了要在当前ART运行时线程的TLAB中分配对象,并且这时候当前ART运行时线程的TLAB的剩余大小大于请求分配的对象大小,那么就直接在当前线程的TLAB中分配。ART运行时线程的TLAB实际上是来自于Bump Pointer Space上的,后面我们就可以看到这一点。
如果上面的条件都不成立,接下来就调用Heap类的成员函数TryToAllocate来进行分配了。Heap类的成员函数TryToAllocate会根据参数allocator,在指定的Space分配内存,同时会根据第二个模板参数来决定是否要在允许的范围内增加Space的大小限制,以便可以满足分配要求。这里指定Heap类的成员函数TryToAllocate的值为false,就表示现在在不增长Space的大小限制的前提下为对象分配内存。
如果Heap类的成员函数TryToAllocate不能成功分配到指定大小的内存,那么就需要调用Heap类的成员函数AllocateInternalWithGc来先执行必要的GC,再尝试分配请求的内存了。
如果Heap类的成员函数AllocateInternalWithGc也不能成功分配到内存,那就表明是分配失败了。不过有一个例外,那就是ART运行时当前使用分配器类型发生了变化,这种情况就需要重新调用Heap类的成员函数AllocObject重启分配过程。从上面的分析可以知道,当ART运行时当前使用的GC发生切换时,ART运行时当前使用的分配器类型也会随着变化,因此这时候重新调用Heap类的成员函数AllocObject,就可以使用当前的分配器来分配对象。
假设前面成功分配了到指定的内存,接下来还有两件事情需要做。
第一件事情是调用Heap类的成员函数AllocatorHasAllocationStack判断参数allocator指定的分配器是否与ART运行时的Allocation Stack有关。如果有关的话,那么就需要将刚才成功分配到的对象通过调用Heap类的成员函数PushOnAllocationStack压入到ART运行时的Allocation Stack中,以便以后可以执行Sticky GC。关于Sticky GC,可以参考前面ART运行时垃圾收集(GC)过程分析一文。
Heap类的成员函数AllocatorHasAllocationStack的实现如下所示:
class Heap {
public:
......
static ALWAYS_INLINE bool AllocatorHasAllocationStack(AllocatorType allocator_type) {
return
allocator_type != kAllocatorTypeBumpPointer &&
allocator_type != kAllocatorTypeTLAB;
}
......
};这个函数定义在文件art/runtime/gc/heap.h中。
前面提到,ART运行时线程的TLAB是来自于Bump Pointer Space的,而Bump Pointer Space是与Compacting GC相关的,Allocation Stack是与Sticky GC相关的,这就意味着Compacting GC不会执行Sticky类型的GC。
第二件事情是调用Heap类的成员函数AllocatorMayHaveConcurrentGC判断参数allocator指定的分配器是否与Concurrent GC相关,并且当前使用的GC就是一个Concurrent GC。如果条件都成立的话,就调用Heap类的成员函数CheckConcurrentGC检查是否需要发起一个Concurrent GC请求。
Heap类的成员函数AllocatorMayHaveConcurrentGC的实现如下所示:
class Heap {
public:
......
static ALWAYS_INLINE bool AllocatorMayHaveConcurrentGC(AllocatorType allocator_type) {
return AllocatorHasAllocationStack(allocator_type);
}
......
};这个函数定义在文件art/runtime/gc/heap.h中。
Heap类的成员函数AllocatorMayHaveConcurrentGC的判断逻辑与上面分析的成员函数AllocatorHasAllocationStack是一样的,这就意味着目前提供的Compacting GC都是非Concurrent的。不过以后是会提供具有Concurrent功能的Compacting GC的,称为Concurrent Copying GC。
以上就是Heap类的成员函数AllocObjectWithAllocator的实现,接下来我们继续分析Heap类的成员函数TryToAllocate和AllocateInternalWithGc的实现,以便可以更好地了解ART运行时分配对象的过程。这也有利用我们后面分析ART运行时的Compacting GC的执行过程。
Heap类的成员函数TryToAllocate的实现如下所示:
template <const bool kInstrumented, const bool kGrow>
inline mirror::Object* Heap::TryToAllocate(Thread* self, AllocatorType allocator_type,
size_t alloc_size, size_t* bytes_allocated,
size_t* usable_size) {
if (allocator_type != kAllocatorTypeTLAB &&
UNLIKELY(IsOutOfMemoryOnAllocation<kGrow>(allocator_type, alloc_size))) {
return nullptr;
}
mirror::Object* ret;
switch (allocator_type) {
case kAllocatorTypeBumpPointer: {
DCHECK(bump_pointer_space_ != nullptr);
alloc_size = RoundUp(alloc_size, space::BumpPointerSpace::kAlignment);
ret = bump_pointer_space_->AllocNonvirtual(alloc_size);
if (LIKELY(ret != nullptr)) {
*bytes_allocated = alloc_size;
*usable_size = alloc_size;
}
break;
}
case kAllocatorTypeRosAlloc: {
if (kInstrumented && UNLIKELY(running_on_valgrind_)) {
// If running on valgrind, we should be using the instrumented path.
ret = rosalloc_space_->Alloc(self, alloc_size, bytes_allocated, usable_size);
} else {
DCHECK(!running_on_valgrind_);
ret = rosalloc_space_->AllocNonvirtual(self, alloc_size, bytes_allocated, usable_size);
}
break;
}
case kAllocatorTypeDlMalloc: {
if (kInstrumented && UNLIKELY(running_on_valgrind_)) {
// If running on valgrind, we should be using the instrumented path.
ret = dlmalloc_space_->Alloc(self, alloc_size, bytes_allocated, usable_size);
} else {
DCHECK(!running_on_valgrind_);
ret = dlmalloc_space_->AllocNonvirtual(self, alloc_size, bytes_allocated, usable_size);
}
break;
}
case kAllocatorTypeNonMoving: {
ret = non_moving_space_->Alloc(self, alloc_size, bytes_allocated, usable_size);
break;
}
case kAllocatorTypeLOS: {
ret = large_object_space_->Alloc(self, alloc_size, bytes_allocated, usable_size);
// Note that the bump pointer spaces aren't necessarily next to
// the other continuous spaces like the non-moving alloc space or
// the zygote space.
DCHECK(ret == nullptr || large_object_space_->Contains(ret));
break;
}
case kAllocatorTypeTLAB: {
DCHECK_ALIGNED(alloc_size, space::BumpPointerSpace::kAlignment);
if (UNLIKELY(self->TlabSize() < alloc_size)) {
const size_t new_tlab_size = alloc_size + kDefaultTLABSize;
if (UNLIKELY(IsOutOfMemoryOnAllocation<kGrow>(allocator_type, new_tlab_size))) {
return nullptr;
}
// Try allocating a new thread local buffer, if the allocaiton fails the space must be
// full so return nullptr.
if (!bump_pointer_space_->AllocNewTlab(self, new_tlab_size)) {
return nullptr;
}
*bytes_allocated = new_tlab_size;
} else {
*bytes_allocated = 0;
}
// The allocation can't fail.
ret = self->AllocTlab(alloc_size);
DCHECK(ret != nullptr);
*usable_size = alloc_size;
break;
}
default: {
LOG(FATAL) << "Invalid allocator type";
ret = nullptr;
}
}
return ret;
}这个函数定义在文件art/runtime/gc/heap.h中。
Heap类的成员函数TryToAllocate的实现是很直觉的,我们可以通过图3来描述:
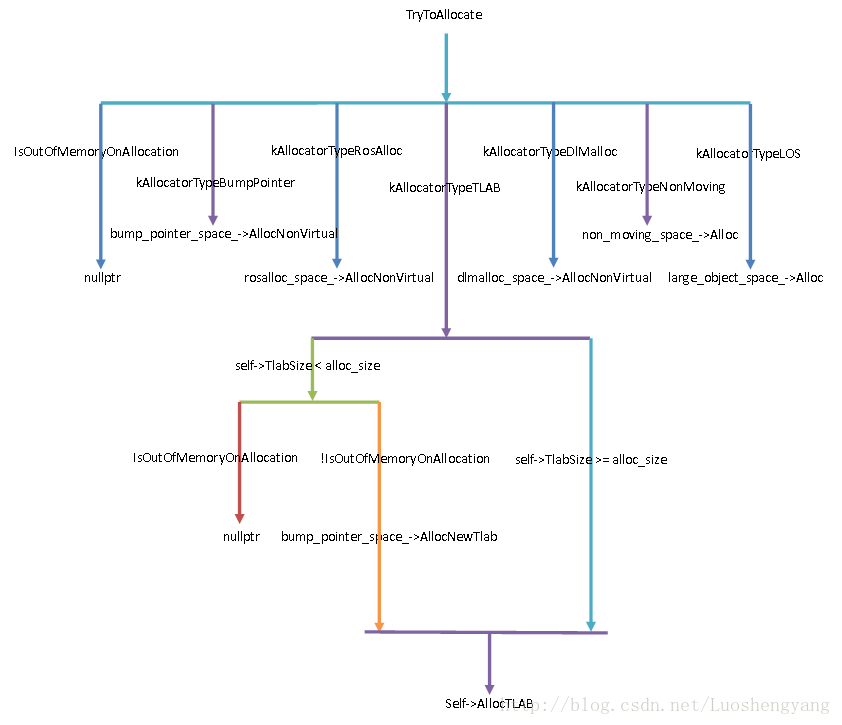
图3 TryToAllocate分配对象过程
首先,如果不是指定在当前ART运行时线程的TLAB中分配对象,并且指定分配的对象大小超出了当前堆的限制,那么就会分配失败,返回一个nullptr指针。
接下来,就根据参数allocator指定的分配器在不同的Space中分配对象:
1. 指定在Bump Pointer Space中分配对象,就调用Heap类的成员变量bump_pointer_space_指向的一个BumpPointerSpace对象的成员函数AllocNonvirtual分配指定大小的内存。
2. 指定在Ros Alloc Space中分配对象,就调用Heap类的成员变量rosalloc_space_指向的一个RosAllocSpace对象的成员函数Alloc者AllocNonvirtual分配指定大小的内存。当模板参数kInstrumented的值等于true,并且Heap类的成员变量running_on_valgrind_的值等于true时,就调用RosAllocSpace类的成员函数Alloc进行分配。否则的话,就调用RosAllocSpace类的成员函数AllocNonvirtual进行分配。从Heap类的成员变量running_on_valgrind_的命令就可以很容易推断出,调用RosAllocSpace类的成员函数Alloc分配的内存具有非法内存访问检查功能,在前面ART运行时为新创建对象分配内存的过程分析一篇文章中,我们有提到这种内存分配方式。
3. 指定在Dl Malloc Space中分配对象,就调用Heap类的成员变量dlmalloc_space_指向的一个DlMallocSpace对象的成员函数Alloc者AllocNonvirtual分配指定大小的内存。这一点与在Ros Alloc Space中分配对象的逻辑是完全一致的,除了一个是在Dl Malloc Space中分配内存, 另一个是在Ros Alloc Space中分配对象之外。
4. 指定在Non Moving Space中分配对象,就调用Heap类的成员变量non_moving_space_指向的一个RosAllocSpace对象或者DlMallocSpace对象的成员函数Alloc分配指定大小的内存。从前面ART运行时Compacting GC堆创建过程分析一文可以知道,Heap类的成员变量non_moving_space_指向的可能是一个Ros Alloc Space,也有可能是一个Dl Malloc Space。
5. 指定在Large Object Space中分配对象,就调用Heap类的成员变量large_object_space_指向的一个FreeListSpace对象或者LargeObjectMapSpace对象的成员函数Alloc分配指定大小的内存。FreeListSpace和LargeObjectMapSpace类是用来描述ART运行时的Large Object Space的,它们的实现方式在前面ART运行时Java堆创建过程分析一文中有介绍。
6. 指定在当前ART运行时线程的TLAB中分配对象。这种情况下首先判断当前ART运行时线程的TLAB剩余大小是否能够满足分配请求的内存大小。如果不能满足,并且没有超出当前堆的限制,那么就会首先Heap类的成员变量bump_pointer_space_指向的一个BumpPointerSpace对象的成员函数AllocNewTlab重新分配一块可以满足当前请求的TLAB,然后再调用参数self描述的一个Thread对象的成员函数AllocTlab在当前ART运行时线程的TLAB中分配对象。另一方面,如果当前ART运行时线程的TLAB剩余大小不能够满足分配请求的内存大小,而且请求分配的内存大小又超出了当前堆的限制,那么当前分配请求就失败了,于是就返回一个nullptr。最后,如果当前ART运行时线程的TLAB剩余大小能够满足分配请求的内存大小,那么就直接调用参数self描述的一个Thread对象的成员函数AllocTlab在当前ART运行时线程的TLAB中分配对象。
对于在Dl Malloc Space和Large Object Space分配对象的过程,我们在前面ART运行时为新创建对象分配内存的过程分析一篇文章中已经分析过了,因此接下来我们就主要分析在当前ART运行时线程的TLAB、Bump Pointer Space和Ros Alloc Space中分配对象的过程,以便后面我们可以更好理解Compacting GC的执行过程。
我们首先看在当前ART运行时线程的TLAB分配对象的过程。这里又为两个子过程。
第一个子过程是调用BumpPointerSpace类的成员函数AllocNewTlab为当前ART运行时线程分配一块TLAB,它的实现如下所示:
bool BumpPointerSpace::AllocNewTlab(Thread* self, size_t bytes) {
MutexLock mu(Thread::Current(), block_lock_);
RevokeThreadLocalBuffersLocked(self);
byte* start = AllocBlock(bytes);
if (start == nullptr) {
return false;
}
self->SetTlab(start, start + bytes);
return true;
}这个函数定义在文件art/runtime/gc/space/bump_pointer_space.cc中。
BumpPointerSpace类的成员函数AllocNewTlab首先是调用成员函数RevokeThreadLocalBuffersLocked撤销当前ART运行时线程的TLAB,因为之前可能给它分配过TLAB,接着再调用成员函数AllocBlock在Bump Pointer Space中分配一块由参数bytes指定的内存块,并且调用Thread类的成员函数SetTlab将该内存块设置为当前ART运行时线程新的TLAB。接下来我们就继续分析上述三个函数的实现。
BumpPointerSpace类的成员函数RevokeThreadLocalBuffersLocked的实现如下所示:
void BumpPointerSpace::RevokeThreadLocalBuffersLocked(Thread* thread) {
objects_allocated_.FetchAndAddSequentiallyConsistent(thread->GetThreadLocalObjectsAllocated());
bytes_allocated_.FetchAndAddSequentiallyConsistent(thread->GetThreadLocalBytesAllocated());
thread->SetTlab(nullptr, nullptr);
}这个函数定义在文件art/runtime/gc/space/bump_pointer_space.cc中。
由于ART运行时线程的TLAB只是记录了它指向的内存块的起始地址和结束地址,而实际的内存块是位于Bump Pointer Space中的,因此这里就是简单地将在当前ART运行时线程TLAB分配过的对象和内存数据汇总到Bump Pointer Space中去即可,这包括在当前ART运行时线程TLAB分配过的对象数和内存字数。最后调用Thread类的成员函数SetTlab将当前ART运行时线程的TLAB清空,就可以完成撤销工作了。
BumpPointerSpace类的成员函数AllocBlock的实现如下所示:
byte* BumpPointerSpace::AllocBlock(size_t bytes) {
bytes = RoundUp(bytes, kAlignment);
if (!num_blocks_) {
UpdateMainBlock();
}
byte* storage = reinterpret_cast<byte*>(
AllocNonvirtualWithoutAccounting(bytes + sizeof(BlockHeader)));
if (LIKELY(storage != nullptr)) {
BlockHeader* header = reinterpret_cast<BlockHeader*>(storage);
header->size_ = bytes; // Write out the block header.
storage += sizeof(BlockHeader);
++num_blocks_;
}
return storage;
}这个函数定义在文件art/runtime/gc/space/bump_pointer_space.cc中。
Bump Pointer Space支持按块和按对象分配内存的方式。其中,按块分配的内存主要就是用来作ART运行时线程的TLAB的。分配出来的内存块有一个额外的BlockHeader,它主要是用来记录块的大小。
BumpPointerSpace类的成员变量num_blocks_记录了Bump Pointer Space已经分配了多少块内存作为当前ART运行时线程的TLAB。当它的值等于0的时候,就意味着还没有分配过内存块作为ART运行时线程的TLAB。这时候首先是调用BumpPointerSpace类的成员函数UpdateMainBlock记录一下当前已经分配的对象占用的内存大小。实际上就是将最开始那块以对角为单位分配的内存作为Bump Pointer Space的Main Block。这是一个特殊的Block,因为它没有通过额外的BlockHeader来描述。
BumpPointerSpace类的成员函数UpdateMainBlock的实现如下所示:
void BumpPointerSpace::UpdateMainBlock() {
DCHECK_EQ(num_blocks_, 0U);
main_block_size_ = Size();
}这个函数定义在文件art/runtime/gc/space/bump_pointer_space.cc中。
从这里我们就可以看到,BumpPointerSpace类的成员函数UpdateMainBlock主要是将Main Block的大小记录在成员变量main_block_size_中。注意,BumpPointerSpace类的成员函数Size是从父类ContinuousSpace继承下来的,它的职责就是返回当前已经分配出去的内存总数。
回到前面BumpPointerSpace类的成员函数AllocBlock中,接下来就会调用成员函数AllocNonvirtualWithoutAccounting执行分配内存块的操作,它的实现如下所示:
inline mirror::Object* BumpPointerSpace::AllocNonvirtualWithoutAccounting(size_t num_bytes) {
DCHECK(IsAligned<kAlignment>(num_bytes));
byte* old_end;
byte* new_end;
do {
old_end = end_.LoadRelaxed();
new_end = old_end + num_bytes;
// If there is no more room in the region, we are out of memory.
if (UNLIKELY(new_end > growth_end_)) {
return nullptr;
}
} while (!end_.CompareExchangeWeakSequentiallyConsistent(old_end, new_end));
return reinterpret_cast<mirror::Object*>(old_end);
}这个函数定义在文件art/runtime/gc/space/bump_pointer_space-inl.h中。
Bump Pointer Space当前已经分配出去的内存记录在BumpPointerSpace类的成员变量end_中。只要分配大小为num_bytes的内存块之后,不会超过当前Bump Pointer Space的限制,那么将BumpPointerSpace类的成员变量end移动到分配的块内存的末尾即可。这里通过一个while循环来修改BumpPointerSpace类的成员变量end,是因为这里采用了一个非加锁模式的多线程并发访问资源方案。
回到BumpPointerSpace类的成员函数AllocNewTlab中,当成功分配到新的内存块之后,接下来就可以调用Thread类的成员函数SetTlab为当前ART运行时线程设置新的TLAB了,它的实现如下所示:
void Thread::SetTlab(byte* start, byte* end) {
DCHECK_LE(start, end);
tlsPtr_.thread_local_start = start;
tlsPtr_.thread_local_pos = tlsPtr_.thread_local_start;
tlsPtr_.thread_local_end = end;
tlsPtr_.thread_local_objects = 0;
}这个函数定义在文件/art/runtime/thread.cc中。
Thread类的成员成变量tlsPtr_指向的是一个线程局部储存。这个线程局总储存通过一个tls_ptr_sized_values结构体来描述。在这个tls_ptr_sized_values结构体中,成员变量thread_local_start和thread_local_end记录了TLAB的起始地址和结束地址,另外两个成员变量thread_local_pos和thread_local_objects分别用来记录在当前ART运行时线程的TLAB中下一个要分配的对象的起始地址和已经在ART运行时线程的TLAB中分配出去的对象的个数。
至此,我们就分析完成了BumpPointerSpace类的成员函数AllocNewTlab为当前ART运行时线程分配一块TLAB的子过程,接下来再看第二个子过程,即Thread类的成员函数AllocTlab的实现,如下所示:
inline mirror::Object* Thread::AllocTlab(size_t bytes) {
DCHECK_GE(TlabSize(), bytes);
++tlsPtr_.thread_local_objects;
mirror::Object* ret = reinterpret_cast<mirror::Object*>(tlsPtr_.thread_local_pos);
tlsPtr_.thread_local_pos += bytes;
return ret;
}这个函数定义在文件/art/runtime/thread-inl.h中。
在当前ART运行时线程的TLAB中分配对象的过程很简单,主要将用来当前ART运行时线程的线程局部储存的一个tls_ptr_sized_values结构体的成员变量thread_local_pos向前移动参数bytes指定的大小,并且将成员变量thread_local_objects增加1即可,同时将原来成员变量thread_local_pos描述的地址值返回给调用者,作为新分配对象的起始地址。
这样我们就分析完成了在ART运行时线程的TLAB分配对象的过程,接下来我们继续分析BumpPointerSpace类的成员函数AllocNonvirtual的实现,以便可以了解在Bump Pointer Space分配一个普通对象的过程,它的实现如下所示:
inline mirror::Object* BumpPointerSpace::AllocNonvirtual(size_t num_bytes) {
mirror::Object* ret = AllocNonvirtualWithoutAccounting(num_bytes);
if (ret != nullptr) {
objects_allocated_.FetchAndAddSequentiallyConsistent(1);
bytes_allocated_.FetchAndAddSequentiallyConsistent(num_bytes);
}
return ret;
}这个函数定义在文件art/runtime/gc/space/bump_pointer_space-inl.h中。
BumpPointerSpace类的成员函数AllocNonvirtual通过调用我们前面已经分析过的成员函数AllocNonvirtualWithoutAccounting来在Bump Pointer Space中分配一块指定大小的内存,然后再增加Bump Pointer Space已经分配对象数和内存字节数即可。
从上面的分析过程就可以清楚地看到在Bump Pointer Space中分配对象的过程是非常简单的,它只需要将下一个要分配的内存块的地址不断地向前推进即可。
接下来我们再看在Ros Alloc Space中分配对象的过程,即RosAllocSpace类的成员函数AllocNonvirtual的实现,如下所示:
class RosAllocSpace : public MallocSpace {
public:
......
mirror::Object* AllocNonvirtual(Thread* self, size_t num_bytes, size_t* bytes_allocated,
size_t* usable_size) {
// RosAlloc zeroes memory internally.
return AllocCommon(self, num_bytes, bytes_allocated, usable_size);
}
......
};这个函数定义在文件art/runtime/gc/space/bump_pointer_space.h中。
RosAllocSpace类的成员函数AllocNonvirtual通过调用另外一个成员函数AllocCommon来分配指定大小的内存,后者的实现如下所示:
template<bool kThreadSafe>
inline mirror::Object* RosAllocSpace::AllocCommon(Thread* self, size_t num_bytes,
size_t* bytes_allocated, size_t* usable_size) {
size_t rosalloc_size = 0;
if (!kThreadSafe) {
Locks::mutator_lock_->AssertExclusiveHeld(self);
}
mirror::Object* result = reinterpret_cast<mirror::Object*>(
rosalloc_->Alloc<kThreadSafe>(self, num_bytes, &rosalloc_size));
if (LIKELY(result != NULL)) {
......
*bytes_allocated = rosalloc_size;
......
if (usable_size != nullptr) {
*usable_size = rosalloc_size;
}
}
return result;
}这个函数定义在文件art/runtime/gc/space/bump_pointer_space-inl.h中。
RosAllocSpace类的成员变量rosalloc_指向的是一个RosAlloc对象。这个RosAlloc对象负责了Ros Alloc Space底层的内存管理。因此,这里就调用了RosAlloc类的成员函数Alloc来执行具体的内存分配工作。
RosAlloc类的成员函数Alloc的实现如下所示:
template<bool kThreadSafe>
inline ALWAYS_INLINE void* RosAlloc::Alloc(Thread* self, size_t size, size_t* bytes_allocated) {
if (UNLIKELY(size > kLargeSizeThreshold)) {
return AllocLargeObject(self, size, bytes_allocated);
}
void* m;
if (kThreadSafe) {
m = AllocFromRun(self, size, bytes_allocated);
} else {
m = AllocFromRunThreadUnsafe(self, size, bytes_allocated);
}
// Check if the returned memory is really all zero.
if (kCheckZeroMemory && m != nullptr) {
byte* bytes = reinterpret_cast<byte*>(m);
for (size_t i = 0; i < size; ++i) {
DCHECK_EQ(bytes[i], 0);
}
}
return m;
}这个函数定义在文件art/runtime/gc/allocator/rosalloc-inl.h中。
如果指定分配的大小size大于常量kLargeSizeThreshold的值,那么就会调用成员函数AllocLargeObject按页进行分配。否则的话,取决于模板参数kThreadSafe的值,也就是当前执行路径是否是线程安全的。如果是线程安全的,就调用成员函数AllocFromRun进行分配。否则的话,就调用成员函数AllocFromRunThreadUnsafe进行分配。两者的逻辑是基本相同的,区别就在于后者要求在获取堆锁的前提下进行。
常量kLargeSizeThreshold的值定义为2048,这意味着大于2KB的内存分配请求都是按页进行分配的。接下来,我们首先分析RosAlloc类的成员函数AllocLargeObject的实现,然后再分析RosAlloc类的成员函数AllocFromRun的实现,以便可以了解RosAlloc是如何管理内存的。
RosAlloc类的成员函数AllocLargeObject的实现如下所示:
void* RosAlloc::AllocLargeObject(Thread* self, size_t size, size_t* bytes_allocated) {
......
size_t num_pages = RoundUp(size, kPageSize) / kPageSize;
void* r;
{
MutexLock mu(self, lock_);
r = AllocPages(self, num_pages, kPageMapLargeObject);
}
......
const size_t total_bytes = num_pages * kPageSize;
*bytes_allocated = total_bytes;
......
return r;
}这个函数定义在文件art/runtime/gc/allocator/rosalloc.cc中。
RosAlloc类的成员函数AllocLargeObject首先是将请求分配的内存字节数对齐到页大小,然后再计算得到要分配的页数num_pages,最后调用另外一个成员函数AllocPages进行分配。
RosAlloc类的成员函数AllocPages的定义比较长,我们分段来阅读。
第一段代码是在一个Free Page Run列表中检查是否有合适的FreePageRun用来分配,如下所示:
void* RosAlloc::AllocPages(Thread* self, size_t num_pages, byte page_map_type) {
lock_.AssertHeld(self);
......
FreePageRun* res = NULL;
const size_t req_byte_size = num_pages * kPageSize;
// Find the lowest address free page run that's large enough.
for (auto it = free_page_runs_.begin(); it != free_page_runs_.end(); ) {
FreePageRun* fpr = *it;
......
size_t fpr_byte_size = fpr->ByteSize(this);
......
if (req_byte_size <= fpr_byte_size) {
// Found one.
free_page_runs_.erase(it++);
......
if (req_byte_size < fpr_byte_size) {
// Split.
FreePageRun* remainder = reinterpret_cast<FreePageRun*>(reinterpret_cast<byte*>(fpr) + req_byte_size);
......
remainder->SetByteSize(this, fpr_byte_size - req_byte_size);
......
// Don't need to call madvise on remainder here.
free_page_runs_.insert(remainder);
......
fpr->SetByteSize(this, req_byte_size);
......
}
res = fpr;
break;
} else {
++it;
}
}这个代码片断定义在art/runtime/gc/allocator/rosalloc.cc中。
RosAlloc类每次释放按页分配的内存时,都是将它们放入到成员变量free_page_runs_描述的一个空闲页列表中,以便以后可以复用。
这段代码的逻辑很简单,它就是从头开始遍历成员变量free_page_runs_描述的空闲页列表。如果中间找到一个Free Page Run,它的大小fpr_byte_size大于等于请求分配的大小req_byte_size,就停止遍历。在大于的情况下,还需要将该Free Page Run的剩余大小封装成另外一个Free Page Run,并且添加到成员变量free_page_runs_描述的空闲页列表中去。
第二段代码是解决第一段代码没有在Free Page Run列表中找到合适的Free Page Run的情况,如下所示:
// Failed to allocate pages. Grow the footprint, if possible.
if (UNLIKELY(res == NULL && capacity_ > footprint_)) {
FreePageRun* last_free_page_run = NULL;
size_t last_free_page_run_size;
auto it = free_page_runs_.rbegin();
if (it != free_page_runs_.rend() && (last_free_page_run = *it)->End(this) == base_ + footprint_) {
// There is a free page run at the end.
......
last_free_page_run_size = last_free_page_run->ByteSize(this);
} else {
// There is no free page run at the end.
last_free_page_run_size = 0;
}
......
if (capacity_ - footprint_ + last_free_page_run_size >= req_byte_size) {
// If we grow the heap, we can allocate it.
size_t increment = std::min(std::max(2 * MB, req_byte_size - last_free_page_run_size),
capacity_ - footprint_);
......
size_t new_footprint = footprint_ + increment;
size_t new_num_of_pages = new_footprint / kPageSize;
......
page_map_size_ = new_num_of_pages;
......
free_page_run_size_map_.resize(new_num_of_pages);
art_heap_rosalloc_morecore(this, increment);
if (last_free_page_run_size > 0) {
// There was a free page run at the end. Expand its size.
......
last_free_page_run->SetByteSize(this, last_free_page_run_size + increment);
......
} else {
// Otherwise, insert a new free page run at the end.
FreePageRun* new_free_page_run = reinterpret_cast<FreePageRun*>(base_ + footprint_);
......
new_free_page_run->SetByteSize(this, increment);
......
free_page_runs_.insert(new_free_page_run);
......
}
......
footprint_ = new_footprint;
// And retry the last free page run.
it = free_page_runs_.rbegin();
......
FreePageRun* fpr = *it;
......
size_t fpr_byte_size = fpr->ByteSize(this);
......
free_page_runs_.erase(fpr);
......
if (req_byte_size < fpr_byte_size) {
// Split if there's a remainder.
FreePageRun* remainder = reinterpret_cast<FreePageRun*>(reinterpret_cast<byte*>(fpr) + req_byte_size);
......
remainder->SetByteSize(this, fpr_byte_size - req_byte_size);
......
free_page_runs_.insert(remainder);
......
fpr->SetByteSize(this, req_byte_size);
......
}
res = fpr;
}
}
这个代码片断定义在art/runtime/gc/allocator/rosalloc.cc中。
如果本地变量res的值等于NULL,就表明前面没有在Free Page Run列表中找到合适的Free Page Run。在这种情况下,如果当前Ros Alloc Space底层封装的内存块的使用大小(由成员变量footprint_描述)还没有达到最大值(由成员变量capacity_描述),就尝试增长内存块的大小,以便可以满足分配请求。
由于Ros Alloc Space底层封装的内存块有可能是按页进行分配的,也有可能是按对象大小进行分配的,因此内存块的最后一个分配单位有可能是若干个页,也可能是一个对象。在前一种情况下,如果这若干个页恰好就是Free Page Run列表中的最后一个Free Page Run,那么就选择增加该Free Page Run的大小。否则的话,就选择创建另外一个新的Free Page Run,并且添加到Free Page Run列表中去。
完成上面的操作之后,我们就可以保证Free Page Run列表的最后一个Free Page Run是一定能够满足分配请求的。这时候就对它执行第一段代码类似的逻辑,即在最后一个Free Page Run的大小大于请求分配大小的情况下,对其进行分割,并且将分割出来的剩余大小封装成另外一个Free Page Run添加Free Page Run列表中去。
第三段代码执行收尾操作,如下所示:
if (LIKELY(res != NULL)) {
// Update the page map.
size_t page_map_idx = ToPageMapIndex(res);
......
switch (page_map_type) {
case kPageMapRun:
page_map_[page_map_idx] = kPageMapRun;
for (size_t i = 1; i < num_pages; i++) {
page_map_[page_map_idx + i] = kPageMapRunPart;
}
break;
case kPageMapLargeObject:
page_map_[page_map_idx] = kPageMapLargeObject;
for (size_t i = 1; i < num_pages; i++) {
page_map_[page_map_idx + i] = kPageMapLargeObjectPart;
}
break;
default:
LOG(FATAL) << "Unreachable - page map type: " << page_map_type;
break;
}
......
return res;
}
......
return nullptr;
}这个代码片断定义在art/runtime/gc/allocator/rosalloc.cc中。
RosAlloc类有一个page_map_数组,用来记录已经使用的每一个页的类型,就是记录它们是按页分配使用的,还是按对象分配使用的,这是由参数page_map_type决定的。对于按页使用分配出去的页块,第一个页的类型记录为kPageMapLargeObject,其余页记录为kPageMapLargeObjectPart。对于按对象使用分配出去的页块,第一个页的类型记录为kPageMapRun,其余页记录为kPageMapRunPart。
当然,设置page_map_数组是在能成功找到一个合适的Free Page Run的情况下进行的。如果没有找到合适的Free Page Run,就直接返回一个nullptr给调用者,表示分配失败了。
以上就是RosAlloc类按页分配内存的过程,接下来我们继续看按对象分配内存的过程,即RosAlloc类的成员函数AllocFromRun的实现,如下所示:
void* RosAlloc::AllocFromRun(Thread* self, size_t size, size_t* bytes_allocated) {
......
size_t bracket_size;
size_t idx = SizeToIndexAndBracketSize(size, &bracket_size);
......
void* slot_addr;
if (LIKELY(idx < kNumThreadLocalSizeBrackets)) {
// Use a thread-local run.
Run* thread_local_run = reinterpret_cast<Run*>(self->GetRosAllocRun(idx));
......
slot_addr = thread_local_run->AllocSlot();
......
if (UNLIKELY(slot_addr == nullptr)) {
// The run got full. Try to free slots.
......
MutexLock mu(self, *size_bracket_locks_[idx]);
bool is_all_free_after_merge;
// This is safe to do for the dedicated_full_run_ since the bitmaps are empty.
if (thread_local_run->MergeThreadLocalFreeBitMapToAllocBitMap(&is_all_free_after_merge)) {
......
} else {
// No slots got freed. Try to refill the thread-local run.
......
if (thread_local_run != dedicated_full_run_) {
thread_local_run->SetIsThreadLocal(false);
......
}
thread_local_run = RefillRun(self, idx);
if (UNLIKELY(thread_local_run == nullptr)) {
self->SetRosAllocRun(idx, dedicated_full_run_);
return nullptr;
}
......
thread_local_run->SetIsThreadLocal(true);
self->SetRosAllocRun(idx, thread_local_run);
......
}
......
slot_addr = thread_local_run->AllocSlot();
......
}
......
} else {
// Use the (shared) current run.
MutexLock mu(self, *size_bracket_locks_[idx]);
slot_addr = AllocFromCurrentRunUnlocked(self, idx);
......
}
......
*bytes_allocated = bracket_size;
// Caller verifies that it is all 0.
return slot_addr;
}这个函数定义在文件art/runtime/gc/allocator/rosalloc.cc中。
RosAllocSpace对内存的管理与BumpPointerSpace对内存的管理有点类似,它们都是会将自己的一部分内存当作ART运行时线程的TLAB使用。因此,RosAlloc类的成员函数AllocFromRun就会先考虑是否要在当前ART运行时线程的局部Run进行分配。当请求分配的内存小于常量kNumThreadLocalSizeBrackets描述的值的时候,RosAlloc类的成员函数AllocFromRun就会在当前ART运行时线程的局部Run进行分配。否则的话,再在所有ART运行时线程共享的Run进行分配。
常量kNumThreadLocalSizeBrackets的值定义在11,根据我们在前面ART运行时Compacting GC简要介绍和学习计划一文对Runs-of-slots算法的描述,这个值对应的内存大小即为176。这就意味着小于176字节的分配请求都在当前ART运行时线程的局部Run进行分配。注意,请求分配的大小已经转换为Run Index,即变量idx的值,因此,这里比较的是Run Index的大小,而不是直接的内存大小,不过效果是一样的。
当决定在当前ART运行时线程的局部Run进行分配的情况下,首先要做的就是获得当前ART运行时线程的Index值等于idx的局部Run,这可以通过参数self指向的一个Thread对象的成员函数GetRosAllocRun来获得。
获得了当前ART运行时线程的Index值等于idx的局部Run之后,就可以调用它的成员函数AllocSlot进行分配了。如果分配失败,也就是该Run已经没有空闲的Slot可用,就需要进一步处理。在前面ART运行时Compacting GC简要介绍和学习计划一文中,我们提到,每一个Run都有一个thread local bit map,它的作用是在释放对象时,对应的Slot不会马上就释放,而是先Hold住,但是会在thread local bit map记录它是以后需要释放掉的。这样当一个Run无法成功分配到Slot时,才会对那些需要释放但是又还没有释放的Slot进行处理,实际上就是合并thread local bit map的信息到alloc bit map中去,这是通过调用Run类的成员函数MergeThreadLocalFreeBitMapToAllocBitMap来完成的。通过这种方式,就可以达到批量方式释放空闲Slot的目的。
但是也有可能出现这样的一种情况,一个Run既没有空闲的Slot可用,而且也没有该释放又还没有释放的Slot。在这种情况下,调用Run类的成员函数MergeThreadLocalFreeBitMapToAllocBitMap就会返回false。这时候就需要给当前ART运行时线程增加一个Index值等于idx的局部Run。这个Run可以通过调用RosAlloc类的成员函数RefillRun来进行分配。
如果调用RosAlloc类的成员函数RefillRun成功分配到一个Run,那么就将该Run设置为当前ART运行时线程的局部Run,这是通过调用参数self指向的一个Thread对象的成员函数SetRosAllocRun来进行的。同时也会调用该Run的成员函数AllocSlot分配一个Slot,这时候就能够保证是成功分配到的。
另一个方面,如果调用RosAlloc类的成员函数RefillRun不能成功分配到一个Run,这时候请求分配的内存就失败了。在返回一个nullptr给调用者之前,RosAlloc类的成员函数AllocFromRun会做一个代码优化,那就是将一个永远是full状态的并且是在所有ART运行时线程之间共享的Run设置为当前ART运行时线程的Index值为idx的局部Run。
这个永远是full状态的并且是在所有ART运行时线程之间共享的Run保存在RosAlloc类的成员变量dedicated_full_run_中。由于它的状态永远为full,因而就不能从中分配到Slot,它起到的作用就是使得我们总是可以从当前的ART运行时线程中获得一个不为nullptr值的局部Run,这样就可以在代码里面省去一些空指针判断逻辑。
以上就是在当前ART运行时线程局部Run中分配内存的过程,接下来我们继续分析在所有ART运行时线程共享的Run中分配内存的过程,即RosAlloc类的成员函数AllocFromCurrentRunUnlocked的实现,如下所示:
inline void* RosAlloc::AllocFromCurrentRunUnlocked(Thread* self, size_t idx) {
Run* current_run = current_runs_[idx];
......
void* slot_addr = current_run->AllocSlot();
if (UNLIKELY(slot_addr == nullptr)) {
// The current run got full. Try to refill it.
......
current_run = RefillRun(self, idx);
if (UNLIKELY(current_run == nullptr)) {
// Failed to allocate a new run, make sure that it is the dedicated full run.
current_runs_[idx] = dedicated_full_run_;
return nullptr;
}
......
current_run->SetIsThreadLocal(false);
current_runs_[idx] = current_run;
......
slot_addr = current_run->AllocSlot();
......
}
return slot_addr;
}这个函数定义在文件art/runtime/gc/allocator/rosalloc.cc中。
RosAlloc类的成员变量currents_runs_描述的就是所有的ART运行时线程都共享的Run,通过参数idx就可以获得要在其中分配Slot的Run。获得了这个Run之后,就可以调用它的成员函数AllocSlot进行内存分配。
在分配失败的情况下,处理方式与前面在当前的ART运行时线程的局部Run中分配失败Slot的逻辑类似,都是会尝试调用RosAlloc类的成员函数RefillRun重新分配另外一个Index值为idx的Run,然后再从该Run分配Slot。如果不能重新分配到一个Index值为idx的Run,那么就会将currents_runs_数组中索引值等于idx的Run设置为dedicated_fullrun,也是为了减少代码里的空指针判断逻辑。
至此,在Ros Alloc Space中分配对象的过程就分要完成了,Heap类的成员函数TryToAllocate的实现也分析完成了,回到Heap类的成员函数AllocObjectWithAllocator中,我们最后需要分析的一个函数是Heap类的成员函数AllocateInternalWithGc,也就是带GC的对象分配过程,如图4所示:
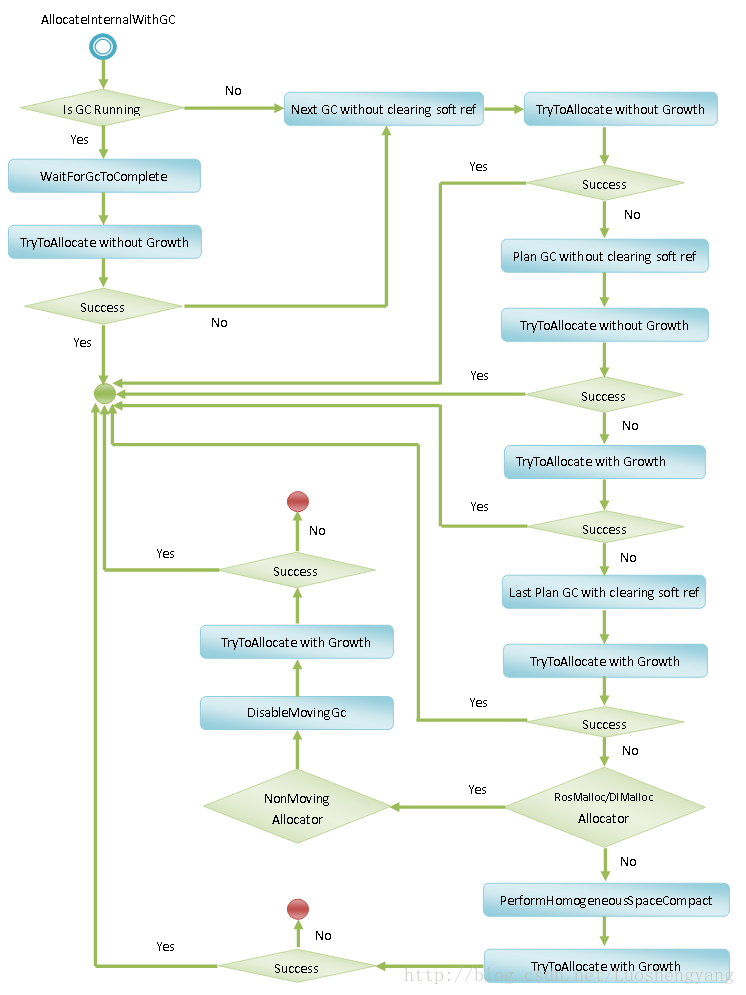
图4 AllocateInternalWithGc分配对象过程
接下来我们就结合Heap类的成员函数AllocateInternalWithGc的源码来分析图4涉及到逻辑。由于Heap类的成员函数AllocateInternalWithGc的实现也是比较长,我们分段来阅读。
第一段代码是检查ART运行时当前是否正在执行GC。如果是的话,就等待当前GC完成之后,再尝试进行对象分配,如下所示:
mirror::Object* Heap::AllocateInternalWithGc(Thread* self, AllocatorType allocator,
size_t alloc_size, size_t* bytes_allocated,
size_t* usable_size,
mirror::Class** klass) {
bool was_default_allocator = allocator == GetCurrentAllocator();
......
collector::GcType last_gc = WaitForGcToComplete(kGcCauseForAlloc, self);
if (last_gc != collector::kGcTypeNone) {
// If we were the default allocator but the allocator changed while we were suspended,
// abort the allocation.
if (was_default_allocator && allocator != GetCurrentAllocator()) {
return nullptr;
}
// A GC was in progress and we blocked, retry allocation now that memory has been freed.
mirror::Object* ptr = TryToAllocate<true, false>(self, allocator, alloc_size, bytes_allocated,
usable_size);
if (ptr != nullptr) {
return ptr;
}
}这个代码片段定义在文件art/runtime/gc/heap.cc中。
首先是调用Heap类的成员函数WaitForGcToComplete检查当前是否有GC正在执行。如果有的话,就等待它执行完成。Heap类的成员函数WaitForGcToComplete的返回值last_gc不等于collector::kGcTypeNone时,就表明刚才有GC正在执行。在这种情况下,就可以调用我们前面分析过的Heap类的成员函数TryToAllocate尝试进行一次内存分配操作了。如果分配成功,就不用再往前执行。不过如果刚才的GC执行完成之后,ART运行时当前使用的分配器发生了变化,那么就不能再继续执行内存分配的操作了。这是由于ART运行时当前使用的分配器发生了变化,意味着参数allocator指定的分配器就不再合适使用。这种情况是有可能的,例如刚才的GC是由GC切换而发生的,这时候就会导致ART运行时当前使用的分配器发生变化。
第二段代码尝试执行一次GC后,再调用Heap类的成员函数TryToAllocate执行一次内存分配操作,如下所示:
collector::GcType tried_type = next_gc_type_;
const bool gc_ran =
CollectGarbageInternal(tried_type, kGcCauseForAlloc, false) != collector::kGcTypeNone;
if (was_default_allocator && allocator != GetCurrentAllocator()) {
return nullptr;
}
if (gc_ran) {
mirror::Object* ptr = TryToAllocate<true, false>(self, allocator, alloc_size, bytes_allocated,
usable_size);
if (ptr != nullptr) {
return ptr;
}
}这个代码片段定义在文件art/runtime/gc/heap.cc中。
这次执行的GC类型由Heap类的成员变量next_gc_type_决定。Heap类的成员变量next_gc_type_的值初始化为collector::kGcTypePartial,取值范围为collector::kGcTypeSticky、collector::kGcTypePartial或者collector::kGcTypeFull。
如果上一次执行的GC类型不是collector::kGcTypeSticky,那么下一次执行的GC类型就为collector::kGcTypePartial或者collector::kGcTypeFull,取决于Zygote Space是否已经创建。如果已经创建,那么下一次执行的GC类型就为collector::kGcTypePartial;否则的话,就为collector::kGcTypeFull。
如果上一次执行的GC类型为collector::kGcTypeSticky,那么就取决于上一次执行的collector::kGcTypeSticky GC的垃圾回收速度,决定下一次执行的GC类型。如果上一次执行的collector::kGcTypeSticky GC的垃圾回收速度大于之前执行过的非collector::kGcTypeSticky GC的平均垃圾回收速度,并且当前分配的内存�