树莓派 JS 库实现持续集成的“黑科技”
这个阶段在研究树莓派,主要用 Node.js 开发。开源社区有许多非常优秀的树莓派 Node.js 库,但是没有让我觉得特别好用的。因为这些库有的 API 还不错,但是性能不好,有的性能很好,但是 API 不好用。还有一些库没跟上树莓派的硬件升级,使用起来还要自己修改,作者也不处理 pull request,比较麻烦。因此我自己着手重新写一个库 rpio2。
在写库的过程中,自然要充分测试每个 API,个人比较喜欢 TDD / BDD 开发,因此一边开发功能,一边写各个 API 的单元测试。写了单元测试,自然希望在代码提交的过程中能够持续集成,最好是直接使用 travis-ci。
愿望是美好的,但是现实有点残酷。因为树莓派开发不同于其他软件开发,它涉及到硬件,虽然说单元测试可以很简单,主要是测试引脚的同步/异步输入输出和事件(中断)响应,所以开发的时候可以在树莓派环境里跑单元测试,这没有问题,但在集成的时候,我们没有办法让 travis-ci 用树莓派系统环境来跑我们的 test case 吧。这样的话,就需要我们自己实现对底层的 GPIO 的模拟。
实现对 GPIO 的模拟
听起来不错,那就开始干吧!
rpio2 库是基于 node-rpio 的,选择这个库为基础的原因是,node-rpio 又是对 bcm2835 C 语言驱动库的 Node 封装,因为 bcm2835 是用 C 写的针对 Broadcom BCM 2835 处理器(也就是树莓派现在使用的 CPU)的底层驱动,因此它可以达到非常高的性能。
使用了 bcm2835 一个额外的好处是,C 语言驱动库是模块化的函数单元,这对于测试和模拟来说是友好的,因为只需要知道对应的输入输出就可以了。而很多输入输出查规格说明书就可以了。
比如:rpio.open(pin, mode, state),当 mode 为 INPUT 的时候,如果不传 state 参数,默认的输入电阻是:当 pin <= 8 时,为 PULL_UP,当 8 < pin <= 27 时,为 PULL_DOWN。
这里面比较不好实现的一块是输入信号,因为树莓派可以让 GPIO 接输入设备,而输入设备的输入信号是实时输入的,如果在 JS 里用定时器模拟,并不能做到实时同步输入(因为 JS 是单线程非阻塞模型),所以这里需要考虑多线程,最简单的方法就是用 File API + child_process。
rpio_sim_helper.js
"use strict";
const fs = require("fs");
var pin = 0|process.argv[2];
var timers = process.argv[3].split(",").map(o => 0|o);
var fileName = "./test/gpio/gpio" + pin;
function writeAndWait(value, time){
fs.writeFileSync(fileName, new Buffer([value]));
return new Promise(function(resolve){
setTimeout(resolve, time);
});
}
var p = Promise.resolve();
for(var i = 0; i < timers.length; i += 2){
p = p.then(((i) => () => writeAndWait(timers[i], timers[i + 1]))(i));
}
p.then(function(){
var content = fs.readFileSync(fileName);
console.log(content);
}).catch(err => console.log(err));
上面实现一个简单的程序来开进程写文件,例如,要给 rpio21 引脚模拟发送一段半周期为 100 毫秒的脉冲信号,可以这么用:
node rpio_sim_helper.js 21 1,100,0,100,1,100,0,100...,1,100,0
这样,将它封装进模拟库中:
helper: function (pin, signal){
if(config.mapping === "physical"){
pin = pinMap[pin];
}
return new Promise(function(resolve, reject){
child_process.exec("node ./test/rpio_sim_helper " + pin + " " + signal,
function(err, res){
if(err) reject(err);
else resolve(res);
});
});
就可以很方便地模拟输入信号了。
对单元测试启用模拟
这很容易实现,一开始,我打算采用 proxyquire 库,这个库可以"代理"一个被测试文件里正常 require 的库,这样我只要将 rpio2 的 require('rpio') 用自己模拟库替代就行了。然而实际使用的时候发现并不行。
主要原因是,使用 proxyquire 还是会先加载 rpio 库,然后才对加载的 rpio 库进行替换,而 rpio 库里面有这样一段代码:
var gpiomap;
function setup_board()
{
var cpuinfo, boardrev, match;
cpuinfo = fs.readFileSync("/proc/cpuinfo", "ascii", function(err) {
if (err)
throw err;
});
cpuinfo.toString().split(/\n/).forEach(function (line) {
match = line.match(/^Revision.*(.{4})/);
if (match) {
boardrev = parseInt(match[1], 16);
return;
}
});
switch (boardrev) {
case 0x2:
case 0x3:
gpiomap = "v1rev1";
break;
case 0x4:
case 0x5:
case 0x6:
case 0x7:
case 0x8:
case 0x9:
case 0xd:
case 0xe:
case 0xf:
gpiomap = "v1rev2";
break;
case 0x10:
case 0x12:
case 0x13:
case 0x15:
case 0x92:
case 0x1041:
case 0x2082:
gpiomap = "v2plus";
break;
default:
throw "Unable to determine board revision";
break;
}
}
setup_board();
上面这段代码通过 /proc/cpuinfo 读取树莓派的版本信息,然而我本地 Mac 环境里并没有 /proc/cpuinfo,因此加载的时候直接报错了。而且这个文件单元测试时没必要加载,直接在测试时加载模拟库就行了。
因此,更简单的方法是测试时,将 rpio2 中的 require('rpio') 直接替换成加载 rpio_sim.js。这一步很多部署工具都可以做,比如 gulp 就是很好的选择。不过我用 babel 插件来实现代码测试覆盖度检查,所以我就直接用 babel 来做了,代码更少,也很方便:
transform_rpio_sim.js
module.exports = function(babel) {
var t = babel.types;
return {visitor: {
CallExpression: function(path){
if(path.node.callee.name === "require"){
var module = path.node.arguments[0];
if(module && module.value === "rpio"){
module.value = "../rpio_sim.js";
}
}
}
}};
};
然后我们将这些结合到一起,在 package.json 中编写测试命令:
"scripts": {
"test": "babel lib --out-dir test/lib --plugins ../test/transform_rpio_sim.js && mocha test/spec.js",
"printcov": "script/printcov.js lib/coverage.lcov lib",
"test-cov": "babel lib --out-dir test/lib --plugins ../test/transform_rpio_sim.js,transform-coverage && mocha test/spec.js --reporter=mocha-lcov-reporter > lib/coverage.lcov && npm run printcov"
},
这样就能得到单元测试结果和测试覆盖度结果:
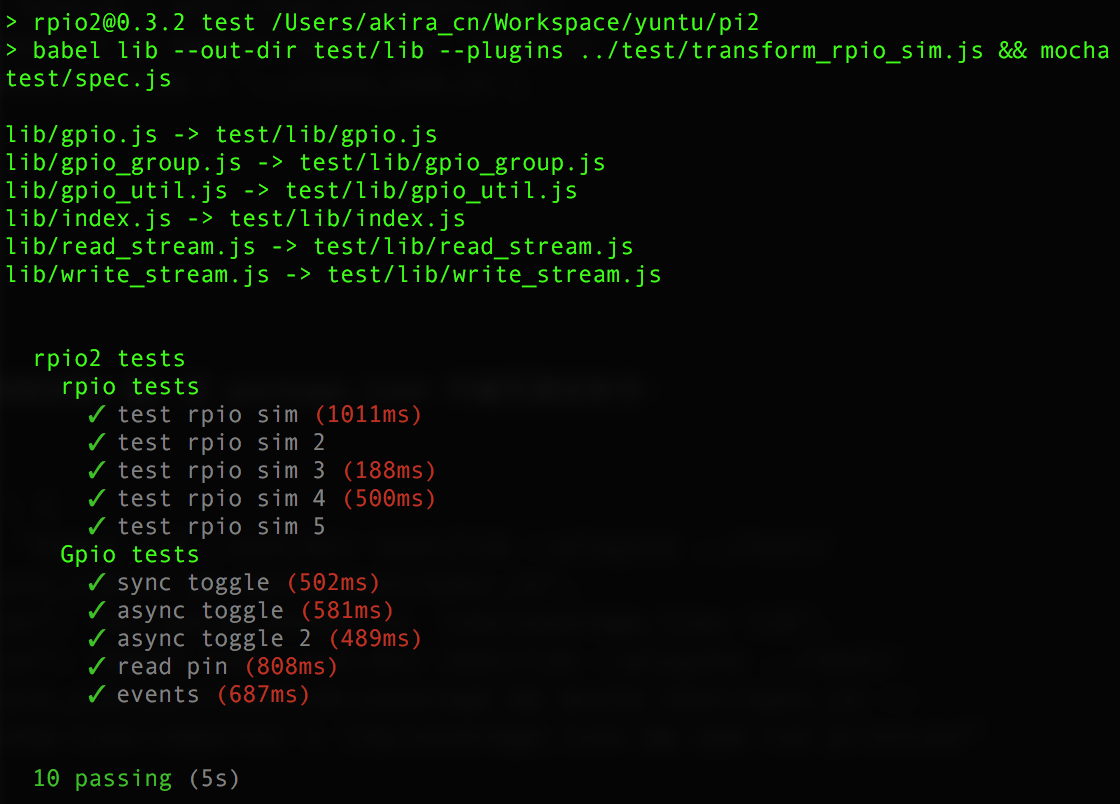
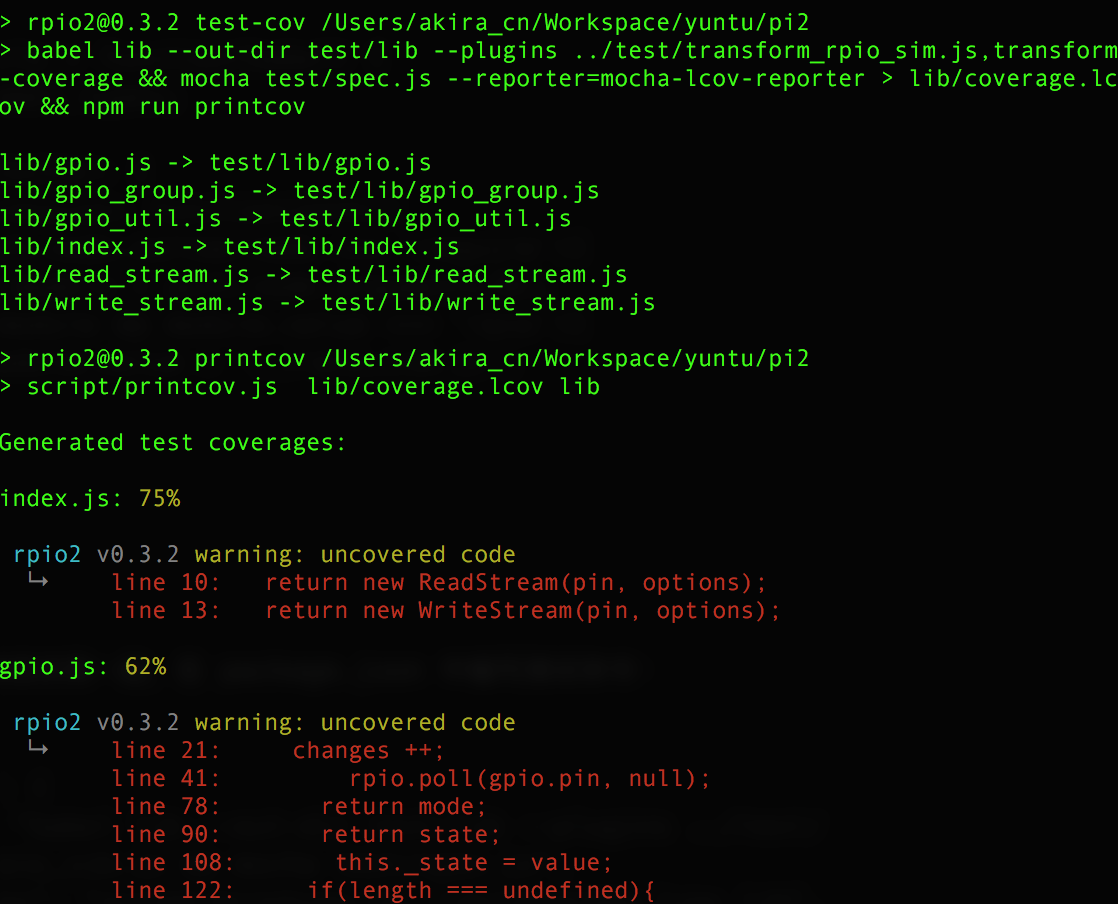
开始集成
接下来我们要在代码提交到 github 时启用 travis-ci 集成,我们和以前一样写一个 .travis.yml 文件:
language: node_js
node_js:
- "4"
sudo: false
script:
- "npm run test-cov"
after_script: "npm install coveralls && cd lib && cat coverage.lcov | ../node_modules/coveralls/bin/coveralls.js && cd .."
但是这里有个问题,因为我们的 package.json 文件里有 rpio 的依赖:
"dependencies": {
"rpio": "^0.9.11"
},
"devDependencies": {
"consoler": "^0.2.0",
"chokidar": "^1.6.0",
"wait-promise": "0.4.1",
"babel-cli": "6.x.x",
"babel-runtime": "6.x.x",
"mocha": "^2.3.4",
"mocha-lcov-reporter": "^1.2.0",
"chai": "^3.4.1",
"babel-plugin-transform-coverage": "^0.1.5"
},
而这个 rpio 在 travis-ci 的集成环境里并不能编译过去,而且实际上我们测试不需要它。因此,这里需要再写一段 pre-install 脚本将它去掉:
travis_pre_install.sh
#!/bin/sh
sed -i "/"rpio": .*/d" ./package.json
然后将这个脚本 hook 到 .travis.yml 的命令中去:
language: node_js
node_js:
- "4"
sudo: false
before_install:
- sh travis_pre_install.sh
script:
- "npm run test-cov"
after_script: "npm install coveralls && cd lib && cat coverage.lcov | ../node_modules/coveralls/bin/coveralls.js && cd .."
最后,将代码提交到 github,就能完成自动化的持续集成了: 
自动的单元测试代码覆盖度检查也是正常的(如果现在测试覆盖度低,请忽略,因为这个库还在更新中~):
总结
我们要做的事情目标很明确:构建一套适合于树莓派(实际上也适合于其他硬件开发)的纯软件 TDD 方法。在这里我用到了各种技术的组合来实现我的目的,包括:
- 用启进程读写文件的方式来模拟信号输入
- 用 Babel 插件实现模拟库代替真实库
- 用 bash 脚本来实现集成环境的编译预处理
我们会发现,工程师自己实现一个代码库,尤其是涉及工程化的一些工作的时候,知识的广度会很重要。
而且,合理使用各种知识最终解决问题也是一个有趣的过程,不是吗?
有任何问题,欢迎留言区讨论。