Chromium网页光栅化过程分析
在前面一篇文章中,我们分析了网页CC Layer Tree同步为CC Pending Layer Tree的过程。同步操作完成后,CC Pending Layer Tree中的每一个Layer都会被划分成一系列的分块,并且每一个分块都会被赋予一个优先级。接下来CC模块会根据优先级对分块进行排序。优先级越高的分块越排在前面,越排在前面的分块就越快得到光栅化。本文接下来就详细分析网页分块的光栅化过程。
CC Pending Layer Tree的光栅化操作是由调度器发起的,它对应于网页渲染过程中的第4个步骤ACTION_MANAGE_TILES,如下所示:
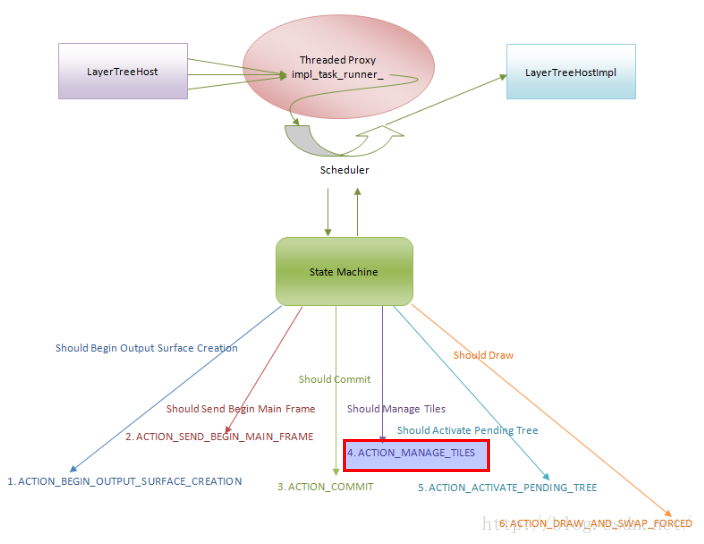
图1 CC Pending Layer Tree光栅化操作的时机
从前面Chromium网页渲染调度器(Scheduler)实现分析一文可以知道,当调度器调用SchedulerStateMachine类的成员函数NextAction询问状态机下一步要执行的操作时,SchedulerStateMachine类的成员函数NextAction会调用另外一个成员函数ShouldManageTiles。当SchedulerStateMachine类的成员函数ShouldManageTiles返回值等于true的时候,状态机就会提示调度器接下来需要执行ACTION_MANAGE_TILES操作,也就是对CC Pending Layer Tree进行光栅化操作,如下所示:
SchedulerStateMachine::Action SchedulerStateMachine::NextAction() const {
......
if (ShouldManageTiles())
return ACTION_MANAGE_TILES;
......
return ACTION_NONE;
}这个函数定义在文件external/chromium_org/cc/scheduler/scheduler_state_machine.cc中。
接下来我们就继续分析SchedulerStateMachine类的成员函数ShouldManageTiles什么情况下会返回true,它的实现如下所示:
bool SchedulerStateMachine::ShouldManageTiles() const {
// ManageTiles only really needs to be called immediately after commit
// and then periodically after that. Use a funnel to make sure we average
// one ManageTiles per BeginImplFrame in the long run.
if (manage_tiles_funnel_ > 0)
return false;
// Limiting to once per-frame is not enough, since we only want to
// manage tiles _after_ draws. Polling for draw triggers and
// begin-frame are mutually exclusive, so we limit to these two cases.
if (begin_impl_frame_state_ != BEGIN_IMPL_FRAME_STATE_INSIDE_DEADLINE &&
!inside_poll_for_anticipated_draw_triggers_)
return false;
return needs_manage_tiles_;
}这个函数定义在文件external/chromium_org/cc/scheduler/scheduler_state_machine.cc中。
每次执行了一个ACTION_MANAGE_TILES操作时,SchedulerStateMachine类的成员变量manage_tiles_funnel_的值就会增加1。等到下一个VSync信号到来时,SchedulerStateMachine类的成员变量manage_tiles_funnel_的值才会减少1。SchedulerStateMachine类通过这种方式控制在一个VSync周期内,只能执行一次ACTION_MANAGE_TILES操作,也就是当成员变量manage_tiles_funnel_的值大于0时,SchedulerStateMachine类的成员函数ShouldManageTiles的返回值会等于false,表示不能在当前VSync周期内再次执行ACTION_MANAGE_TILES操作。
除了控制一个VSync周期只执行一次ACTION_MANAGE_TILES操作,SchedulerStateMachine类还控制ACTION_MANAGE_TILES操作的执行时间点。在一个VSync周期内,只有当状态机的BeginImplFrameState状态等于BEGIN_IMPL_FRAME_STATE_INSIDE_DEADLINE时,也就是成员变量begin_impl_frame_state_的值等于BEGIN_IMPL_FRAME_STATE_INSIDE_DEADLINE时,SchedulerStateMachine类的成员函数ShouldManageTiles才允许执行ACTION_MANAGE_TILES操作。关于状态机的BeginImplFrameState状态,可以参考前面Chromium网页渲染调度器(Scheduler)实现分析一文。
另外,如果调度器启动了Polling机制推进渲染管线,那么在Polling期间,SchedulerStateMachine类的成员变量inside_poll_for_anticipated_draw_triggers_会被设置为true,表示允许执行ACTION_MANAGE_TILES操作的。Polling是一种不依赖于VSync信号的机制,我们在前面Chromium网页渲染调度器(Scheduler)实现分析一文中有提及到。
最后,在以上描述的条件成立的前提下,如果网页的分块发生了变化,例如新创建了分块、分块优先级发生了变化等,那么SchedulerStateMachine类的成员函数ShouldManageTiles的返回值就会等于true,表示要执行一个ACTION_MANAGE_TILES操作。
从前面Chromium网页Layer Tree同步为Pending Layer Tree的过程分析一文可以知道,当网页的分块发生了变化时,SchedulerStateMachine类的成员变量needs_manage_tiles_就会被设置为true,这样就会导致SchedulerStateMachine类的成员函数ShouldManageTiles的返回值为true。
回到SchedulerStateMachine类的成员函数NextAction中,当它调用成员函数ShouldManageTiles得到的返回值等于true,它就会返回一个ACTION_MANAGE_TILES给Scheduler类的成员函数ProcessScheduledActions。这时候Scheduler类的成员函数ProcessScheduledActions就会请求Compositor线程对网页中的分块执行光栅化操作,如下所示:
void Scheduler::ProcessScheduledActions() {
......
SchedulerStateMachine::Action action;
do {
action = state_machine_.NextAction();
......
state_machine_.UpdateState(action);
......
switch (action) {
......
case SchedulerStateMachine::ACTION_MANAGE_TILES:
client_->ScheduledActionManageTiles();
break;
}
} while (action != SchedulerStateMachine::ACTION_NONE);
SetupNextBeginFrameIfNeeded();
......
if (state_machine_.ShouldTriggerBeginImplFrameDeadlineEarly()) {
......
ScheduleBeginImplFrameDeadline(base::TimeTicks());
}
} 这个函数定义在文件external/chromium_org/cc/scheduler/scheduler.cc中。
Scheduler类的成员函数ProcessScheduledActions的详细分析可以参考前面Chromium网页渲染调度器(Scheduler)实现分析一文。这时候Scheduler类的成员函数ProcessScheduledActions首先调用SchedulerStateMachine类的成员函数UpdateState更新状态机的状态,接着再调用成员变量client_指向的一个ThreadProxy对象的成员函数ScheduledActionManageTiles请求Compositor线程对网页中的分块执行光栅化操作。
SchedulerStateMachine类的成员函数UpdateState的实现如下所示:
void SchedulerStateMachine::UpdateState(Action action) {
switch (action) {
......
case ACTION_MANAGE_TILES:
UpdateStateOnManageTiles();
return;
}
}这个函数定义在文件external/chromium_org/cc/scheduler/scheduler_state_machine.cc中。
SchedulerStateMachine类的成员函数UpdateState调用另外一个成员函数UpdateStateOnManageTiles将成员变量needs_manage_tiles_的值设置为false,表示网页上一次发生的分块变化已经得到了处理,如下所示:
void SchedulerStateMachine::UpdateStateOnManageTiles() {
needs_manage_tiles_ = false;
}这个函数定义在文件external/chromium_org/cc/scheduler/scheduler_state_machine.cc中。
回到Scheduler类的成员函数ProcessScheduledActions中,它修改了状态机的状态之后,接下来调用ThreadProxy类的成员函数ScheduledActionManageTiles请求Compositor线程对网页中的分块执行光栅化操作,如下所示:
void ThreadProxy::ScheduledActionManageTiles() {
......
impl().layer_tree_host_impl->ManageTiles();
}这个函数定义在文件external/chromium_org/cc/trees/thread_proxy.cc中。
ThreadProxy类的成员函数ScheduledActionCommit首先调用成员函数impl获得一个CompositorThreadOnly对象。这个CompositorThreadOnly对象的成员变量layer_tree_host_impl指向一个LayerTreeHostImpl对象。这个LayerTreeHostImpl对象负责管理CC Pending Layer Tree和CC Active Layer Tree。有了这个LayerTreeHostImpl对象之后,ThreadProxy类的成员函数ScheduledActionCommit再调用它的成员函数ManageTiles对网页中的分块执行光栅化操作。
LayerTreeHostImpl类的成员函数ManageTiles的实现如下所示:
void LayerTreeHostImpl::ManageTiles() {
if (!tile_manager_)
return;
if (!tile_priorities_dirty_)
return;
tile_priorities_dirty_ = false;
tile_manager_->ManageTiles(global_tile_state_);
......
}这个函数定义在文件external/chromium_org/cc/trees/layer_tree_host_impl.cc中。
从前面Chromium网页绘图表面(Output Surface)创建过程分析一文可以知道,LayerTreeHostImpl类的成员变量tile_manager_指向的是一个TileManager对象。这个TileManager对象是负责管理网页的分块的。
从前面Chromium网页Layer Tree同步为Pending Layer Tree的过程分析一文又可以知道,当LayerTreeHostImpl类的成员变量tile_priorities_dirty_的值等于true时,就表示网页的分块发生了变化。
只有在负责管理网页分块的TileManager对象已经创建,并且网页分块发生过变化的情况下,LayerTreeHostImpl类的成员函数ManageTiles才会调用TileManager类的成员函数ManageTiles对网页分块执行光栅化操作。
TileManager类的成员函数ManageTiles的实现如下所示:
void TileManager::ManageTiles(const GlobalStateThatImpactsTilePriority& state) {
......
UpdatePrioritizedTileSetIfNeeded();
TileVector tiles_that_need_to_be_rasterized;
AssignGpuMemoryToTiles(&prioritized_tiles_,
&tiles_that_need_to_be_rasterized);
// Finally, schedule rasterizer tasks.
ScheduleTasks(tiles_that_need_to_be_rasterized);
......
}这个函数定义在文件external/chromium_org/cc/resources/tile_manager.cc中。
TileManager类的成员函数ManageTiles主要是做三件事情:
1. 调用成员函数UpdatePrioritizedTileSetIfNeeded根据优先级对网页中的分块进行排序。
2. 调用成员函数AssignGpuMemoryToTiles根据上述排序以及GPU内存策略获取当前需要执行光栅化操作的分块。
3. 调用成员函数ScheduleTasks对第2步获得的分块执行光栅化操作。
接下来我们就分别分析这三个成员函数的实现,以便了解网页分块的光栅化过程。
TileManager类的成员函数UpdatePrioritizedTileSetIfNeeded的实现如下所示:
void TileManager::UpdatePrioritizedTileSetIfNeeded() {
if (!prioritized_tiles_dirty_)
return;
CleanUpReleasedTiles();
prioritized_tiles_.Clear();
GetTilesWithAssignedBins(&prioritized_tiles_);
prioritized_tiles_dirty_ = false;
}这个函数定义在文件external/chromium_org/cc/resources/tile_manager.cc中。
从前面Chromium网页Layer Tree同步为Pending Layer Tree的过程分析一文可以知道,当TileManager类的成员变量prioritized_tiles_dirty_的值等于true时,就表示网页的分块发生了变化,这时候TileManager类的成员函数UpdatePrioritizedTileSetIfNeeded就会对网页的所有分块重新进行排序。
在对分块重新进行排序之前,TileManager类的成员函数UpdatePrioritizedTileSetIfNeeded会先调用成员函数CleanUpReleasedTiles回收那些不再使用了的分块占用的资源,如下所示:
void TileManager::CleanUpReleasedTiles() {
for (std::vector<Tile*>::iterator it = released_tiles_.begin();
it != released_tiles_.end();
++it) {
Tile* tile = *it;
ManagedTileState& mts = tile->managed_state();
for (int mode = 0; mode < NUM_RASTER_MODES; ++mode) {
FreeResourceForTile(tile, static_cast<RasterMode>(mode));
......
}
......
tiles_.erase(tile->id());
......
delete tile;
}
released_tiles_.clear();
}这个函数定义在文件external/chromium_org/cc/resources/tile_manager.cc中。
不再使用的分块都保存在TileManager类的成员变量released_tiles_描述的一个std::vector中。TileManager类的成员函数CleanUpReleasedTiles遍历保存在这个std::vector中的每一个分块。对于每一个分块,首先调用TileManager类的成员函数FreeResourceForTile释放它所占用的资源,接着又将它从TileManager类的成员变量tiles_描述的一个Tile Map中移除,最后删除用来描述该分块的Tile对象。遍历完毕,TileManager类的成员函数CleanUpReleasedTiles就清空成员变量released_tiles_描述的std::vector。
一个分块有可能是按照High Res模式进行光栅化,也有可能按照Low Res模式进行光栅化。这些光栅化模式由一个ManagedTileState对象进行管理。通过调用Tile类的成员函数managed_state可以获得这个ManagedTileState对象,如下所示:
class CC_EXPORT Tile : public RefCountedManaged<Tile> {
......
private:
......
ManagedTileState& managed_state() { return managed_state_; }
......
ManagedTileState managed_state_;
......
};这个函数定义在文件external/chromium_org/cc/resources/tile.h中。
ManagedTileState类有一个成员变量tile_versions,它是一个大小为2的TileVersion数组,如下所示:
class CC_EXPORT ManagedTileState {
public:
class CC_EXPORT TileVersion {
public:
enum Mode { RESOURCE_MODE, SOLID_COLOR_MODE, PICTURE_PILE_MODE };
......
private:
......
Mode mode_;
SkColor solid_color_;
scoped_ptr<ScopedResource> resource_;
scoped_refptr<RasterTask> raster_task_;
};
......
TileVersion tile_versions[NUM_RASTER_MODES];
RasterMode raster_mode;
TileResolution resolution;
bool required_for_activation;
TilePriority::PriorityBin priority_bin;
float distance_to_visible;
bool visible_and_ready_to_draw;
......
};这个类定义在文件external/chromium_org/cc/resources/managed_tile_state.h中。
NUM_RASTER_MODES是一个类型为RasterMode的枚举值,它的定义如下所示:
enum RasterMode {
HIGH_QUALITY_RASTER_MODE = 0,
LOW_QUALITY_RASTER_MODE = 1,
NUM_RASTER_MODES = 2
};这个枚举定义在文件external/chromium_org/cc/resources/raster_mode.h中。
从这里就可以看到,NUM_RASTER_MODES的值定义为2。另外两个枚举值HIGH_QUALITY_RASTER_MODE和LOW_QUALITY_RASTER_MODE分别定义为0和1,分别表示High Res和Low Res两种光栅化模式。
回到ManagedTileState类中,它通过TileVersion类来描述分块的光栅化模式。每一种光栅化模式又有三种光栅化方式:
-
RESOURCE_MODE:分块光栅化在一个独立的纹理资源上,这个纹理资源由成员变量resource_描述。
-
SOLID_COLOR_MODE:分块的光栅化结果是一个单一的颜色,这个颜色值由成员变量solid_color_描述。
-
PICTURE_PILE_MODE:分块也是光栅化在一个纹理资源上,但是这个纹理资源是按需(On Demand)创建的,不是由分块所拥有。
TileVersion类还有另外两个成员变量mode_和rastertask。其中,成员变量mode_描述一个TileVersion对象是使用High Res光栅化模式,还是Low Res光栅化模式;当成员变量raster_task_的值不等于NULL的时候,表示正在对分块执行光栅化操作。
再回到ManagedTileState类中,它有另外几个重要的成员变量,用来描述分块的光栅化状态:
1. raster_mode:表示分块当前所使用的光栅化模式化,它的值要么等于HIGH_QUALITY_RASTER_MODE,要么等于LOW_QUALITY_RASTER_MODE。
-
bin:表示分块所属的Managed Tile Bin。Tile Manager对分块进行排序时,具有相同Managed Tile Bin属性的分块会归为同一类。
-
resolution:表示分块的Resolution属性,也就是它是以High Res模式进行光栅化,还是以Low Res模式进行光栅化。
-
required_for_activation:表示分块光栅化完成后是否需要将CC Pending Layer Tree激活为CC Active Layer Tree。
-
priority_bin:表示分块的Priority Bin属性,也就是分块的优先级,这个优先级综合考虑了分块在CC Pending Layer Tree和CC Active Layer Tree的优先级。
-
distance_to_visible:表示分块与当前帧的Viewport的距离。
-
visible_and_ready_to_draw:表示分块在当前帧是可见的,并且它已经被分配了纹理资源。
分块的Bin属性通过枚举类型ManagedTileBin描述,它的定义如下所示:
// Tile manager classifying tiles into a few basic bins:
enum ManagedTileBin {
NOW_AND_READY_TO_DRAW_BIN = 0, // Ready to draw and within viewport.
NOW_BIN = 1, // Needed ASAP.
SOON_BIN = 2, // Impl-side version of prepainting.
EVENTUALLY_AND_ACTIVE_BIN = 3, // Nice to have, and has a task or resource.
EVENTUALLY_BIN = 4, // Nice to have, if we've got memory and time.
AT_LAST_AND_ACTIVE_BIN = 5, // Only do this after all other bins.
AT_LAST_BIN = 6, // Only do this after all other bins.
NEVER_BIN = 7, // Dont bother.
NUM_BINS = 8
// NOTE: Be sure to update ManagedTileBinAsValue and kBinPolicyMap when adding
// or reordering fields.
};这个枚举定义在文件external/chromium_org/cc/resources/managed_tile_state.h中。
ManagedTileBin一共定义了7个Managed Tile Bin,数值越小的Managed Tile Bin,其重要性越高,属于这个Managed Tile Bin的分块就越优先获得光栅化。
分块的Resolution属性通过枚举类型TileResolution描述,它的定义如下所示:
enum TileResolution {
LOW_RESOLUTION = 0 ,
HIGH_RESOLUTION = 1,
NON_IDEAL_RESOLUTION = 2,
};这个枚举定义在文件external/chromium_org/cc/resources/tile_priority.h中。
TileResolution一共定义了3种Resolution:LOW_RESOLUTION、 HIGH_RESOLUTION和NON_IDEAL_RESOLUTION。其中,Resolution属性等于LOW_RESOLUTION、或者HIGH_RESOLUTION的分块都是当前需要使用的,而Resolution属性等于NON_IDEAL_RESOLUTION的分块不是当前需要使用的。
分块的Priority Bin属性通过枚举类型PriorityBin描述,它的定义如下所示:
struct CC_EXPORT TilePriority {
enum PriorityBin { NOW, SOON, EVENTUALLY };
......
};这个枚举定义在文件external/chromium_org/cc/resources/tile_priority.h中。
PriorityBin一共定义了3种优先级:NOW、SOON、EVENTUALLY。其中,NOW表示分块在当前帧的Viewport中,需要马上渲染出来,SOON表示分块离当前帧的Viewport很近,很快需要渲染出来,EVENTUALLY表示分块离当前帧的Viewport较远,但是最终可能是需要渲染出来的。
从前面Chromium网页Layer Tree同步为Pending Layer Tree的过程分析一文可以知道,分块在创建或者发生变化时,它的优先级,也就是Priority Bin属性就会被重新计算。接下来Tile Manager会根据分块的Priority Bin属性和其它属性,将它们划分在一系列的Managed Tile Bin中。Managed Tile Bin可以看作是对Priority Bin的进一步细分,这样就可以进一步区分分块的重要程度。
ManagedTileState类的各个成员变量更具体的含义和用法,我们后面分析分块的排序过程再详细分析。
理解了分块的光栅化模式之后,回到TileManager类的成员函数CleanUpReleasedTiles中,我们就可以理解为什么要通过一个for循环释放一个分块所占用的资源。每一次循环释放的是一个光栅化模式所占用的资源。这是通过调用TileManager类的成员函数FreeResourceForTile实现的,如下所示:
void TileManager::FreeResourceForTile(Tile* tile, RasterMode mode) {
ManagedTileState& mts = tile->managed_state();
if (mts.tile_versions[mode].resource_) {
resource_pool_->ReleaseResource(mts.tile_versions[mode].resource_.Pass());
......
bytes_releasable_ -= BytesConsumedIfAllocated(tile);
--resources_releasable_;
}
}这个函数定义在文件external/chromium_org/cc/resources/tile_manager.cc中。
从前面Chromium网页绘图表面(Output Surface)创建过程分析一文可以知道,TileManager类的成员resource_pool_指向的是一个ResourcePool对象,通过调用这个ResourcePool对象的成员函数ReleaseResource可以释放指定的资源,也就是参数tile描述的光栅化模式为mode的分块所占用的资源。
TileManager类的成员变量bytes_releasable_表示当前可释放的资源所占用的总字节数,另外一个成员变量resources_releasable_表示当前可释放的资源个数。当指定的资源被释放后,TileManager类的成员函数FreeResourceForTile需要相应地调整上述两个成员变量的值。
释放了那些不再使用了的分块占用的资源之后, 回到TileManager类的成员函数UpdatePrioritizedTileSetIfNeeded中,它接下来调用另外一个成员函数GetTilesWithAssignedBins对网页中的分块重新进行排序。这些已经排序完成的分块将会保存在TileManager类的成员变量prioritized_tiles_描述的一个PrioritizedTileSet对象中。
TileManager类的成员函数GetTilesWithAssignedBins的实现如下所示:
void TileManager::GetTilesWithAssignedBins(PrioritizedTileSet* tiles) {
TRACE_EVENT0("cc", "TileManager::GetTilesWithAssignedBins");
const TileMemoryLimitPolicy memory_policy = global_state_.memory_limit_policy;
const TreePriority tree_priority = global_state_.tree_priority;
// For each tree, bin into different categories of tiles.
for (TileMap::const_iterator it = tiles_.begin(); it != tiles_.end(); ++it) {
Tile* tile = it->second;
ManagedTileState& mts = tile->managed_state();
const ManagedTileState::TileVersion& tile_version =
tile->GetTileVersionForDrawing();
bool tile_is_ready_to_draw = tile_version.IsReadyToDraw();
bool tile_is_active = tile_is_ready_to_draw ||
mts.tile_versions[mts.raster_mode].raster_task_;
// Get the active priority and bin.
TilePriority active_priority = tile->priority(ACTIVE_TREE);
ManagedTileBin active_bin = BinFromTilePriority(active_priority);
// Get the pending priority and bin.
TilePriority pending_priority = tile->priority(PENDING_TREE);
ManagedTileBin pending_bin = BinFromTilePriority(pending_priority);
bool pending_is_low_res = pending_priority.resolution == LOW_RESOLUTION;
bool pending_is_non_ideal =
pending_priority.resolution == NON_IDEAL_RESOLUTION;
bool active_is_non_ideal =
active_priority.resolution == NON_IDEAL_RESOLUTION;
// Adjust bin state based on if ready to draw.
active_bin = kBinReadyToDrawMap[tile_is_ready_to_draw][active_bin];
pending_bin = kBinReadyToDrawMap[tile_is_ready_to_draw][pending_bin];
// Adjust bin state based on if active.
active_bin = kBinIsActiveMap[tile_is_active][active_bin];
pending_bin = kBinIsActiveMap[tile_is_active][pending_bin];
// We never want to paint new non-ideal tiles, as we always have
// a high-res tile covering that content (paint that instead).
if (!tile_is_ready_to_draw && active_is_non_ideal)
active_bin = NEVER_BIN;
if (!tile_is_ready_to_draw && pending_is_non_ideal)
pending_bin = NEVER_BIN;
ManagedTileBin tree_bin[NUM_TREES];
tree_bin[ACTIVE_TREE] = kBinPolicyMap[memory_policy][active_bin];
tree_bin[PENDING_TREE] = kBinPolicyMap[memory_policy][pending_bin];
// Adjust pending bin state for low res tiles. This prevents pending tree
// low-res tiles from being initialized before high-res tiles.
if (pending_is_low_res)
tree_bin[PENDING_TREE] = std::max(tree_bin[PENDING_TREE], EVENTUALLY_BIN);
TilePriority tile_priority;
switch (tree_priority) {
case SAME_PRIORITY_FOR_BOTH_TREES:
mts.bin = std::min(tree_bin[ACTIVE_TREE], tree_bin[PENDING_TREE]);
tile_priority = tile->combined_priority();
break;
case SMOOTHNESS_TAKES_PRIORITY:
mts.bin = tree_bin[ACTIVE_TREE];
tile_priority = active_priority;
break;
case NEW_CONTENT_TAKES_PRIORITY:
mts.bin = tree_bin[PENDING_TREE];
tile_priority = pending_priority;
break;
}
// Bump up the priority if we determined it's NEVER_BIN on one tree,
// but is still required on the other tree.
bool is_in_never_bin_on_both_trees = tree_bin[ACTIVE_TREE] == NEVER_BIN &&
tree_bin[PENDING_TREE] == NEVER_BIN;
if (mts.bin == NEVER_BIN && !is_in_never_bin_on_both_trees)
mts.bin = tile_is_active ? AT_LAST_AND_ACTIVE_BIN : AT_LAST_BIN;
mts.resolution = tile_priority.resolution;
mts.priority_bin = tile_priority.priority_bin;
mts.distance_to_visible = tile_priority.distance_to_visible;
mts.required_for_activation = tile_priority.required_for_activation;
mts.visible_and_ready_to_draw =
tree_bin[ACTIVE_TREE] == NOW_AND_READY_TO_DRAW_BIN;
// Tiles that are required for activation shouldn't be in NEVER_BIN unless
// smoothness takes priority or memory policy allows nothing to be
// initialized.
DCHECK(!mts.required_for_activation || mts.bin != NEVER_BIN ||
tree_priority == SMOOTHNESS_TAKES_PRIORITY ||
memory_policy == ALLOW_NOTHING);
// If the tile is in NEVER_BIN and it does not have an active task, then we
// can release the resources early. If it does have the task however, we
// should keep it in the prioritized tile set to ensure that AssignGpuMemory
// can visit it.
if (mts.bin == NEVER_BIN &&
!mts.tile_versions[mts.raster_mode].raster_task_) {
FreeResourcesForTileAndNotifyClientIfTileWasReadyToDraw(tile);
continue;
}
// Insert the tile into a priority set.
tiles->InsertTile(tile, mts.bin);
}
}这个函数定义在文件external/chromium_org/cc/resources/tile_manager.cc中。
TileManager类的成员函数GetTilesWithAssignedBins的实现比较长,我们分段来阅读。
第一段代码如下所示:
void TileManager::GetTilesWithAssignedBins(PrioritizedTileSet* tiles) {
TRACE_EVENT0("cc", "TileManager::GetTilesWithAssignedBins");
const TileMemoryLimitPolicy memory_policy = global_state_.memory_limit_policy;
const TreePriority tree_priority = global_state_.tree_priority;这段代码分别获得分块的内存使用策略memory_policy和优先级策略tree_priority。
内存使用策略通过枚举类型TileMemoryLimitPolicy描述,它的定义如下所示:
enum TileMemoryLimitPolicy {
// Nothing.
ALLOW_NOTHING = 0,
// You might be made visible, but you're not being interacted with.
ALLOW_ABSOLUTE_MINIMUM = 1, // Tall.
// You're being interacted with, but we're low on memory.
ALLOW_PREPAINT_ONLY = 2, // Grande.
// You're the only thing in town. Go crazy.
ALLOW_ANYTHING = 3, // Venti.
NUM_TILE_MEMORY_LIMIT_POLICIES = 4,
// NOTE: Be sure to update TreePriorityAsValue and kBinPolicyMap when adding
// or reordering fields.
};这个枚举类型定义在文件external/chromium_org/cc/resources/tile_priority.h中。
TileMemoryLimitPolicy一共定义了4种分块内存使用策略:
1. ALLOW_NOTHING:不给所有的Managed Tile Bin的分块分配内存。
-
ALLOW_ABSOLUTE_MINIMUM:只给类型为NOW_AND_READY_TO_DRAW_BIN和NOW_BIN的Managed Tile Bin的分块分配内存。
-
ALLOW_PREPAINT_ONLY:只给类型为NOW_AND_READY_TO_DRAW_BIN、NOW_BIN和SOON_BIN的Managed Tile Bin的分块分配内存。
-
ALLOW_ANYTHING:给除了类型为NEVER_BIN之外的Managed Tile Bin的分块分配内存。
优先级策略通过枚举类型TreePriority描述,它的定义如下所示:
enum TreePriority {
SAME_PRIORITY_FOR_BOTH_TREES,
SMOOTHNESS_TAKES_PRIORITY,
NEW_CONTENT_TAKES_PRIORITY
// Be sure to update TreePriorityAsValue when adding new fields.
};这个枚举类型定义在文件external/chromium_org/cc/resources/tile_priority.h中。
TreePriority一共定义了3种分块优先级使用策略:
-
SAME_PRIORITY_FOR_BOTH_TREES:分块在CC Pending Layer Tree和CC Active Layer Tree的优先级同等重要。
-
SMOOTHNESS_TAKES_PRIORITY:分块在CC Active Layer Tree的优先级比在CC Pending Layer Tree的优先级高。
-
NEW_CONTENT_TAKES_PRIORITY:分块在CC Pending Layer Tree的优先级比在CC Active Layer Tree的优先级高。
TileManager类的成员函数GetTilesWithAssignedBins的第二段代码如下所示:
// For each tree, bin into different categories of tiles.
for (TileMap::const_iterator it = tiles_.begin(); it != tiles_.end(); ++it) {
Tile* tile = it->second;
ManagedTileState& mts = tile->managed_state();
const ManagedTileState::TileVersion& tile_version =
tile->GetTileVersionForDrawing();
bool tile_is_ready_to_draw = tile_version.IsReadyToDraw();
bool tile_is_active = tile_is_ready_to_draw ||
mts.tile_versions[mts.raster_mode].raster_task_;从这段代码开始,TileManager类的成员函数GetTilesWithAssignedBins遍历网页中的所有分块。
对于每一个分块,也就是每一个Tile对象,TileManager类的成员函数GetTilesWithAssignedBins首先通过它的成员函数GetTileVersionForDrawing获得它当前需要渲染的版本,也就是它的光栅化模式,如下所示:
class CC_EXPORT Tile : public RefCountedManaged<Tile> {
public:
......
const ManagedTileState::TileVersion& GetTileVersionForDrawing() const {
for (int mode = 0; mode < NUM_RASTER_MODES; ++mode) {
if (managed_state_.tile_versions[mode].IsReadyToDraw())
return managed_state_.tile_versions[mode];
}
return managed_state_.tile_versions[HIGH_QUALITY_RASTER_MODE];
}
......
};这个函数定义在文件external/chromium_org/cc/resources/tile.h中。
从前面分析可以知道,每一个分块都有两种光栅化模式。一种是按照Low Res模式进行光栅化,另一种是按照High Res模式进行光栅化。Tile类的成员函数GetTileVersionForDrawing按照以下规则决定分块使用哪一种光栅化模式:
1. 如果分块在High Res光栅化模式中分配了纹理资源,那么优先选择High Res光栅化模式。
2. 如果分块在High Res光栅化模式中没有分配纹理资源,但是在Low Res光栅化模式中分配了纹理资源,那么选择Low Res光栅化模式。
3. 如果分块在High Res和Low Res光栅化模式中均还没有分配纹理资源,那么优先选择High Res光栅化模式。
总结来说,就是优先考虑以高质量模式光栅化分块,但是如果以低质量模式光栅化分块的代价很小,那么优先考虑以低质量模式光栅化分块。
回到TileManager类的成员函数GetTilesWithAssignedBins的第二段代码中,它确定了分块的光栅化模式之后,接下来再确定分块在该光栅化模式下的两个状态:
1. tile_is_ready_to_draw:表示分块是否已经准备就绪进行光栅化?也就是是否已经分配了纹理资源。一个分块只有在分配了纹理资源的前提下,才可以进行光栅化。
2. tile_is_active:表示分块是否已经激活?在两种情况下,一个分块认为当前是激活的。第一种情况是该分块已经Ready To Draw。第二种情况是该分块正在执行光栅化操作。在第二种情况下,分块已经关联了一个光栅化任务。
TileManager类的成员函数GetTilesWithAssignedBins的第三段代码如下所示:
// Get the active priority and bin.
TilePriority active_priority = tile->priority(ACTIVE_TREE);
ManagedTileBin active_bin = BinFromTilePriority(active_priority);
// Get the pending priority and bin.
TilePriority pending_priority = tile->priority(PENDING_TREE);
ManagedTileBin pending_bin = BinFromTilePriority(pending_priority);这段代码分别获取分块在CC Active Layer Tree和CC Pending Layer Tree中的优先级active_priority和pending_priority,并且通过调用函数BinFromTilePriority获得这两个优先级所对应的Managed Tile Bin,如下所示:
// Determine bin based on three categories of tiles: things we need now,
// things we need soon, and eventually.
inline ManagedTileBin BinFromTilePriority(const TilePriority& prio) {
if (prio.priority_bin == TilePriority::NOW)
return NOW_BIN;
if (prio.priority_bin == TilePriority::SOON)
return SOON_BIN;
if (prio.distance_to_visible == std::numeric_limits<float>::infinity())
return NEVER_BIN;
return EVENTUALLY_BIN;
}这个函数定义在文件external/chromium_org/cc/resources/tile_manager.cc中。
从函数BinFromTilePriority的实现可以知道:
1. 优先级为NOW的分块对应的Managed Tile Bin为NOW_BIN。
- 优先级为SOON的分块对应的Managed Tile Bin为SOON_BIN。
3. 距离当前帧的Viewport无穷远的分块对应的Managed Tile Bin为NEVER_BIN。
4. 优先级不等于NOW和SOON,并且距离当前帧的Viewport不是无穷远的分块对应的Managed Tile Bin为EVENTUALLY_BIN。
TileManager类的成员函数GetTilesWithAssignedBins的第四段代码如下所示:
bool pending_is_low_res = pending_priority.resolution == LOW_RESOLUTION;
bool pending_is_non_ideal =
pending_priority.resolution == NON_IDEAL_RESOLUTION;
bool active_is_non_ideal =
active_priority.resolution == NON_IDEAL_RESOLUTION;这段代码检查分块在CC Pending Layer Tree中对应的分辨率是否为LOW_RESOLUTION和NON_IDEAL_RESOLUTION,以及分块在CC Active Layer Tree中对应的分辨率是否为NON_IDEAL_RESOLUTION。
TileManager类的成员函数GetTilesWithAssignedBins的第五段代码如下所示:
// Adjust bin state based on if ready to draw.
active_bin = kBinReadyToDrawMap[tile_is_ready_to_draw][active_bin];
pending_bin = kBinReadyToDrawMap[tile_is_ready_to_draw][pending_bin];这段代码根据分块是否已经准备就绪光栅化相应地调整它的Acitve Managed Tile Bin和Pending Managed Tile Bin。这个调整过程是通过一个kBinReadyToDrawMap数组进行的,如下所示:
// Ready to draw works by mapping NOW_BIN to NOW_AND_READY_TO_DRAW_BIN.
const ManagedTileBin kBinReadyToDrawMap[2][NUM_BINS] = {
// Not ready
{NOW_AND_READY_TO_DRAW_BIN, // [NOW_AND_READY_TO_DRAW_BIN]
NOW_BIN, // [NOW_BIN]
SOON_BIN, // [SOON_BIN]
EVENTUALLY_AND_ACTIVE_BIN, // [EVENTUALLY_AND_ACTIVE_BIN]
EVENTUALLY_BIN, // [EVENTUALLY_BIN]
AT_LAST_AND_ACTIVE_BIN, // [AT_LAST_AND_ACTIVE_BIN]
AT_LAST_BIN, // [AT_LAST_BIN]
NEVER_BIN // [NEVER_BIN]
},
// Ready
{NOW_AND_READY_TO_DRAW_BIN, // [NOW_AND_READY_TO_DRAW_BIN]
NOW_AND_READY_TO_DRAW_BIN, // [NOW_BIN]
SOON_BIN, // [SOON_BIN]
EVENTUALLY_AND_ACTIVE_BIN, // [EVENTUALLY_AND_ACTIVE_BIN]
EVENTUALLY_BIN, // [EVENTUALLY_BIN]
AT_LAST_AND_ACTIVE_BIN, // [AT_LAST_AND_ACTIVE_BIN]
AT_LAST_BIN, // [AT_LAST_BIN]
NEVER_BIN // [NEVER_BIN]
}};
这个数组定义在文件external/chromium_org/cc/resources/tile_manager.cc中。
从这个数组的定义可以看出,它主要是将那些已经准备就绪光栅化的分块的Managed Tile Bin,从NOW_BIN提升为NOW_AND_READY_TO_DRAW_BIN,其余的都保持不变。
TileManager类的成员函数GetTilesWithAssignedBins的第六段代码如下所示:
// Adjust bin state based on if active.
active_bin = kBinIsActiveMap[tile_is_active][active_bin];
pending_bin = kBinIsActiveMap[tile_is_active][pending_bin];这段代码根据分块是否激活相应地调整它的Acitve Managed Tile Bin和Pending Managed Tile Bin。这个调整过程是通过一个kBinIsActiveMap数组进行的,如下所示:
// Active works by mapping some bin stats to equivalent _ACTIVE_BIN state.
const ManagedTileBin kBinIsActiveMap[2][NUM_BINS] = {
// Inactive
{NOW_AND_READY_TO_DRAW_BIN, // [NOW_AND_READY_TO_DRAW_BIN]
NOW_BIN, // [NOW_BIN]
SOON_BIN, // [SOON_BIN]
EVENTUALLY_AND_ACTIVE_BIN, // [EVENTUALLY_AND_ACTIVE_BIN]
EVENTUALLY_BIN, // [EVENTUALLY_BIN]
AT_LAST_AND_ACTIVE_BIN, // [AT_LAST_AND_ACTIVE_BIN]
AT_LAST_BIN, // [AT_LAST_BIN]
NEVER_BIN // [NEVER_BIN]
},
// Active
{NOW_AND_READY_TO_DRAW_BIN, // [NOW_AND_READY_TO_DRAW_BIN]
NOW_BIN, // [NOW_BIN]
SOON_BIN, // [SOON_BIN]
EVENTUALLY_AND_ACTIVE_BIN, // [EVENTUALLY_AND_ACTIVE_BIN]
EVENTUALLY_AND_ACTIVE_BIN, // [EVENTUALLY_BIN]
AT_LAST_AND_ACTIVE_BIN, // [AT_LAST_AND_ACTIVE_BIN]
AT_LAST_AND_ACTIVE_BIN, // [AT_LAST_BIN]
NEVER_BIN // [NEVER_BIN]
}};这个数组定义在文件external/chromium_org/cc/resources/tile_manager.cc中。
从这个数组的定义可以看出,它主要是将那些已经激活的分块的Managed Tile Bin,从EVENTUALLY_BIN提升为EVENTUALLY_AND_ACTIVE_BIN,以及从AT_LAST_BIN提升为AT_LAST_AND_ACTIVE_BIN,其余的都保持不变。
TileManager类的成员函数GetTilesWithAssignedBins的第七段代码如下所示:
// We never want to paint new non-ideal tiles, as we always have
// a high-res tile covering that content (paint that instead).
if (!tile_is_ready_to_draw && active_is_non_ideal)
active_bin = NEVER_BIN;
if (!tile_is_ready_to_draw && pending_is_non_ideal)
pending_bin = NEVER_BIN;这段代码检查分块是否是不激活的。如果不是激活的,并且它的分辨率状态又是属于NON_IDEAL_RESOLUTION的,那么它的Managed Tile Bin就会降级为NEVER_BIN。
TileManager类的成员函数GetTilesWithAssignedBins的第八段代码如下所示:
ManagedTileBin tree_bin[NUM_TREES];
tree_bin[ACTIVE_TREE] = kBinPolicyMap[memory_policy][active_bin];
tree_bin[PENDING_TREE] = kBinPolicyMap[memory_policy][pending_bin];这段代码根据分块内存使用策略调整分块的Acitve Managed Tile Bin和Pending Managed Tile Bin。这个调整过程是通过一个kBinPolicyMap数组进行的,如下所示:
// Memory limit policy works by mapping some bin states to the NEVER bin.
const ManagedTileBin kBinPolicyMap[NUM_TILE_MEMORY_LIMIT_POLICIES][NUM_BINS] = {
// [ALLOW_NOTHING]
{NEVER_BIN, // [NOW_AND_READY_TO_DRAW_BIN]
NEVER_BIN, // [NOW_BIN]
NEVER_BIN, // [SOON_BIN]
NEVER_BIN, // [EVENTUALLY_AND_ACTIVE_BIN]
NEVER_BIN, // [EVENTUALLY_BIN]
NEVER_BIN, // [AT_LAST_AND_ACTIVE_BIN]
NEVER_BIN, // [AT_LAST_BIN]
NEVER_BIN // [NEVER_BIN]
},
// [ALLOW_ABSOLUTE_MINIMUM]
{NOW_AND_READY_TO_DRAW_BIN, // [NOW_AND_READY_TO_DRAW_BIN]
NOW_BIN, // [NOW_BIN]
NEVER_BIN, // [SOON_BIN]
NEVER_BIN, // [EVENTUALLY_AND_ACTIVE_BIN]
NEVER_BIN, // [EVENTUALLY_BIN]
NEVER_BIN, // [AT_LAST_AND_ACTIVE_BIN]
NEVER_BIN, // [AT_LAST_BIN]
NEVER_BIN // [NEVER_BIN]
},
// [ALLOW_PREPAINT_ONLY]
{NOW_AND_READY_TO_DRAW_BIN, // [NOW_AND_READY_TO_DRAW_BIN]
NOW_BIN, // [NOW_BIN]
SOON_BIN, // [SOON_BIN]
NEVER_BIN, // [EVENTUALLY_AND_ACTIVE_BIN]
NEVER_BIN, // [EVENTUALLY_BIN]
NEVER_BIN, // [AT_LAST_AND_ACTIVE_BIN]
NEVER_BIN, // [AT_LAST_BIN]
NEVER_BIN // [NEVER_BIN]
},
// [ALLOW_ANYTHING]
{NOW_AND_READY_TO_DRAW_BIN, // [NOW_AND_READY_TO_DRAW_BIN]
NOW_BIN, // [NOW_BIN]
SOON_BIN, // [SOON_BIN]
EVENTUALLY_AND_ACTIVE_BIN, // [EVENTUALLY_AND_ACTIVE_BIN]
EVENTUALLY_BIN, // [EVENTUALLY_BIN]
AT_LAST_AND_ACTIVE_BIN, // [AT_LAST_AND_ACTIVE_BIN]
AT_LAST_BIN, // [AT_LAST_BIN]
NEVER_BIN // [NEVER_BIN]
}};这个数组定义在文件external/chromium_org/cc/resources/tile_manager.cc中。
从这个数组可以看出:
1. 当分块内存使用策略为ALLOW_NOTHING时,所有的Managed Tile Bin都将降级为NEVER_BIN。
2. 当分块内存使用策略为ALLOW_ABSOLUTE_MINIMUM时,除了类型为NOW_AND_READY_TO_DRAW_BIN和NOW_BIN的Managed Tile Bin,其余的均降级为NEVER_BIN。
- 当分块内存使用策略为ALLOW_PREPAINT_ONLY时,除了类型为NOW_AND_READY_TO_DRAW_BIN、NOW_BIN和SOON_BIN的Managed Tile Bin,其余的均降级为NEVER_BIN。
4. 当分块内存使用策略为ALLOW_ANYTHING时,分块的Managed Tile Bin保持不变。
TileManager类的成员函数GetTilesWithAssignedBins的第九段代码如下所示:
// Adjust pending bin state for low res tiles. This prevents pending tree
// low-res tiles from being initialized before high-res tiles.
if (pending_is_low_res)
tree_bin[PENDING_TREE] = std::max(tree_bin[PENDING_TREE], EVENTUALLY_BIN);这段代码检查分块在CC Pending Layer Tree中对应的分辨率是否为LOW_RESOLUTION。如果是的话,就检查它的Pending Managed Tile Bin是否比EVENTUALLY_BIN的优先级高。如果是的话,那么就将它降级为EVENTUALLY_BIN。这样做的目的是降低低分辨率分块的光栅化优先级,使得高分辨率分块可以优先得到光栅化。
TileManager类的成员函数GetTilesWithAssignedBins的第十段代码如下所示:
TilePriority tile_priority;
switch (tree_priority) {
case SAME_PRIORITY_FOR_BOTH_TREES:
mts.bin = std::min(tree_bin[ACTIVE_TREE], tree_bin[PENDING_TREE]);
tile_priority = tile->combined_priority();
break;
case SMOOTHNESS_TAKES_PRIORITY:
mts.bin = tree_bin[ACTIVE_TREE];
tile_priority = active_priority;
break;
case NEW_CONTENT_TAKES_PRIORITY:
mts.bin = tree_bin[PENDING_TREE];
tile_priority = pending_priority;
break;
}
这段代码根据分块优先级策略决定将一个分块划分到哪一个Managed Tile Bin去:
1. 当分块优先级策略等于SAME_PRIORITY_FOR_BOTH_TREES时,在分块的Acitve Managed Tile Bin和Pending Managed Tile Bin之间选择优先级高者作为最终的Managed Tile Bin,同时将分块在CC Active Layer Tree和CC Pending Layer Tree的优先级综合起来得到最终的优先级。这个综合过程是通过调用Tile类的成员函数combined_priority实现的,具体可以参考前面Chromium网页Layer Tree同步为Pending Layer Tree的过程分析一文。
-
当分块优先级策略等于SMOOTHNESS_TAKES_PRIORITY时,将分块的Acitve Managed Tile Bin作为最终的Managed Tile Bin,同时将分块在CC Active Layer Tree中的优先级设置为最终的优先级。
-
当分块优先级策略等于NEW_CONTENT_TAKES_PRIORITY时,将分块的Pending Managed Tile Bin作为最终的Managed Tile Bin,同时将分块在CC Pending Layer Tree中的优先级设置为最终的优先级。
TileManager类的成员函数GetTilesWithAssignedBins的第十一段代码如下所示:
// Bump up the priority if we determined it's NEVER_BIN on one tree,
// but is still required on the other tree.
bool is_in_never_bin_on_both_trees = tree_bin[ACTIVE_TREE] == NEVER_BIN &&
tree_bin[PENDING_TREE] == NEVER_BIN;
if (mts.bin == NEVER_BIN && !is_in_never_bin_on_both_trees)
mts.bin = tile_is_active ? AT_LAST_AND_ACTIVE_BIN : AT_LAST_BIN;这段代码检查分块的Active Managed Tile Bin和Pending Managed Tile Bin是否只有其中一个是等于NEVER_BIN。如果是的话,就将该分块最终的Managed Tile Bin提升为AT_LAST_AND_ACTIVE_BIN或者AT_LAST_BIN,取决于它当前是否是激活的。这意味着只有当分块的Active Managed Tile Bin和Pending Managed Tile Bin均为NEVER_BIN时,它最终的Managed Tile Bin才会被设置为NEVER_BIN。
TileManager类的成员函数GetTilesWithAssignedBins的第十二段代码如下所示:
// If the tile is in NEVER_BIN and it does not have an active task, then we
// can release the resources early. If it does have the task however, we
// should keep it in the prioritized tile set to ensure that AssignGpuMemory
// can visit it.
if (mts.bin == NEVER_BIN &&
!mts.tile_versions[mts.raster_mode].raster_task_) {
FreeResourcesForTileAndNotifyClientIfTileWasReadyToDraw(tile);
continue;
}这段代码检查分块最终是否被划分在NEVER_BIN中。如果是的话,并且它当前没有关联光栅化任务,那么就会调用TileManager类的成员函数FreeResourcesForTileAndNotifyClientIfTileWasReadyToDraw释放它所占用的纹理资源,因为被划分在NEVER_BIN在当前帧中是不需要的。
TileManager类的成员函数FreeResourcesForTileAndNotifyClientIfTileWasReadyToDraw最终会调用前面我们已经分析过的成员函数FreeResourceForTile来释放一个分块所占用的纹理资源。
TileManager类的成员函数GetTilesWithAssignedBins的最后一段代码如下所示:
// Insert the tile into a priority set.
tiles->InsertTile(tile, mts.bin);
}
}这段代码将分块保存在参数tiles指向的一个PrioritizedTileSet对象中。这是通过调用PrioritizedTileSet类的成员函数InsertTile实现的,如下所示:
void PrioritizedTileSet::InsertTile(Tile* tile, ManagedTileBin bin) {
tiles_[bin].push_back(tile);
bin_sorted_[bin] = false;
}这个函数定义在文件external/chromium_org/cc/resources/prioritized_tile_set.cc中。
PrioritizedTileSet类有两个成员变量tiles_和binsorted,它们的定义如下所示:
class CC_EXPORT PrioritizedTileSet {
......
private:
......
std::vector<Tile*> tiles_[NUM_BINS];
bool bin_sorted_[NUM_BINS];
};这个类定义在文件external/chromium_org/cc/resources/prioritized_tile_set.h中。
其中,成员变量tiles_是一个大小为NUM_BINS的std::vector数组。也就是说,对于每一个Managed Tile Bin,在PrioritizedTileSet类中都有一个std::vector。保存在同一个std::vector里面的分块都是属于同一个Managed Tile Bin的。
另外一个成员变量bin_sorted_是一个类型为bool的数组,它的大小也是等于NUM_BINS,用来表示成员变量tiles_描述的std::vector哪些是有序的,哪些是无序的。对于无序的std::vector,在遍历它的时候,要先进行排序。
理解了这两个成员变量的含义,回到PrioritizedTileSet类的成员函数InsertTile中,我们就可以很容易理解它的实现,它将参数tile描述的分块保存在参数bin描述的Managed Tile Bin对应的std::vector中,并且将该std::vector标记为无序的。
PrioritizedTileSet类提供了一个Iterator,通过该Iterator可以有序地遍历保存在成员变量tiles_描述的所有std::vector中的分块。遍历规则如下所示:
1. 先遍历优先级高的Manged Tile Bin的分块,再遍历优先级低的Manged Tile Bin的分块。
2. 对于NOW_AND_READY_TO_DRAW_BIN和NEVER_BIN中的分块,它们的遍历顺序是无关重要的。
3. 对于NOW_BIN、SOON_BIN、EVENTUALLY_AND_ACTIVE_BIN、EVENTUALLY_BIN、AT_LAST_AND_ACTIVE_BIN和AT_LAST_BIN中的分块,它们的遍历顺序与它们的优先级、分辨率和到当前帧的Viewport的距离有关。优先级越高、分辨率越高、到当前帧的Viewport的距离越小的分块,就越在前面被遍历。
这一步执行完成后,Tile Manager就对网页中的分块进行排序了,后面Tile Manager就会按照这个顺序对分块进行光栅化。回到TileManager类的成员函数ManageTiles中,它接下来就调用另外一个成员函数AssignGpuMemoryToTiles根据分块的排序和GPU内存限制决定哪些分块需要光栅化,哪些分块不需要光栅化。
TileManager类的成员函数AssignGpuMemoryToTiles的实现如下所示:
void TileManager::AssignGpuMemoryToTiles(
PrioritizedTileSet* tiles,
TileVector* tiles_that_need_to_be_rasterized) {
......
// Cast to prevent overflow.
int64 soft_bytes_available =
static_cast<int64>(bytes_releasable_) +
static_cast<int64>(global_state_.soft_memory_limit_in_bytes) -
static_cast<int64>(resource_pool_->acquired_memory_usage_bytes());
int64 hard_bytes_available =
static_cast<int64>(bytes_releasable_) +
static_cast<int64>(global_state_.hard_memory_limit_in_bytes) -
static_cast<int64>(resource_pool_->acquired_memory_usage_bytes());
int resources_available = resources_releasable_ +
global_state_.num_resources_limit -
resource_pool_->acquired_resource_count();
size_t soft_bytes_allocatable =
std::max(static_cast<int64>(0), soft_bytes_available);
size_t hard_bytes_allocatable =
std::max(static_cast<int64>(0), hard_bytes_available);
size_t resources_allocatable = std::max(0, resources_available);
......
size_t soft_bytes_left = soft_bytes_allocatable;
size_t hard_bytes_left = hard_bytes_allocatable;
size_t resources_left = resources_allocatable;
bool oomed_soft = false;
......
for (PrioritizedTileSet::Iterator it(tiles, true); it; ++it) {
Tile* tile = *it;
ManagedTileState& mts = tile->managed_state();
......
mts.raster_mode = tile->DetermineOverallRasterMode();
ManagedTileState::TileVersion& tile_version =
mts.tile_versions[mts.raster_mode];
// If this tile doesn't need a resource, then nothing to do.
if (!tile_version.requires_resource())
continue;
// If the tile is not needed, free it up.
if (mts.bin == NEVER_BIN) {
FreeResourcesForTileAndNotifyClientIfTileWasReadyToDraw(tile);
continue;
}
const bool tile_uses_hard_limit = mts.bin <= NOW_BIN;
const size_t bytes_if_allocated = BytesConsumedIfAllocated(tile);
const size_t tile_bytes_left =
(tile_uses_hard_limit) ? hard_bytes_left : soft_bytes_left;
......
size_t tile_bytes = 0;
size_t tile_resources = 0;
// It costs to maintain a resource.
for (int mode = 0; mode < NUM_RASTER_MODES; ++mode) {
if (mts.tile_versions[mode].resource_) {
tile_bytes += bytes_if_allocated;
tile_resources++;
}
}
// Allow lower priority tiles with initialized resources to keep
// their memory by only assigning memory to new raster tasks if
// they can be scheduled.
bool reached_scheduled_raster_tasks_limit =
tiles_that_need_to_be_rasterized->size() >= kScheduledRasterTasksLimit;
if (!reached_scheduled_raster_tasks_limit) {
// If we don't have the required version, and it's not in flight
// then we'll have to pay to create a new task.
if (!tile_version.resource_ && !tile_version.raster_task_) {
tile_bytes += bytes_if_allocated;
tile_resources++;
}
}
// Tile is OOM.
if (tile_bytes > tile_bytes_left || tile_resources > resources_left) {
......
FreeResourcesForTile(tile);
// This tile was already on screen and now its resources have been
// released. In order to prevent checkerboarding, set this tile as
// rasterize on demand immediately.
if (mts.visible_and_ready_to_draw)
tile_version.set_rasterize_on_demand();
......
oomed_soft = true;
......
} else {
resources_left -= tile_resources;
hard_bytes_left -= tile_bytes;
soft_bytes_left =
(soft_bytes_left > tile_bytes) ? soft_bytes_left - tile_bytes : 0;
if (tile_version.resource_)
continue;
}
......
// Tile shouldn't be rasterized if |tiles_that_need_to_be_rasterized|
// has reached it's limit or we've failed to assign gpu memory to this
// or any higher priority tile. Preventing tiles that fit into memory
// budget to be rasterized when higher priority tile is oom is
// important for two reasons:
// 1. Tile size should not impact raster priority.
// 2. Tiles with existing raster task could otherwise incorrectly
// be added as they are not affected by |bytes_allocatable|.
bool can_schedule_tile =
!oomed_soft && !reached_scheduled_raster_tasks_limit;
if (!can_schedule_tile) {
......
continue;
}
tiles_that_need_to_be_rasterized->push_back(tile);
}
......
}这个函数定义在文件external/chromium_org/cc/resources/tile_manager.cc中。
TileManager类的成员函数AssignGpuMemoryToTiles的实现也比较长,我们分段来阅读。
第一段代码如下所示:
void TileManager::AssignGpuMemoryToTiles(
PrioritizedTileSet* tiles,
TileVector* tiles_that_need_to_be_rasterized) {
......
// Cast to prevent overflow.
int64 soft_bytes_available =
static_cast<int64>(bytes_releasable_) +
static_cast<int64>(global_state_.soft_memory_limit_in_bytes) -
static_cast<int64>(resource_pool_->acquired_memory_usage_bytes());
int64 hard_bytes_available =
static_cast<int64>(bytes_releasable_) +
static_cast<int64>(global_state_.hard_memory_limit_in_bytes) -
static_cast<int64>(resource_pool_->acquired_memory_usage_bytes());
int resources_available = resources_releasable_ +
global_state_.num_resources_limit -
resource_pool_->acquired_resource_count();
size_t soft_bytes_allocatable =
std::max(static_cast<int64>(0), soft_bytes_available);
size_t hard_bytes_allocatable =
std::max(static_cast<int64>(0), hard_bytes_available);
size_t resources_allocatable = std::max(0, resources_available);
......
size_t soft_bytes_left = soft_bytes_allocatable;
size_t hard_bytes_left = hard_bytes_allocatable;
size_t resources_left = resources_allocatable;
bool oomed_soft = false;
bool oomed_hard = false;这段代码主是计算剩余可用的光栅化内存字节数以及光栅化资源个数。CC模块限制了光栅化内存字节数上限和光栅化资源个数(Num Resources Limit)。其中,光栅化内存字节数又分为软限制(Soft Memory Limit)和硬限制(Hard Memory Limit)两种,它们的作用如图2所示:
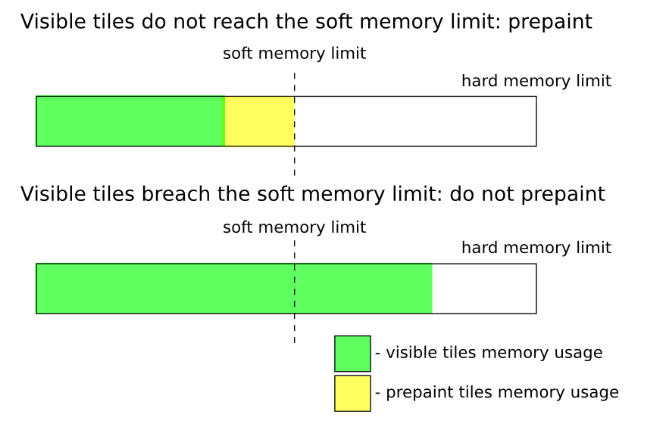
图2 Soft Memory Limit和Hard Memory Limit
当前可见的分块,也就是处于NOW_BIN中的分块,它们的可用的内存上限是Hard Memory Limit,其余的分块可用的内存上限是Soft Memory Limit。通过这种策略一方面可以最大程度保证可见分块都可以得到光栅化,另一方面又可以在可见分块占用内存不多的情况下,对其它的分块提前进行光栅化,这样等到它们变为可见时,就可以马上显示出来。
Soft Memory Limit、Hard Memory Limit和Num Resources Limit值分别保存在globalstate.soft_memory_limit_in_bytes、globalstate.hard_memory_limit_in_bytes和globalstate.num_resources_limit。其中,globalstate.num_resources_limit的值设置为10000000。
当网页使用硬件加速方式渲染时,globalstate.hard_memory_limit_in_bytes的值可以通过启动选项force-gpu-mem-available-mb指定,但是会被限制在16M到256M之间。当网页使用软件方式渲染时,globalstate.hard_memory_limit_in_bytes的值会被设置为128M。
在当前的实现中,globalstate.soft_memory_limit_in_bytes的值与globalstate.hard_memory_limit_in_bytes是相等的。
目前分块正在使用的光栅化内存字节数可以通过调用TileManager类的成员变量resource_pool_指向的一个ResourcePool对象的成员函数acquired_resource_count获得。另外,通过调用上述ResourcePool对象的成员函数acquired_resource_count可以获得当前正在使用的光栅化资源个数。
有了上述数据之后,本来就可以计算出剩余可用的光栅化内存字节数和光栅化资源个数。例如,剩余可用的Soft类型的光栅化内存字节数就等于(globalstate.soft_memory_limit_in_bytes - resourcepool->acquired_memory_usage_bytes())。不过我们看到,按照前面的方式计算出来的字节数,再加上TileManager类的成员变量bytes_releasable_的值,才是接下来使用的剩余可用的Soft类型的光栅化内存字节数soft_bytes_left。剩余可用的Hard类型的光栅化内存字节数hard_bytes_left和光栅化资源个数resources_left的计算过程也是类似的。
TileManager类的成员变量bytes_releasable_和resources_releasable_记录了当前可回收但是还没有回收的分块光栅化内存字节数和光栅化资源个数。注意,这里说的可回收资源,是指已经光栅化完成的分块占用的资源。当一个已经光栅化完成的分块不再需要时,它占用的资源就会被回收。将TileManager类的成员变量bytes_releasable_和resources_releasable_的值计入到剩余可用的光栅化内存字节数soft_bytes_left、hard_bytes_left和光栅化资源个数resources_left中去是冗余的。不过,接下来要遍历每一个分块时,会考虑剔除这些值。
TileManager类的成员函数AssignGpuMemoryToTiles的第二段代码的如下所示:
for (PrioritizedTileSet::Iterator it(tiles, true); it; ++it) {
Tile* tile = *it;
ManagedTileState& mts = tile->managed_state();
......
mts.raster_mode = tile->DetermineOverallRasterMode();
ManagedTileState::TileVersion& tile_version =
mts.tile_versions[mts.raster_mode];从这段代码开始,TileManager类的成员函数AssignGpuMemoryToTiles遍历保存在参数tile中的所有分块,检查是否需要给这些分块分配光栅化内存。给分块分配光栅化内存需要遵循前面提到的三个限制。
这段代码首先确定分块的光栅化模式,这是通过调用Tile类的成员函数DetermineOverallRasterMode实现的,如下所示:
RasterMode Tile::DetermineOverallRasterMode() const {
return DetermineRasterModeForResolution(managed_state_.resolution);
}这个函数定义在文件external/chromium_org/cc/resources/tile.cc中。
Tile类的成员函数DetermineOverallRasterMode又是通过调用另外一个成员函数DetermineRasterModeForResolution确定分块的光栅化模式的,如下所示:
RasterMode Tile::DetermineRasterModeForResolution(
TileResolution resolution) const {
RasterMode current_mode = managed_state_.raster_mode;
RasterMode raster_mode = resolution == LOW_RESOLUTION
? LOW_QUALITY_RASTER_MODE
: HIGH_QUALITY_RASTER_MODE;
return std::min(raster_mode, current_mode);
}这个函数定义在文件external/chromium_org/cc/resources/tile.cc中。
Tile类的成员变量managed_state_指向的一个ManagedTileState对象的成员变量raster_mode记录了分块当前被设置的光栅化模式。从前面的调用过程可以知道,参数resolution描述的是分块当前被设置的分辨率模式。
Tile类的成员函数DetermineRasterModeForResolution综合考虑分块当前设置的光栅化模式和分辨率模式,确定它最终要使用的光栅化模式:
1. 如果分块当前设置的光栅化模式是HIGH_QUALITY_RASTER_MODE,那么分块就按照HIGH_QUALITY_RASTER_MODE模式进行光栅化。
- 如果分块当前设置的光栅化模式是LOW_QUALITY_RASTER_MODE,但是分块当前设置的分辨率模式是HIGH_RESOLUTION,那么分块也按照HIGH_QUALITY_RASTER_MODE模式进行光栅化。
3. 其作情况分块按照LOW_QUALITY_RASTER_MODE模式进行光栅化。
回到TileManager类的成员函数AssignGpuMemoryToTiles中,确定了分块的光栅化模式之后,通过其内部的一个ManagedTileState对象的成员变量tile_versions就可以获得一个TileVersion对象。这个TileVersion对象就描述了分块当前执行光栅化所需要的信息。
TileManager类的成员函数AssignGpuMemoryToTiles的第三段代码的如下所示:
// If this tile doesn't need a resource, then nothing to do.
if (!tile_version.requires_resource())
continue;
// If the tile is not needed, free it up.
if (mts.bin == NEVER_BIN) {
FreeResourcesForTileAndNotifyClientIfTileWasReadyToDraw(tile);
continue;
}这段代码首先检查分块是否需要纹理资源进行光栅化操作。前面我们提到,如果一个分块的光栅化结果是一个单一颜色,那么是不必要给它分配一个纹理资源的,只要记录下它的颜色值就可以了。当然,这个颜色是经过分析才得出的。后面我们分析分块的光栅化过程时就可以看到这一点。
这段代码接下来检查分块是否被划分在NEVER_BIN中。如果是的话,那么就说明这个分块在当前帧是不需要进行渲染的。这时候需要回收它曾经占用的资源。这是通过调用TileManager类的成员函数FreeResourcesForTileAndNotifyClientIfTileWasReadyToDraw实现的。回收过程可以参考前面分析的TileManager类的成员函数FreeResourceForTile。
TileManager类的成员函数AssignGpuMemoryToTiles的第四段代码的如下所示:
const bool tile_uses_hard_limit = mts.bin <= NOW_BIN;
const size_t bytes_if_allocated = BytesConsumedIfAllocated(tile);
const size_t tile_bytes_left =
(tile_uses_hard_limit) ? hard_bytes_left : soft_bytes_left;
......
size_t tile_bytes = 0;
size_t tile_resources = 0;
// It costs to maintain a resource.
for (int mode = 0; mode < NUM_RASTER_MODES; ++mode) {
if (mts.tile_versions[mode].resource_) {
tile_bytes += bytes_if_allocated;
tile_resources++;
}
}
// Allow lower priority tiles with initialized resources to keep
// their memory by only assigning memory to new raster tasks if
// they can be scheduled.
bool reached_scheduled_raster_tasks_limit =
tiles_that_need_to_be_rasterized->size() >= kScheduledRasterTasksLimit;
if (!reached_scheduled_raster_tasks_limit) {
// If we don't have the required version, and it's not in flight
// then we'll have to pay to create a new task.
if (!tile_version.resource_ && !tile_version.raster_task_) {
tile_bytes += bytes_if_allocated;
tile_resources++;
}
}这段代码主要做两件事情。第一件事情是检查当前要使用的资源限制类型,也就是要使用Soft Memory Limit还是Hard Memory Limit来限制当前遍历的分块的资源分配。从前面的分析可以知道,如果一个分块在当前帧是可见的,那么使用的内存限制是Hard Memory Limit;否则就使用Soft Memory Limit。当一个分块被划分在NOW_AND_READY_TO_DRAW_BIN和NOW_BIN时,它就可是可见的。当前遍历的分块被划分在的Bin记录在mts.bin中,如果它的值小于等于NOW_BIN,就说明该分块要么被划分在NOW_AND_READY_TO_DRAW_BIN中,要么被划分在NOW_BIN中,因为前者的值等于0,后者的值等于1。在这种情况下,当前要使用的资源限制类型就是Hard Memory Limit。这时候剩余可用的光栅化内存字节数tile_bytes_left就等于前面计算出来的hard_bytes_left。另一方面,如果当前遍历的分块在当前帧是不可见的,那么剩余可用的光栅化内存字节数tile_bytes_left就等于前面计算出来的soft_bytes_left。
第二件事情是计算当前遍历的分块所要消耗的光栅化内存字节数tile_bytes和光栅化资源个数tile_resources。一个分块有着不同的光栅化版本,每一个版本需要的光栅化内存字节数都是相同的。这是因为每一个版本光栅化所需要的光栅化内存字节数只与两个因素相关。第一个因素是分块的大小。第二个因素是资源格式。对于同一个分块的不同版本来说,这两个因素都是相同的。通过调用TileManager类的成员函数BytesConsumedIfAllocated可以获得为一个分块的一个光栅化版本分配纹理资源所需要耗的光栅化内存字节数bytes_if_allocated。
一个分块所要消耗的光栅化内存字节数tile_bytes和光栅化资源个数tile_resources由两部分组成。一部分是已经光栅化的版本所占用的内存字节数和资源个数,另一部分是即将要光栅化的版本所占用的内存字节数和资源个数。
这段代码中间的for循环计算的是分块已经光栅化的版本所占用的内存字节数和资源个数。之所以要计算这部分内存字节数和资源个数,是因为tile_bytes和tile_resources的值接下来是用来与前面计算出来的tile_bytes_left和resources_left比较的。前面提到,tile_bytes_left和resources_left包含的信息冗余的,它不仅包含了当前剩余未使用的光栅化内存字节数和资源个数,还包含那些已经完成了光栅化的分块所占用的内存字节数和资源个数。
这段代码最后计算分块即将要光栅化的版本所占用的内存字节数和资源个数。计算这部分光栅化内存字节数和资源个数有一个限制条件,就是在当前帧中执行的光栅化任务个数不要超过阀值kScheduledRasterTasksLimit。输出参数tiles_that_need_to_be_rasterized描述的Vector的当前大小表示的就是当前已经计算出来的要执行的光栅化任务个数。在满足上述限制条件的情况下,这段代码接下来又检查分块即将要光栅化的版本是否还没有分配资源,以及还没有关联光栅化任务。如果是的话,那就需要为它分配光栅化资源,也就是将它所要占用的光栅化内存字节数和资源个数计入tile_bytes和tile_resources中去。
当一个分块的一个光栅化版本(Tile Version)的成员变量resource_的值等于NULL时,就表示还没有为它分配过光栅化资源。当它的另外一个成员变量raster_task_的值也等于NULL时,就表示也没有为它分配过光栅化任务。这里有一点需要注意,当一个分块的一个光栅化版本关联有光栅化任务时,就已经为它分配过光栅化资源了,只不过这个光栅化资源还没有保存到它的成员变量resource_中去。等到光栅化操作完成的时候,已经分配的光栅化资源才会保存到它的成员变量resource_中去。因此,前面在判断是否要为分块即将光栅化的版本分配资源时,要同时判断它的成员变量resource_和raster_task_是否都等于NULL。
TileManager类的成员函数AssignGpuMemoryToTiles的第五段代码的如下所示:
// Tile is OOM.
if (tile_bytes > tile_bytes_left || tile_resources > resources_left) {
.....
FreeResourcesForTile(tile);
// This tile was already on screen and now its resources have been
// released. In order to prevent checkerboarding, set this tile as
// rasterize on demand immediately.
if (mts.visible_and_ready_to_draw)
tile_version.set_rasterize_on_demand();
......
oomed_soft = true;
......
} else {
resources_left -= tile_resources;
hard_bytes_left -= tile_bytes;
soft_bytes_left =
(soft_bytes_left > tile_bytes) ? soft_bytes_left - tile_bytes : 0;
if (tile_version.resource_)
continue;
}这段代码检查一个分块所占用的光栅化内存字节数和资源个数是否会超出了限制,也就是超出当前可用的光栅化内存字节数tile_bytes_left和资源个数resources_left。如果超出,那么就会触发OOM异常。
在OOM的情况下,这段代码会做三件事情:
1. 调用TileManager类的成员函数FreeResourcesForTile释放当前遍历的分块之前所占用的资源。
2. 检查当前遍历的分块是否是已经在屏幕上显示的。如果是的话,那么就将它标记为Raster On Demand,这是因为它所占用的资源被释放了。当一个正在屏幕上显示的分块所占用的资源被释放时,它在屏幕上对应的位置将会以Checkboard方式显示。为了避免使用Checkboard方式显示一个已经被释放资源的分块,这段代码会将该分块的光栅化模式设置为PICTURE_PILE_MODE,也就是将它标记为Raster On Demand。这种类型的分块在渲染之前,将会重新在另外一个共享的资源上进行光栅化。也就是这种类型的分块没有独立的纹理资源。
3. 将本地变量omoed_soft的值设置为true,表示发生了OOM。
另一方面,如果没有发生OOM,就将当前遍历的分块所占用的光栅化内存字节数tile_bytes和资源个数tile_resources分别从hard_bytes_left、soft_bytes_left和resources_left中减少,以更新当前可用的光栅化内存字节数和资源个数。
在没有发生OOM的情况下,这段代码还做的另外一件事情是判断是否已经为当前遍历的分块即将要光栅化的版本tile_version的成员变量resource_的值是否不等于NULL。前面提到,如果一个分块的某一个光栅化版本的成员变量resource_的值不等于NULL,那么就表示该光栅化版本已经执行过光栅化任务了,也就是光栅化操作已经完成。在这种情况下,就不需要再继续往前执行下去了,因为接下来的代码,也就是TileManager类的成员函数AssignGpuMemoryToTiles的最后一段代码,是与创建光栅化任务相关的,如下所示:
// Tile shouldn't be rasterized if |tiles_that_need_to_be_rasterized|
// has reached it's limit or we've failed to assign gpu memory to this
// or any higher priority tile. Preventing tiles that fit into memory
// budget to be rasterized when higher priority tile is oom is
// important for two reasons:
// 1. Tile size should not impact raster priority.
// 2. Tiles with existing raster task could otherwise incorrectly
// be added as they are not affected by |bytes_allocatable|.
bool can_schedule_tile =
!oomed_soft && !reached_scheduled_raster_tasks_limit;
if (!can_schedule_tile) {
......
continue;
}
tiles_that_need_to_be_rasterized->push_back(tile);
}
......
}这段代码判断是否可以对当前遍历的分块进行光栅化。如果可以的话,那么就将它保存在输出参数tiles_that_need_to_be_rasterized描述的一个Vector中。
当前遍历的分块进行可以进行光栅化需要同时满足两个条件:
1. 对它进行光栅化不会触发OOM,也就是给它分配光栅化资源之后不会超出预设的资源限制,也就是GPU内存限制。
2. 当前帧要执行的光栅化任务个数没有超出限制,也就是前面所提到的kScheduledRasterTasksLimit,这个值定义为32。
这一步执行完成后,Tile Manager就根据分块的优先级排序和GPU内存限制选择出了当前需要进行光栅化操作的分块。回到TileManager类的成员函数ManageTiles中,它接下来就调用另外一个成员函数ScheduleTasks对前面选择出来的分块执行光栅化操作。
TileManager类的成员函数ScheduleTasks的实现如下所示:
void TileManager::ScheduleTasks(
const TileVector& tiles_that_need_to_be_rasterized) {
......
raster_queue_.Reset();
// Build a new task queue containing all task currently needed. Tasks
// are added in order of priority, highest priority task first.
for (TileVector::const_iterator it = tiles_that_need_to_be_rasterized.begin();
it != tiles_that_need_to_be_rasterized.end();
++it) {
Tile* tile = *it;
ManagedTileState& mts = tile->managed_state();
ManagedTileState::TileVersion& tile_version =
mts.tile_versions[mts.raster_mode];
......
if (!tile_version.raster_task_)
tile_version.raster_task_ = CreateRasterTask(tile);
raster_queue_.items.push_back(RasterTaskQueue::Item(
tile_version.raster_task_.get(), tile->required_for_activation()));
raster_queue_.required_for_activation_count +=
tile->required_for_activation();
}
......
rasterizer_->ScheduleTasks(&raster_queue_);
......
}这个函数定义在文件external/chromium_org/cc/resources/tile_manager.cc中。
从前面的分析可以知道,保存在参数tiles_that_need_to_be_rasterized描述的Vector中的分块就是当前需要执行光栅化操作的分块,并且这些分块已经是按照优先级从高到低的顺序进行排序的。
TileManager类的成员函数ScheduleTasks依次遍历这些分块,并且检查它们是否关联了光栅化任务。如果还没有关联,那么就会调用TileManager类的另外一个成员函数CreateRasterTask创建一个光栅化任务,并且与对应的分块进行关联。
TileManager类的成员函数CreateRasterTask创建出来的光栅化任务通过一个RasterTaskImpl对象描述。这个RasterTaskImpl对象封装成一个RasterTaskQueue::Item对象中保存在TileManager类的成员变量raster_queue_描述的一个队列中,这个队列最终交给另外一个成员变量rasterizer_描述的一个Rasterizer对象的成员函数ScheduleTasks进行处理,也就是执行队列中的光栅化任务。
我们注意到,TileManager类的成员函数ScheduleTasks在遍历需要执行光栅化操作的分块的过程中,还会调用这些分块的成员函数required_for_activation,用来检查它们是否设置了Require For Activation标记。如果设置了,那么TileManager类的成员变量raster_queue_指向的一个RasterTaskQueue对象的成员变量required_for_activation_count的值就会增加1,用来表示TileManager类的成员变量raster_queue_描述的队列中有多少个光栅化任务在执行完成之后就需要将CC Pending Layer Tree激活为CC Active Layer Tree的。
接下来,我们首先分析TileManager类的成员函数CreateRasterTask创建光栅化任务的过程,接下来再分析TileManager类的成员变量rasterizer_指向的一个Rasterizer对象的成员函数ScheduleTasks执行光栅化操作的过程。
TileManager类的成员函数CreateRasterTask的实现如下所示:
scoped_refptr<RasterTask> TileManager::CreateRasterTask(Tile* tile) {
ManagedTileState& mts = tile->managed_state();
scoped_ptr<ScopedResource> resource =
resource_pool_->AcquireResource(tile->tile_size_.size());
const ScopedResource* const_resource = resource.get();
// Create and queue all image decode tasks that this tile depends on.
ImageDecodeTask::Vector decode_tasks;
PixelRefTaskMap& existing_pixel_refs = image_decode_tasks_[tile->layer_id()];
for (PicturePileImpl::PixelRefIterator iter(
tile->content_rect(), tile->contents_scale(), tile->picture_pile());
iter;
++iter) {
SkPixelRef* pixel_ref = *iter;
uint32_t id = pixel_ref->getGenerationID();
// Append existing image decode task if available.
PixelRefTaskMap::iterator decode_task_it = existing_pixel_refs.find(id);
if (decode_task_it != existing_pixel_refs.end()) {
decode_tasks.push_back(decode_task_it->second);
continue;
}
// Create and append new image decode task for this pixel ref.
scoped_refptr<ImageDecodeTask> decode_task =
CreateImageDecodeTask(tile, pixel_ref);
decode_tasks.push_back(decode_task);
existing_pixel_refs[id] = decode_task;
}
return make_scoped_refptr(
new RasterTaskImpl(const_resource,
tile->picture_pile(),
tile->content_rect(),
tile->contents_scale(),
mts.raster_mode,
mts.resolution,
tile->layer_id(),
static_cast<const void*>(tile),
tile->source_frame_number(),
tile->use_picture_analysis(),
rendering_stats_instrumentation_,
base::Bind(&TileManager::OnRasterTaskCompleted,
base::Unretained(this),
tile->id(),
base::Passed(&resource),
mts.raster_mode),
&decode_tasks));
}这个函数定义在文件external/chromium_org/cc/resources/tile_manager.cc中。
TileManager类的成员函数CreateRasterTask首先是调用成员变量resource_pool_描述的一个ResourcePool对象的成员函数AcquireResource为参数tile描述的分块创建纹理资源。
TileManager类的成员函数CreateRasterTask接下来又检查这个分块是否依赖了其它的图片资源。如果是的话,就会调用TileManager类的成员函数CreateImageDecodeTask为每一个依赖的图片都创建一个解码任务。每一个解码任务都是通过一个ImageDecodeTaskImpl对象描述的。
TileManager类的成员函数CreateRasterTask最后将前面创建的纹理资源、参数tile描述的分块的信息,以及前面创建的图片解码任务,封装在一个RasterTaskImpl对象中,并且返回给调用者。
这个RasterTaskImpl对象描述的就是一个光栅化任务,它负责对参数tile描述的分块进行光栅化。光栅化的结果就保存在前面创建的纹理资源中。注意,如果参数tile描述的分块依赖了其它的图片资源,那么上述光栅化任务就在会被依赖的图片的解码任务执行完成之后才会执行。
这个RasterTaskImpl对象描述的光栅化任务还绑定了TileManager类的成员函数OnRasterTaskCompleted,表示当光栅化任务执行完成后,调用TileManager类的成员函数OnRasterTaskCompleted进行后续处理。
光栅化任务的创建过程,也就是RasterTaskImpl类的构造函数的实现,如下所示:
class RasterTaskImpl : public RasterTask {
public:
RasterTaskImpl(
const Resource* resource,
PicturePileImpl* picture_pile,
const gfx::Rect& content_rect,
float contents_scale,
RasterMode raster_mode,
TileResolution tile_resolution,
int layer_id,
const void* tile_id,
int source_frame_number,
bool analyze_picture,
RenderingStatsInstrumentation* rendering_stats,
const base::Callback<void(const PicturePileImpl::Analysis&, bool)>& reply,
ImageDecodeTask::Vector* dependencies)
: RasterTask(resource, dependencies),
picture_pile_(picture_pile),
...... {}
......
};这个函数定义在文件external/chromium_org/cc/resources/tile_manager.cc中。
RasterTaskImpl类的构造函数主要是将传递给它的参数保存在相应的成员变量中。其中,最重要的参数是picture_pile指向的一个PicturePileImpl对象。这个PicturePileImpl是要执行光栅化操作的分块中获得的,也就是通过调用Tile类的成员函数picture_pile获得的,如下所示:
class CC_EXPORT Tile : public RefCountedManaged<Tile> {
public:
......
PicturePileImpl* picture_pile() {
return picture_pile_.get();
}
......
private:
.....
scoped_refptr<PicturePileImpl> picture_pile_;
......
};这个函数定义在文件external/chromium_org/cc/resources/tile.h中。
Tile类的成员函数picture_pile返回的是成员变量picture_pile_指向的一个PictruePileImpl对象。
Tile类的成员变量picture_pile_是什么时候设置的呢?从前面Chromium网页Layer Tree同步为Pending Layer Tree的过程分析一文可以知道,Tile Manager在创建一个分块的时候,都会指定一个PicturePileImpl对象,如下所示:
Tile::Tile(TileManager* tile_manager,
PicturePileImpl* picture_pile,
const gfx::Size& tile_size,
const gfx::Rect& content_rect,
const gfx::Rect& opaque_rect,
float contents_scale,
int layer_id,
int source_frame_number,
int flags)
: ...... {
set_picture_pile(picture_pile);
}这个函数定义在文件external/chromium_org/cc/resources/tile.cc中。
参数picture_pile描述的就是指定的PicturePileImpl对象,这个PicturePileImpl对象通过Tile类的成员函数set_picture_pile保存在成员变量picture_pile_中,如下所示:
class CC_EXPORT Tile : public RefCountedManaged<Tile> {
public:
......
void set_picture_pile(scoped_refptr<PicturePileImpl> pile) {
......
picture_pile_ = pile;
}
......
};这个函数定义在文件external/chromium_org/cc/resources/tile.h中。
从前面Chromium网页Layer Tree同步为Pending Layer Tree的过程分析一文可以知道,这个PicturePileImpl对象实际上来自于PictureLayerImpl类的成员变量pile_。PictureLayerImpl类描述的是CC Pending Layer Tree中的Layer,它的成员变量pile_指向的PicturePileImpl对象是在将CC Layer Tree同步为CC Pending Layer Tree的过程中创建的,并且是根据CC Layer Tree中的Picture Layer的成员变量pile_创建的。
PictureLayer类的成员变量pile_指向的是一个PicturePile对象。从前面Chromium网页Layer Tree绘制过程分析一文又可以知道,这个PicturePile对象记录了CC Layer Tree中的Layer的绘制命令。相应地,根据它创建的PicturePileImpl对象也获得了它所记录的绘制命令。这些绘制命令将会在分块的光栅化过程中得到执行。
回到TileManager类的成员函数ScheduleTasks中,当它为要执行光栅化操作的分块都关联上光栅化任务之后,它就会调用成员变量rasterizer_指向的一个Rasterizer对象的成员函数ScheduleTasks执行光栅化任务。从前面Chromium网页绘图表面(Output Surface)创建过程分析一文可以知道,取决于所使用的光栅化方式,TileManager类的成员变量rasterizer_指向的是不同类型的Rasterizer对象。具体来说,就是:
1. GPU光栅化:TileManager类的成员变量rasterizer_指向的Rasterizer对象的实际类型是DirectRasterWorkerPool。
2. Zero Copy CPU光栅化:TileManager类的成员变量rasterizer_指向的Rasterizer对象的实际类型是ImageRasterWorkerPool。
3. One Copy CPU光栅化:TileManager类的成员变量rasterizer_指向的Rasterizer对象的实际类型是ImageCopyRasterWorkerPool。
4. Pixel Buffer CPU光栅化:TileManager类的成员变量rasterizer_指向的Rasterizer对象的实际类型是PixelBufferRasterWorkerPool。
我们假设Tile Manager使用GPU光栅化方式,也就是TileManager类的成员变量rasterizer_指向的实际上一个DirectRasterWorkerPool对象。这意味着接下来DirectRasterWorkerPool类的成员函数ScheduleTasks会被调用执行光栅化操作。其余情况的光栅化操作过程是类似,主要的区别在于执行光栅化操作所使用的Canvas是不一样的,以及执行光栅化操作所使用的线程也是不一样的。这一点我们在接下来的两篇文章中再详细进行分析。
为了更好地理解GPU光栅化的过程,我们先分析TileManager类的成员变量rasterizer_指向的DirectRasterWorkerPool对象的创建过程。从前面Chromium网页绘图表面(Output Surface)创建过程分析一文可以知道,这个DirectRasterWorkerPool对象是在LayerTreeHostImpl类的成员函数CreateAndSetTileManager中创建的,如下所示:
void LayerTreeHostImpl::CreateAndSetTileManager() {
.....
if (use_gpu_rasterization_ && context_provider) {
......
raster_worker_pool_ =
DirectRasterWorkerPool::Create(proxy_->ImplThreadTaskRunner(),
resource_provider_.get(),
context_provider);
......
}
......
tile_manager_ =
TileManager::Create(this,
proxy_->ImplThreadTaskRunner(),
resource_pool_.get(),
raster_worker_pool_->AsRasterizer(),
rendering_stats_instrumentation_);
......
}这个函数定义在文件external/chromium_org/cc/trees/layer_tree_host_impl.cc中。
从这里可以看到,TileManager类的成员变量rasterizer_指向的DirectRasterWorkerPool对象是通过调用DirectRasterWorkerPool的静态成员函数Create创建的,如下所示:
scoped_ptr<RasterWorkerPool> DirectRasterWorkerPool::Create(
base::SequencedTaskRunner* task_runner,
ResourceProvider* resource_provider,
ContextProvider* context_provider) {
return make_scoped_ptr<RasterWorkerPool>(new DirectRasterWorkerPool(
task_runner, resource_provider, context_provider));
}这个函数定义在文件external/chromium_org/cc/resources/direct_raster_worker_pool.cc中。
DirectRasterWorkerPool的静态成员函数Create创建了一个DirectRasterWorkerPool对象,并且返回给调用者。这个DirectRasterWorkerPool对象的创建过程,也就是DirectRasterWorkerPool类的构造函数的实现,如下所示:
DirectRasterWorkerPool::DirectRasterWorkerPool(
base::SequencedTaskRunner* task_runner,
ResourceProvider* resource_provider,
ContextProvider* context_provider)
: task_runner_(task_runner),
task_graph_runner_(new TaskGraphRunner),
...... {}这个函数定义在文件external/chromium_org/cc/resources/direct_raster_worker_pool.cc中。
从前面的调用过程可以知道,参数task_runner指向的一个SequencedTaskRunner对象描述的实际上是CC模块的Compositor线程的消息队列。这个SequencedTaskRunner对象保存在DirectRasterWorkerPool类的成员变量task_runner_中。以后DirectRasterWorkerPool类将会通过这个SequencedTaskRunner对象请求CC模块的Compositor线程对网页中的分块执行光栅化操作。
DirectRasterWorkerPool类的构造函数还会创建一个TaskGraphRunner对象,并且保存在成员变量task_graph_runner_中。这个TaskGraphRunner对象负责对接下来创建的光栅化任务按照优先级从高到低的顺序进行排序。
理解了TileManager类的成员变量rasterizer_指向的DirectRasterWorkerPool对象的创建过程之后,接下来我们分析它的成员函数ScheduleTasks的实现,以便了解分块的光栅化过程,如下所示:
void DirectRasterWorkerPool::ScheduleTasks(RasterTaskQueue* queue) {
......
unsigned priority = kRasterTaskPriorityBase;
......
scoped_refptr<RasterizerTask>
new_raster_required_for_activation_finished_task(
CreateRasterRequiredForActivationFinishedTask(
queue->required_for_activation_count,
task_runner_.get(),
base::Bind(&DirectRasterWorkerPool::
OnRasterRequiredForActivationFinished,
raster_finished_weak_ptr_factory_.GetWeakPtr())));
scoped_refptr<RasterizerTask> new_raster_finished_task(
CreateRasterFinishedTask(
task_runner_.get(),
base::Bind(&DirectRasterWorkerPool::OnRasterFinished,
raster_finished_weak_ptr_factory_.GetWeakPtr())));
for (RasterTaskQueue::Item::Vector::const_iterator it = queue->items.begin();
it != queue->items.end();
++it) {
const RasterTaskQueue::Item& item = *it;
RasterTask* task = item.task;
......
if (item.required_for_activation) {
graph_.edges.push_back(TaskGraph::Edge(
task, new_raster_required_for_activation_finished_task.get()));
}
InsertNodesForRasterTask(&graph_, task, task->dependencies(), priority++);
graph_.edges.push_back(
TaskGraph::Edge(task, new_raster_finished_task.get()));
}
InsertNodeForTask(&graph_,
new_raster_required_for_activation_finished_task.get(),
kRasterRequiredForActivationFinishedTaskPriority,
queue->required_for_activation_count);
InsertNodeForTask(&graph_,
new_raster_finished_task.get(),
kRasterFinishedTaskPriority,
queue->items.size());
ScheduleTasksOnOriginThread(this, &graph_);
task_graph_runner_->ScheduleTasks(namespace_token_, &graph_);
ScheduleRunTasksOnOriginThread();
raster_finished_task_ = new_raster_finished_task;
raster_required_for_activation_finished_task_ =
new_raster_required_for_activation_finished_task;
}这个函数定义在文件external/chromium_org/cc/resources/direct_raster_worker_pool.cc中。
从前面的调用过程可以知道,参数queue描述的队列保存一系列的光栅化任务,并且这些光栅化是按照优先级从高到低的顺序排序的。DirectRasterWorkerPool类的成员函数ScheduleTasks首先是根据这些光栅化任务创建一个Task Graph。这个Task Graph由DirectRasterWorkerPool类的成员变量graph_指向的一个TaskGraph对象描述。
DirectRasterWorkerPool类的成员函数ScheduleTasks接下来调用从父类RasterWorkerPool继承下来的成员函数ScheduleTasksOnOriginThread为保存在参数queue中的每一个光栅化任务创建一个Canvas。这些Canvas在后面执行光栅化操作时将会使用到。
DirectRasterWorkerPool类的成员函数ScheduleTasks接下来又调用成员变量task_graph_runner_指向的一个TaskGraphRunner对象的成员函数ScheduleTasks对前面创建的Task Graph中的Task进行排序。经过排序之后,可执行的、优先级最高的Task就排在最前面等待执行。
DirectRasterWorkerPool类的成员函数ScheduleTasks最后又调用了另外一个成员函数ScheduleRunTasksOnOriginThread,后者将会在CC模块的Compositor线程中执行前面已经排序完成的Task。
在继续分析RasterWorkerPool类的成员函数ScheduleTasksOnOriginThread、TaskGraphRunner类的成员函数ScheduleTasks和DirectRasterWorkerPool类的成员函数ScheduleRunTasksOnOriginThread的实现之前,我们先分析Task Graph的实现原理。
每一个Task Graph都关联有一个Namespace。DirectRasterWorkerPool类的成员变量graph_描述的Task Graph关联的Namespace由另外一个成员变量namespace_token_描述。TaskGraphRunner类的成员函数ScheduleTasks在执行一个Task Graph的光栅化任务的时候,需要指定这些光栅化任务所属的Namesapce。
我们注意到,DirectRasterWorkerPool类的成员变量graph_描述的Task Graph除了包含保存在参数queue中的光栅化任务之外,还包含两个特殊的Task。
一个称为Raster Required For Activation Finished Task。这个Task通过一个RasterRequiredForActivationFinishedTaskImpl对象描述,保存DirectRasterWorkerPool类的成员变量raster_required_for_activation_finished_task_中,绑定了DirectRasterWorkerPool类的成员函数OnRasterRequiredForActivationFinished。当所有标记为Required For Activation的分块执行完成光栅化操作之后,这个Task就会被执行,也就是DirectRasterWorkerPool类的成员函数OnRasterRequiredForActivationFinished会被调用,用来再次CC Pending Layer Tree激活为CC Active Layer Tree。
另一个称为Raster Finished Task。这个Task通过一个RasterFinishedTaskImpl对象描述,保存在DirectRasterWorkerPool类的成员变量raster_finished_task_中,它绑定了DirectRasterWorkerPool类的成员函数OnRasterFinished。当所有的分块都光栅化完成后,这个Task就被执行,也就是DirectRasterWorkerPool类的成员函数OnRasterFinished会被调用,用来检查是否需要将CC Pending Layer Tree激活为CC Active Layer Tree。
Task Graph中的每一个Task都关联有一个Priority值。这些Priority值描述的就是Task的优先级。优先级越高的Task,它的Priority值就小,就越先执行。
一个Task Graph主要存在五种类型的Task:
1. OnDemandRasterTaskImpl:Priority值为0。
-
RasterRequiredForActivationFinishedTaskImpl:Priority值为1。
-
RasterFinishedTaskImpl:Priority值为2。
4. RasterRaskImpl:Priority值大于等于3。
5. ImageDecodeTaskImpl:Priority值大于等于3。
后面四种类型的Task的作用我们已经介绍过了。类型为OnDemandRasterTaskImpl的Task是用来对那些被标记为Rasterize On Demand的分块进行光栅化操作的。这些分块由于当前使用的光栅化内存超出了GPU内存上限而不能分配到独立到的纹理资源,但是这些分块又是在当前帧中需要显示的,因此就是需要使用预留的一个共享纹理资源来对它们执行光栅化操作,并且这些光栅化操作的优先级别最高。
Task Graph中的Task可能会存在依赖关系,这些依赖关系发生在RasterRequiredForActivationFinishedTaskImpl与RasterRaskImpl之间、RasterFinishedTaskImpl与RasterRaskImpl之间,以及RasterRaskImpl与ImageDecodeTaskImpl之间。因此,TaskGraphRunner类的成员函数ScheduleTasks在执行一个Task Graph中的Task的时候,必须要保证被依赖的Task先执行。
总结来说,Task Graph中的Task在执行的时候,需要做到以下两点:
1. 优先级高的Task先于优先级低的Task执行。
2. 被依赖的Task先于依赖的Task执行。
为了做到以上两点,Task Graph按照以下方式组织它里面的Task,如图3所示:
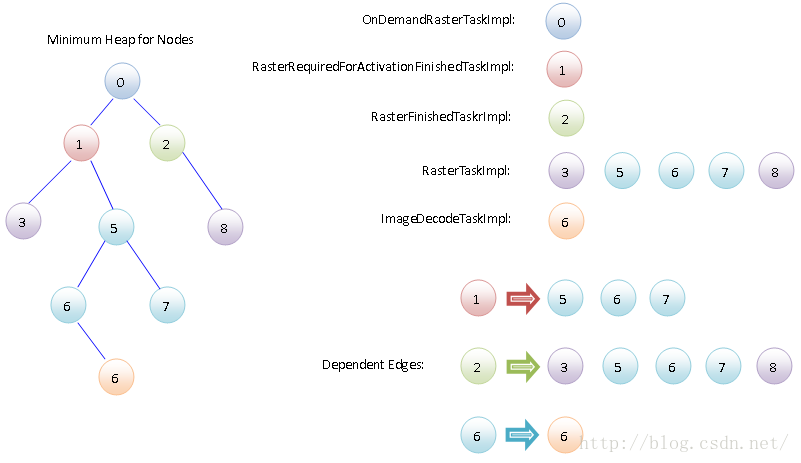
图3 Task Graph
Task Graph根据Task的Priority值将它们组织成一个Minimum Heap,并且记录了Task之间的依赖关系。每一个依赖关系都用一个Edge描述。在图3中,Task 1依赖了Task 5、6、7,Task 2依赖了Task 3、5、6、7、8,Task 6依赖了另外一个不同类型的Task 6。
根据这些信息,TaskGraphRunner类的成员函数ScheduleTasks执行图3所示的Task Graph的Task的顺序依次为:0、5、6(ImageDecodeTaskImpl)、6(RasterTaskImpl)、7、1、3、8、2。
通过前面的知识,读者可以自已进一步分析DirectRasterWorkerPool类的成员函数ScheduleTasks。接下来我们继续分析RasterWorkerPool类的成员函数ScheduleTasksOnOriginThread、TaskGraphRunner类的成员函数ScheduleTasks和DirectRasterWorkerPool类的成员函数ScheduleRunTasksOnOriginThread的实现,以便进一步了解分块的光栅化过程。
RasterWorkerPool类的成员函数ScheduleTasksOnOriginThread用来为分块创建Canvas,为后面的光栅化操作作准备,它的实现如下所示:
void RasterWorkerPool::ScheduleTasksOnOriginThread(RasterizerTaskClient* client,
TaskGraph* graph) {
TRACE_EVENT0("cc", "Rasterizer::ScheduleTasksOnOriginThread");
for (TaskGraph::Node::Vector::iterator it = graph->nodes.begin();
it != graph->nodes.end();
++it) {
TaskGraph::Node& node = *it;
RasterizerTask* task = static_cast<RasterizerTask*>(node.task);
if (!task->HasBeenScheduled()) {
......
task->ScheduleOnOriginThread(client);
......
}
}
}这个函数定义在文件external/chromium_org/cc/resources/raster_worker_pool.cc中。
RasterWorkerPool类的成员函数ScheduleTasksOnOriginThread遍历参数graph描述的Task Graph中的每一个Task,并且检查它们是否已经被执行。如果还没有执行,就会调用它们的成员函数ScheduleOnOriginThread,以便它们在执行之前有机会执行一些初始化工作。
对于类型为RasterTaskImpl的Task来说,它们的初始化工作就是创建一个Canvas,如下所示:
class RasterTaskImpl : public RasterTask {
public:
......
virtual void ScheduleOnOriginThread(RasterizerTaskClient* client) OVERRIDE {
......
canvas_ = client->AcquireCanvasForRaster(this);
}
......
private:
......
SkCanvas* canvas_;
......
};这个函数定义在文件external/chromium_org/cc/resources/tile_manager.cc中。
前面我们假设CC模块使用GPU来执行光栅化操作,这时候参数client指向的就是一个DirectRasterWorkerPool对象。RasterTaskImpl类的成员函数ScheduleOnOriginThread调用这个DirectRasterWorkerPool对象的成员函数AcquireCanvasForRaster创建了一个Canvas,并且将这个Canvas保存在成员变量canvas_中。后面在执行光栅化操作时,就会用到这个Canvas。
如果CC模块使用CPU来执行光栅化操作,那么参数client指向的就是一个ImageRasterWorkerPool、ImageCopyRasterWorkerPool或者PixelBufferRasterWorkerPool对象,调用这些对象的成员函数AcquireCanvasForRaster同样可以创建一个Canvas。
不同的光栅化方式的区别就在于它们使用的是不同的Canvas。在接下来的两篇文章中,我们再详细分析这些Canvas的创建过程,以便了解GPU光栅化和CPU光栅化的原理。
这一步执行完成之后,分块光栅化所所需要的Canvas就创建好了。回到DirectRasterWorkerPool类的成员函数ScheduleTasks中,接下来它就会调用成员变量task_graph_runner_指向的一个TaskGraphRunner对象的成员函数ScheduleTasks就对这些分块所关联的光栅化任务进行排序,以确保这些光栅化任务按照优先级从高到低的顺序执行,如下所示:
void TaskGraphRunner::ScheduleTasks(NamespaceToken token, TaskGraph* graph) {
......
{
base::AutoLock lock(lock_);
......
TaskNamespace& task_namespace = namespaces_[token.id_];
// First adjust number of dependencies to reflect completed tasks.
for (Task::Vector::iterator it = task_namespace.completed_tasks.begin();
it != task_namespace.completed_tasks.end();
++it) {
for (DependentIterator node_it(graph, it->get()); node_it; ++node_it) {
TaskGraph::Node& node = *node_it;
......
node.dependencies--;
}
}
// Build new "ready to run" queue and remove nodes from old graph.
task_namespace.ready_to_run_tasks.clear();
for (TaskGraph::Node::Vector::iterator it = graph->nodes.begin();
it != graph->nodes.end();
++it) {
TaskGraph::Node& node = *it;
......
// Task is not ready to run if dependencies are not yet satisfied.
if (node.dependencies)
continue;
// Skip if already finished running task.
if (node.task->HasFinishedRunning())
continue;
// Skip if already running.
if (std::find(task_namespace.running_tasks.begin(),
task_namespace.running_tasks.end(),
node.task) != task_namespace.running_tasks.end())
continue;
task_namespace.ready_to_run_tasks.push_back(
PrioritizedTask(node.task, node.priority));
}
// Rearrange the elements in |ready_to_run_tasks| in such a way that they
// form a heap.
std::make_heap(task_namespace.ready_to_run_tasks.begin(),
task_namespace.ready_to_run_tasks.end(),
CompareTaskPriority);
// Swap task graph.
task_namespace.graph.Swap(graph);
......
// Build new "ready to run" task namespaces queue.
ready_to_run_namespaces_.clear();
for (TaskNamespaceMap::iterator it = namespaces_.begin();
it != namespaces_.end();
++it) {
if (!it->second.ready_to_run_tasks.empty())
ready_to_run_namespaces_.push_back(&it->second);
}
// Rearrange the task namespaces in |ready_to_run_namespaces_| in such a way
// that they form a heap.
std::make_heap(ready_to_run_namespaces_.begin(),
ready_to_run_namespaces_.end(),
CompareTaskNamespacePriority);
......
}
}这个函数定义在文件external/chromium_org/cc/resources/task_graph_runner.cc中。
TaskGraphRunner类的成员函数ScheduleTasks的实现比较长,我们分段来阅读。
第一段代码如下所示:
void TaskGraphRunner::ScheduleTasks(NamespaceToken token, TaskGraph* graph) {
......
{
base::AutoLock lock(lock_);
......
TaskNamespace& task_namespace = namespaces_[token.id_];这段代码主要是根据参数token在TaskGraphRunner类的成员变量namespaces_中找到一个TaskNamepspace对象task_namespace。这个TaskNamepspace对象保存了另外一个参数graph描述的Task Graph的状态信息,下面将会使用到。
TaskGraphRunner类的成员函数ScheduleTasks的第二段代码如下所示:
// First adjust number of dependencies to reflect completed tasks.
for (Task::Vector::iterator it = task_namespace.completed_tasks.begin();
it != task_namespace.completed_tasks.end();
++it) {
for (DependentIterator node_it(graph, it->get()); node_it; ++node_it) {
TaskGraph::Node& node = *node_it;
......
node.dependencies--;
}
}前面获得的TaskNamepspace对象task_namespace的成员变量completed_tasks保存了参数graph描述的Task Graph中已经执行完成了的Task。这段代码检查在参数graph描述的Task Graph中,有哪些Task依赖了这些已经执行完成了的Task。对于依赖了这些已经执行完成了的Task的Task,相应地减少它们的dependencies值。当一个Task的dependencies值等于0的时候,就表示它所依赖的Task均已经完成,于是它自己就可以执行了。
TaskGraphRunner类的成员函数ScheduleTasks的第三段代码如下所示:
// Build new "ready to run" queue and remove nodes from old graph.
task_namespace.ready_to_run_tasks.clear();
for (TaskGraph::Node::Vector::iterator it = graph->nodes.begin();
it != graph->nodes.end();
++it) {
TaskGraph::Node& node = *it;
......
// Task is not ready to run if dependencies are not yet satisfied.
if (node.dependencies)
continue;
// Skip if already finished running task.
if (node.task->HasFinishedRunning())
continue;
// Skip if already running.
if (std::find(task_namespace.running_tasks.begin(),
task_namespace.running_tasks.end(),
node.task) != task_namespace.running_tasks.end())
continue;
task_namespace.ready_to_run_tasks.push_back(
PrioritizedTask(node.task, node.priority));
}这段代码检查参数graph描述的Task Graph中的Task。对于那些dependencies值等于0,并且还没有执行的Task,将会保存在前面获得的TaskNamepspace对象task_namespace的成员变量ready_to_run_tasks描述的一个Vector中,表示它们接下来将会被调度执行。
TaskGraphRunner类的成员函数ScheduleTasks的第四段代码如下所示:
// Rearrange the elements in |ready_to_run_tasks| in such a way that they
// form a heap.
std::make_heap(task_namespace.ready_to_run_tasks.begin(),
task_namespace.ready_to_run_tasks.end(),
CompareTaskPriority);
// Swap task graph.
task_namespace.graph.Swap(graph);这段代码对前面收集到的dependencies值等于0的Task按照它们的Prioirty值组织成一个最小堆,并且将参数graph描述的Task Graph保存在前面获得的TaskNamepspace对象task_namespace的成员变量graph中。
这段代码执行完成之后,在前面获得的TaskNamepspace对象task_namespace描述的Namespace中,优先级最高的Task就保存在它的成员变量ready_to_run_tasks描述的Vector的头部,也就是这个Task就是接下来要执行的。
TaskGraphRunner类的成员函数ScheduleTasks的最后一段代码如下所示:
// Build new "ready to run" task namespaces queue.
ready_to_run_namespaces_.clear();
for (TaskNamespaceMap::iterator it = namespaces_.begin();
it != namespaces_.end();
++it) {
if (!it->second.ready_to_run_tasks.empty())
ready_to_run_namespaces_.push_back(&it->second);
}
// Rearrange the task namespaces in |ready_to_run_namespaces_| in such a way
// that they form a heap.
std::make_heap(ready_to_run_namespaces_.begin(),
ready_to_run_namespaces_.end(),
CompareTaskNamespacePriority);
......
}
}这段代码遍历TaskGraphRunner类内部管理的所有Namespace。对于那些成员变量ready_to_run_tasks描述的Vector不为空的Namespace,将会被保存在TaskGraphRunner类的另外一个成员变量ready_to_run_namespaces_描述的一个Vector中,也就是将那些接下来有Task可执行的Namespace收集起来。
将有Task可执行的Namespace收集起来之后,这段代码再将这些Namespace组织成一个最小堆,如图4所示:
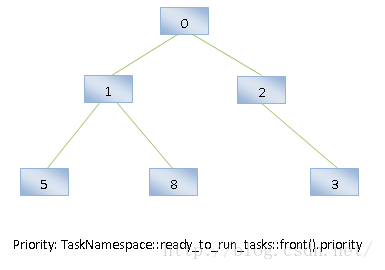
图4 Minimum Heap for Namespace
这个最小堆是按照Namespace的成员变量ready_to_run_tasks描述的Vector的头部的Task的Priority值进行排序的,也就是说,优先级最高的Task所属的Namespace将会排在最前面。
这一步执行完成之后,光栅化任务就按照最小堆的方式排列好了。回到DirectRasterWorkerPool类的成员函数ScheduleTasks中,接下来它就会调用另外一个成员函数ScheduleRunTasksOnOriginThread执行这些光栅化任务,如下所示:
void DirectRasterWorkerPool::ScheduleRunTasksOnOriginThread() {
......
task_runner_->PostTask(
FROM_HERE,
base::Bind(&DirectRasterWorkerPool::RunTasksOnOriginThread,
weak_ptr_factory_.GetWeakPtr()));
......
}这个函数定义在文件external/chromium_org/cc/resources/direct_raster_worker_pool.cc中。
从前面的分析可以知道,DirectRasterWorkerPool类的成员变量task_runner_指向的是一个SequencedTaskRunner对象。这个SequencedTaskRunner对象描述的是CC模块的Compositor线程的消息队列。
DirectRasterWorkerPool类的成员函数ScheduleRunTasksOnOriginThread所做的事情就是将通过上述SequencedTaskRunner对象向CC模块的Compositor线程的消息队列发送一个Task。这个Task绑定了DirectRasterWorkerPool类的成员函数RunTasksOnOriginThread。因此,接下来DirectRasterWorkerPool类的成员函数RunTasksOnOriginThread就会在CC模块的Compositor线程中执行,如下所示:
void DirectRasterWorkerPool::RunTasksOnOriginThread() {
......
task_graph_runner_->RunUntilIdle();
......
}这个函数定义在文件external/chromium_org/cc/resources/direct_raster_worker_pool.cc中。
前面我们已经通过DirectRasterWorkerPool类的成员变量task_graph_runner_指向的TaskGraphRunner对象的成员函数ScheduleTasks对要执行的光栅化任务按照优先级组织成了一个最小堆,现在DirectRasterWorkerPool类的成员函数RunTasksOnOriginThread就会再调用这个TaskGraphRunner对象的成员函数RunUntilIdle执行这些光栅化任务,如下所示:
void TaskGraphRunner::RunUntilIdle() {
base::AutoLock lock(lock_);
while (!ready_to_run_namespaces_.empty())
RunTaskWithLockAcquired();
}这个函数定义在文件external/chromium_org/cc/resources/task_graph_runner.cc中。
从前面的分析可以知道,TaskGraphRunner类的成员变量ready_to_run_namespaces_描述的Vector保存的是有任务需要执行的Namespace。因此,TaskGraphRunner类的成员函数RunUntilIdle就会一直遍历这个Vector,直到它的大小等于0为止。每一次遍历都会调用一次TaskGraphRunner类的成员函数RunTaskWithLockAcquired处理一个任务,如下所示:
void TaskGraphRunner::RunTaskWithLockAcquired() {
......
// Take top priority TaskNamespace from |ready_to_run_namespaces_|.
std::pop_heap(ready_to_run_namespaces_.begin(),
ready_to_run_namespaces_.end(),
CompareTaskNamespacePriority);
TaskNamespace* task_namespace = ready_to_run_namespaces_.back();
ready_to_run_namespaces_.pop_back();
......
// Take top priority task from |ready_to_run_tasks|.
std::pop_heap(task_namespace->ready_to_run_tasks.begin(),
task_namespace->ready_to_run_tasks.end(),
CompareTaskPriority);
scoped_refptr<Task> task(task_namespace->ready_to_run_tasks.back().task);
task_namespace->ready_to_run_tasks.pop_back();
// Add task namespace back to |ready_to_run_namespaces_| if not empty after
// taking top priority task.
if (!task_namespace->ready_to_run_tasks.empty()) {
ready_to_run_namespaces_.push_back(task_namespace);
std::push_heap(ready_to_run_namespaces_.begin(),
ready_to_run_namespaces_.end(),
CompareTaskNamespacePriority);
}
// Add task to |running_tasks|.
task_namespace->running_tasks.push_back(task.get());
......
{
base::AutoUnlock unlock(lock_);
task->RunOnWorkerThread();
}
......
// Remove task from |running_tasks|.
TaskVector::iterator it = std::find(task_namespace->running_tasks.begin(),
task_namespace->running_tasks.end(),
task.get());
......
std::swap(*it, task_namespace->running_tasks.back());
task_namespace->running_tasks.pop_back();
// Now iterate over all dependents to decrement dependencies and check if they
// are ready to run.
bool ready_to_run_namespaces_has_heap_properties = true;
for (DependentIterator it(&task_namespace->graph, task.get()); it; ++it) {
TaskGraph::Node& dependent_node = *it;
......
dependent_node.dependencies--;
// Task is ready if it has no dependencies. Add it to |ready_to_run_tasks_|.
if (!dependent_node.dependencies) {
bool was_empty = task_namespace->ready_to_run_tasks.empty();
task_namespace->ready_to_run_tasks.push_back(
PrioritizedTask(dependent_node.task, dependent_node.priority));
std::push_heap(task_namespace->ready_to_run_tasks.begin(),
task_namespace->ready_to_run_tasks.end(),
CompareTaskPriority);
// Task namespace is ready if it has at least one ready to run task. Add
// it to |ready_to_run_namespaces_| if it just become ready.
if (was_empty) {
......
ready_to_run_namespaces_.push_back(task_namespace);
}
ready_to_run_namespaces_has_heap_properties = false;
}
}
// Rearrange the task namespaces in |ready_to_run_namespaces_| in such a way
// that they yet again form a heap.
if (!ready_to_run_namespaces_has_heap_properties) {
std::make_heap(ready_to_run_namespaces_.begin(),
ready_to_run_namespaces_.end(),
CompareTaskNamespacePriority);
}
// Finally add task to |completed_tasks_|.
task_namespace->completed_tasks.push_back(task);
......
}这个函数定义在文件external/chromium_org/cc/resources/task_graph_runner.cc中。
TaskGraphRunner类的成员函数RunTaskWithLockAcquired的执行过程如下所示:
1. 从TaskGraphRunner类的成员变量ready_to_run_namespaces_描述的Vector中取出优先级最高的Namesapce,并且将这个Namespace从Vector中删除。
2. 从第1步取出的Namepsace的成员变量ready_to_run_tasks描述的Vector中取出优先级最高的Task,并且将这个Task从Vector中删除。
3. 经过第2步操作之后 ,如果第1步取出的Namespace的成员变量ready_to_run_tasks描述的Vector不等于空,那么需要重新将它压入到TaskGraphRunner类的成员变量ready_to_run_namespaces_描述的Vector中,并且重新对这个Vector进行最小堆排序。
4. 将第2步取出的Task保存在第1步取出的Namespace的成员变量running_tasks描述的Vector中,表示这个Task现在当前执行。
5. 执行第2步取出的Task,也就是调用它的成员函数RunOnWorkerThread。
6. 将第2步取出的Task从第1步取出的Namespace的成员变量running_tasks描述的Vector中删除,表示这个Task已经停止执行。
7. 在第1步取出的Namespace中检查有哪些Task依赖了第2步取出的Task。对于每一个依赖了的Task,都会将它的dependencies值减少1。当一个Task的dependencies值减少至0的时候,就说明它所有依赖的Task均已执行完成,于是就轮到它执行了。这时候需要将它压入到第1步取出的Namespace的成员变量ready_to_run_tasks描述的Vector中,并且重新对这个Vector进行最小堆排序。
8. 如果第1步取出的Namespace的成员变量ready_to_run_tasks描述的Vector在第7步中压入新的Task之前是空的,就说明这个Namespace之前已经从TaskGraphRunner类的成员变量ready_to_run_namespaces_描述的Vector中删除了。现在由于它有了新的可以执行的Task,因此就需要重新将它压入到TaskGraphRunner类的成员变量ready_to_run_namespaces_描述的Vector中,并且对这个Vector进行最小堆排序。
9. 将第2步取出的Task保存在第1步取出的Namespace的成员变量completed_tasks描述的Vector中,表示这个Task已经执行完成。
我们假设第2步取出的Task是一个光栅化任务,这时候就5步就会调用RasterTaskImpl类的成员函数RunOnWorkerThread执行这个Task,如下所示:
class RasterTaskImpl : public RasterTask {
public:
......
// Overridden from Task:
virtual void RunOnWorkerThread() OVERRIDE {
......
if (canvas_) {
AnalyzeAndRaster(picture_pile_->GetCloneForDrawingOnThread(
RasterWorkerPool::GetPictureCloneIndexForCurrentThread()));
}
}
......
};这个函数定义在文件external/chromium_org/cc/resources/tile_manager.cc中。
从前面的分析可以知道,此时RasterTaskImpl类的成员变量canvas_已经指向一个SkCanvas对象。在这种情况下,RasterTaskImpl类的成员函数RunOnWorkerThread首先调用PicturePileImpl类的成员函数GetCloneForDrawingOnThread获得成员变量picture_pile_描述的PicturePileImpl对象在当前线程中的拷贝,接着再将这份拷贝交给RasterTaskImpl类的另外一个成员函数AnalyzeAndRaster处理。注意,这份拷贝可以在当前线程中安全地访问,因为它是当前线程专属的。从这里我们也可以看到Chromium的多线程设计原则:当一个数据被多个线程访问时,宁可给每一个线程拷贝一份数据,也不要做锁保护,因为后者一旦出现竞争,延时将会是不确定的。
RasterTaskImpl类的成员函数AnalyzeAndRaster的实现如下所示:
class RasterTaskImpl : public RasterTask {
......
private:
void AnalyzeAndRaster(PicturePileImpl* picture_pile) {
......
if (analyze_picture_) {
Analyze(picture_pile);
if (analysis_.is_solid_color)
return;
}
Raster(picture_pile);
}
......
}这个函数定义在文件external/chromium_org/cc/resources/tile_manager.cc中。
从前面的分析可以知道,参数picture_pile指向的PictruePileImpl对象来自于RasterTaskImpl类的成员变量picturepile,这个PictruePileImpl对象记录了当前要执行光栅化操作的分块的绘制命令。
当RasterTaskImpl类的成员变量analyze_picture_的值等于true的时候,表示要对参数picture_pile记录的分块绘制命令进行分析。如果分析表明分块的绘制结果是一个单一颜色,那么RasterTaskImpl类的成员变量analysis_指向的一个Analysis对象的成员变量is_solid_color的值就会等于true,并且它的另外一个成员变量solid_color记录了该单一颜色。在这种情况下,就没有必要对分块执行光栅化操作了。这样做带来的另外一个好处是可以节省一个纹理资源。本来纹理资源是用来保存分块的光栅化结果的,但是由于光栅化结果用一个颜色值就可以表示,因此就不用浪费一个纹理资源了。
如果RasterTaskImpl类的成员变量analyze_picture_的值等于false,或者分析表明分块的绘制结果不是一个单一颜色,那么就需要对分块执行光栅化操作。这是通过调用RasterTaskImpl类的成员函数Raster实现的,如下所示:
class RasterTaskImpl : public RasterTask {
......
private:
......
void Raster(PicturePileImpl* picture_pile) {
......
picture_pile->RasterToBitmap(
canvas_, content_rect_, contents_scale_, stats);
......
}
......
}这个函数定义在文件external/chromium_org/cc/resources/tile_manager.cc中。
RasterTaskImpl类的成员函数Raster主要是调用参数picture_pile指向的一个PicturePileImpl对象的成员函数RasterToBitmap对分块进行光栅化。光栅化的结果就保存在RasterTaskImpl类的成员变量canvas_描述的一个Canvas中。
PicturePileImpl类的成员函数RasterToBitmap的实现如下所示:
void PicturePileImpl::RasterToBitmap(
SkCanvas* canvas,
const gfx::Rect& canvas_rect,
float contents_scale,
RenderingStatsInstrumentation* rendering_stats_instrumentation) {
......
RasterCommon(canvas,
NULL,
canvas_rect,
contents_scale,
rendering_stats_instrumentation,
false);
}这个函数定义在文件external/chromium_org/cc/resources/picture_pile_impl.cc中。
PicturePileImpl类的成员函数RasterToBitmap调用另外一个成员函数RasterCommon将分块光栅化在参数canvas描述的Canvas上,如下所示:
void PicturePileImpl::RasterCommon(
SkCanvas* canvas,
SkDrawPictureCallback* callback,
const gfx::Rect& canvas_rect,
float contents_scale,
RenderingStatsInstrumentation* rendering_stats_instrumentation,
bool is_analysis) {
......
canvas->translate(-canvas_rect.x(), -canvas_rect.y());
gfx::Rect content_tiling_rect = gfx::ToEnclosingRect(
gfx::ScaleRect(tiling_.tiling_rect(), contents_scale));
content_tiling_rect.Intersect(canvas_rect);
canvas->clipRect(gfx::RectToSkRect(content_tiling_rect),
SkRegion::kIntersect_Op);
PictureRegionMap picture_region_map;
CoalesceRasters(
canvas_rect, content_tiling_rect, contents_scale, &picture_region_map);
......
// Iterate the coalesced map and use each picture's region
// to clip the canvas.
for (PictureRegionMap::iterator it = picture_region_map.begin();
it != picture_region_map.end();
++it) {
Picture* picture = it->first;
Region negated_clip_region = it->second;
......
int repeat_count = std::max(1, slow_down_raster_scale_factor_for_debug_);
int rasterized_pixel_count = 0;
for (int j = 0; j < repeat_count; ++j) {
......
rasterized_pixel_count = picture->Raster(
canvas, callback, negated_clip_region, contents_scale);
......
}
......
}
......
}这个函数定义在文件external/chromium_org/cc/resources/picture_pile_impl.cc中。
参数canvas_rect描述的是分块的位置和大小,PicturePileImpl类的成员函数RasterCommon首先将画布的位置移到分块的位置上,也就是以分块的位置为原点。
PicturePileImpl类的成员函数RasterCommon接下来计算分块所在的Layer在缩放因子contents_scale下的大小content_tiling_rect。取这个大小与分块大小的交集,用作画布的裁剪空间。这个裁剪空间就限定了后面的绘图操作只作用在分块上。
回忆前面Chromium网页Layer Tree绘制过程分析一文,CC Layer Tree中的Layer也是以分块的形式进行绘制的,也就是它的绘制命令记录在一系列的Picture对象中。这些Picture对象在将CC Layer Tree同步为CC Pending Layer Tree的时候,会一起同步到后者中去,也就是保存在PicturePileImpl类的成员变量picture_map_描述的一个Map中。这一点可以参考前面Chromium网页Layer Tree同步为Pending Layer Tree的过程分析一文。
这里有一点需要注意。虽然CC Layer Tree和CC Pending Layer Tree中的Layer都是分块管理的,但两者的分块划分是独立的,也就是在CC Layer Tree和CC Pending Layer Tree中对应的两个Layer,它们的分块大小和个数都是不一样的。假设L1和L2分别为CC Pending Layer Tree和CC Layer Tree两个对应的Layer。L1被划分为{T1、T2、T3、T4}四个分块,L2被划分为{P1、P2、P3}三个分块。假设T2分块与P2、P3分块均有相关,那么在对T2分块进行光栅化时,就需要找到与P2、P3分块对应的Picture对象。因为这两个Picture对象记录了T2分块的绘制命令。
PicturePileImpl类的成员函数RasterCommon调用另外一个成员函数CoalesceRasters就是为了找到那些与当前要光栅化的分块相交的Picture对象。有了这些Picture对象之后,接下来就依次调用这些Picture对象的成员函数Raster,以便让它们执行自己记录的绘制命令。这些绘制命令的执行是通过调用参数canvas描述的画布上的绘图接口实现的,也就是这些绘制命令作用在参数canvas描述的画布上,并且限定在当前正在执行光栅化操作的分块的区域内。
画布的本质是一个图形缓冲区。在GPU光栅化方式中,这个图形缓冲区位于GPU中,通过一个纹理对象描述。在CPU光栅化方式中,这个图形缓冲区位于CPU中,或者说可以直接被CPU访问,相当于是一块普通的内存缓冲区。当调用画布提供的绘图接口时,就会将画布底层的图形缓冲区的内容设置为一系列的RGB值。这些RGB值就是光栅化的结果。
这一步执行完成之后,一个分块的光栅化操作就执行完成了,也就是一个光栅化任务执行完成了。前面提到,每一个光栅化任务都绑定了TileManager类的成员函数OnRasterTaskCompleted,也就是每当一个分块光栅化操作执行完成,都会调用TileManager类的成员函数OnRasterTaskCompleted。
接下来,我们就继续分析TileManager类的成员函数OnRasterTaskCompleted的实现,如下所示:
void TileManager::OnRasterTaskCompleted(
Tile::Id tile_id,
scoped_ptr<ScopedResource> resource,
RasterMode raster_mode,
const PicturePileImpl::Analysis& analysis,
bool was_canceled) {
TileMap::iterator it = tiles_.find(tile_id);
......
Tile* tile = it->second;
ManagedTileState& mts = tile->managed_state();
ManagedTileState::TileVersion& tile_version = mts.tile_versions[raster_mode];
......
tile_version.raster_task_ = NULL;
......
if (analysis.is_solid_color) {
tile_version.set_solid_color(analysis.solid_color);
resource_pool_->ReleaseResource(resource.Pass());
} else {
tile_version.set_use_resource();
tile_version.resource_ = resource.Pass();
......
}
......
}这个函数定义在文件external/chromium_org/cc/resources/tile_manager.cc中。
参数tile_id表示执行完成光栅化操作的分块的ID。通过这个ID可以在TileManager类的成员变量tiles_描述的Map中找到一个对应的Tile对象。这个Tile对象就是用来描述执行完成了光栅化操作的分块的。
TileManager类的成员函数OnRasterTaskCompleted接下来找到分块当前使用的版本,也就是一个TileVersion对象,并且将这个TileVersion对象的成员变量raster_task_的值设置为NULL,表示它之前关联的光栅化任务已经执行完成。
TileManager类的成员函数OnRasterTaskCompleted最后是处理分块的光栅化结果。如果分块的光栅化结果是一个单一的颜色值,那么就将这个颜色值记录下来,并且释放在光栅化操作执行之前分配给分块的纹理资源,这样就可以节省一个纹理资源。另一方面,如果分块的光栅化结果不是一个单一的颜色值,那么就需要继续使用在光栅化操作执行之前分配给分块的纹理资源,因为光栅化结果就保存在这个纹理资源上。
从前面的分析可以知道,当所有标记为Required For Activation的分块光栅化操作完成之后,图3所示的类型为RasterRequiredForActivationFinishedTaskImpl的任务就会执行。在我们这个情景中,这个任务绑定了DirectRasterWorkerPool类的成员函数OnRasterRequiredForActivationFinished,也就是这时候DirectRasterWorkerPool类的成员函数OnRasterRequiredForActivationFinished会被执行。
DirectRasterWorkerPool类的成员函数OnRasterRequiredForActivationFinished的实现如下所示:
void DirectRasterWorkerPool::OnRasterRequiredForActivationFinished() {
......
client_->DidFinishRunningTasksRequiredForActivation();
}这个函数定义在文件external/chromium_org/cc/resources/direct_raster_worker_pool.cc中。
DirectRasterWorkerPool类的成员变量client_指向的是一个TileManager对象。DirectRasterWorkerPool类的成员函数OnRasterRequiredForActivationFinished调用这个TileManager对象的成员函数DidFinishRunningTasksRequiredForActivation通知它所有标记为Required For Activation的分块都光栅化完成了。
TileManager类的成员函数DidFinishRunningTasksRequiredForActivation的实现如下所示:
void TileManager::DidFinishRunningTasksRequiredForActivation() {
......
ready_to_activate_check_notifier_.Schedule();
}这个函数定义在文件external/chromium_org/cc/resources/tile_manager.cc中。
TileManager类的成员变量ready_to_activate_check_notifier_描述的是一个UniqueNotifier对象。这个UniqueNotifier对象绑定了TileManager类的成员函数CheckIfReadyToActivate。也就是当TileManager类的成员函数DidFinishRunningTasksRequiredForActivation调用它的成员函数Schedule的时候,就会触发TileManager类的成员函数CheckIfReadyToActivate被执行。
TileManager类的成员函数CheckIfReadyToActivate的实现如下所示:
void TileManager::CheckIfReadyToActivate() {
......
rasterizer_->CheckForCompletedTasks();
......
if (IsReadyToActivate())
client_->NotifyReadyToActivate();
}这个函数定义在文件external/chromium_org/cc/resources/tile_manager.cc中。
在我们这个情景中,TileManager类的成员变量rasterizer_指向的是一个DirectRasterWorkerPool对象。TileManager类的成员函数CheckIfReadyToActivate首先调用这个DirectRasterWorkerPool对象的成员函数CheckForCompletedTasks处理当前已经执行完成的任务,如下所示:
void DirectRasterWorkerPool::CheckForCompletedTasks() {
.....
task_graph_runner_->CollectCompletedTasks(namespace_token_,
&completed_tasks_);
for (Task::Vector::const_iterator it = completed_tasks_.begin();
it != completed_tasks_.end();
++it) {
RasterizerTask* task = static_cast<RasterizerTask*>(it->get());
......
task->CompleteOnOriginThread(this);
......
}
completed_tasks_.clear();
}这个函数定义在文件external/chromium_org/cc/resources/direct_raster_worker_pool.cc中。
DirectRasterWorkerPool类的成员函数CheckForCompletedTasks主要是调用成员变量task_graph_runner_指向一个TaskGraphRunner对象的成员函数CollectCompletedTasks收集那些已经执行完成的任务,并且保存在成员变量completed_tasks_描述的一个Vector。
DirectRasterWorkerPool类的成员函数CheckForCompletedTasks接下来遍历前面收集到的每一个任务,并且调用它们的成员函数CompleteOnOriginThread,让它们执行一些善后工作。对于光栅化任务来说,就是调用RasterTaskImpl类的成员函数CompleteOnOriginThread,如下所示:
class RasterTaskImpl : public RasterTask {
public:
......
virtual void CompleteOnOriginThread(RasterizerTaskClient* client) OVERRIDE {
canvas_ = NULL;
client->ReleaseCanvasForRaster(this);
}
......
};这个函数定义在文件external/chromium_org/cc/resources/tile_manager.cc中。
RasterTaskImpl类的成员函数CompleteOnOriginThread主要就是调用参数client指向的DirectRasterWorkerPool对象的成员函数ReleaseCanvasForRaster释放之前创建的一个画布。
这一步执行完成后,回到TileManager类的成员函数CheckIfReadyToActivate中,它接下来调用另外一个成员函数IsReadyToActivate确保是否所有标记为Required For Activation都已经光栅化完成,如下所示:
bool TileManager::IsReadyToActivate() const {
const std::vector<PictureLayerImpl*>& layers = client_->GetPictureLayers();
for (std::vector<PictureLayerImpl*>::const_iterator it = layers.begin();
it != layers.end();
++it) {
if (!(*it)->AllTilesRequiredForActivationAreReadyToDraw())
return false;
}
return true;
}这个函数定义在文件external/chromium_org/cc/resources/tile_manager.cc中。
如果所有标记为Required For Activation都已经光栅化完成,那么TileManager类的成员函数IsReadyToActivate的返回值就会等于true,这时候TileManager类的成员函数CheckIfReadyToActivate就会调用成员变量client_所指向的一个LayerTreeHostImpl对象的成员函数NotifyReadyToActivate,用来通知它可以将CC Pending Layer Tree激活为CC Active Layer Tree了。
LayerTreeHostImpl类的成员函数NotifyReadyToActivate的实现如下所示:
void LayerTreeHostImpl::NotifyReadyToActivate() {
client_->NotifyReadyToActivate();
}这个函数定义在文件external/chromium_org/cc/trees/layer_tree_host_impl.cc中。
LayerTreeHostImpl类的成员函数NotifyReadyToActivate调用成员变量client_指向的一个ThreadProxy对象的成员函数NotifyReadyToActivate,用来通知它调度执行一个ACTION_ACTIVATE_PENDING_TREE操作,如下所示:
void ThreadProxy::NotifyReadyToActivate() {
......
impl().scheduler->NotifyReadyToActivate();
}这个函数定义在文件external/chromium_org/cc/trees/thread_proxy.cc中。
ThreadProxy对象的成员函数NotifyReadyToActivate调用Scheduler类的成员函数NotifyReadyToActivate修改调度器的内部状态,以便接下来可以触发一个ACTION_ACTIVATE_PENDING_TREE操作,如下所示:
void Scheduler::NotifyReadyToActivate() {
state_machine_.NotifyReadyToActivate();
ProcessScheduledActions();
}这个函数定义在文件external/chromium_org/cc/scheduler/scheduler.cc中。
Scheduler类的成员函数NotifyReadyToActivate首先调用SchedulerStateMachine类的成员函数NotifyReadyToActivate修改调度器的内部状态,如下所示:
void SchedulerStateMachine::NotifyReadyToActivate() {
if (has_pending_tree_)
pending_tree_is_ready_for_activation_ = true;
}这个函数定义在文件external/chromium_org/cc/scheduler/scheduler_state_machine.cc中。
在成员变量has_pending_tree_的值等于true的情况下,也是当前存在CC Pending Layer Tree的情况下,SchedulerStateMachine类的另外一个成员变量pending_tree_is_ready_for_activation_的值也会被设置为true,表示要将当前存在的CC Pending Layer Tree激活为CC Acitve Layer Tree。
这一步执行完成后,回到Scheduler类的成员函数NotifyReadyToActivate中,它接下来再调用另外一个成员函数ProcessScheduledActions,这时候就会触发一个ACTION_ACTIVATE_PENDING_TREE操作,用来将CC Pending Layer Tree激活为CC Acitve Layer Tree。这个激活过程我们在后面的文章再分析。
从前面的分析又可以知道,当所有分块都光栅化完成之后,图3所示的类型为RasterFinishedTaskImpl的任务就会执行。在我们这个情景中,这个任务绑定了DirectRasterWorkerPool类的成员函数OnRasterFinished,也就是这时候DirectRasterWorkerPool类的成员函数OnRasterFinished会被执行。
DirectRasterWorkerPool类的成员函数OnRasterFinished的实现如下所示:
void DirectRasterWorkerPool::OnRasterFinished() {
......
client_->DidFinishRunningTasks();
}这个函数定义在文件external/chromium_org/cc/resources/direct_raster_worker_pool.cc中。
DirectRasterWorkerPool类的成员函数OnRasterFinished调用成员变量client_指向的一个TileManager对象的成员函数DidFinishRunningTasks,用来通知它所有需要执行光栅化的分块均已光栅化完成,如下所示:
void TileManager::DidFinishRunningTasks() {
......
bool memory_usage_above_limit = resource_pool_->total_memory_usage_bytes() >
global_state_.soft_memory_limit_in_bytes;
// When OOM, keep re-assigning memory until we reach a steady state
// where top-priority tiles are initialized.
if (all_tiles_that_need_to_be_rasterized_have_memory_ &&
!memory_usage_above_limit)
return;
rasterizer_->CheckForCompletedTasks();
......
TileVector tiles_that_need_to_be_rasterized;
AssignGpuMemoryToTiles(&prioritized_tiles_,
&tiles_that_need_to_be_rasterized);
// |tiles_that_need_to_be_rasterized| will be empty when we reach a
// steady memory state. Keep scheduling tasks until we reach this state.
if (!tiles_that_need_to_be_rasterized.empty()) {
ScheduleTasks(tiles_that_need_to_be_rasterized);
return;
}
......
ready_to_activate_check_notifier_.Schedule();
}这个函数定义在文件external/chromium_org/cc/resources/tile_manager.cc中。
TileManager类的成员函数DidFinishRunningTasks首先计算现在是否有空闲的光栅化内存,也就是已经使用的光栅化内存小于设定的软上限值。如果没有空闲的光栅化内存,并且所有需要光栅化的分块均已分配了光栅化内存,那么TileManager类的成员函数DidFinishRunningTasks就什么也不做。注意,当所有需要光栅化的分块均已分配了光栅化内存时,TileManager类的成员变量all_tiles_that_need_to_be_rasterized_have_memory_的值就会等于true。
假设现在有空闲的光栅化内存,并且不是所有需要光栅化的分块均已分配了光栅化内存,那么TileManager类的成员函数DidFinishRunningTasks接下来就会调用成员变量rasterizer_指向的一个DirectRasterWorkerPool对象的成员函数CheckForCompletedTasks处理那些已经执行完成了的任务。这一点我们前面我们已经分析过。
TileManager类的成员函数DidFinishRunningTasks再接着又会调用前面分析过的另外一个函数AssignGpuMemoryToTiles收集那些之前就需要光栅化的、但是由于资源限制而没有获得分配光栅化内存的分块。如果能够收集到这样的分块,那么又会继续调用前面分析过的TileManager类的成员函数ScheduleTasks对它们进行光栅化操作。另一方面,如果没有收集到这样的分块,那么TileManager类的成员函数DidFinishRunningTasks就会通过成员变量ready_to_activate_check_notifier_描述的一个UniqueNotifier对象执行另外一个成员函数CheckIfReadyToActivate,用来通知调度器执行一个ACTION_ACTIVATE_PENDING_TREE操作。
这样,我们就以GPU光栅化为例,分析完成了网页分块的光栅化过程。GPU光栅化与CPU光栅化除了它们使用的画布不同之外,还有另外一个重要的区别,那就是GPU光栅化操作由Compositor线程执行,而CPU光栅化操作由专门的一组光栅化线程执行。为什么会有这样的区别呢?通过前面Chromium硬件加速渲染机制基础知识简要介绍和学习计划这个系列的文章的学习,Render进程中的GPU命令是由GPU进程来执行的。这样,Render进程在执行GPU命令时,会"很快"完成。这是因为只要命令一发送给GPU进程,Render进程就认为命令执行完成了。因此,CC模块就没有必要创建一组光栅化线程执行GPU光栅化操作。相反,CPU光栅化就切切实实地发生在Render进程,因此就需要创建一组光栅化线程执行它们,避免阻塞Compositor线程。
接下来我们就简要分析CPU光栅化所用的线程组的创建和执行过程。从前面Chromium网页绘图表面(Output Surface)创建过程分析一文可以知道,CC模块在为网页创建绘图表面的过程中,会创建一个Raster Worker Pool,专门用来对网页的分块进行光栅化,如下所示:
void LayerTreeHostImpl::CreateAndSetTileManager() {
......
if (use_gpu_rasterization_ && context_provider) {
......
raster_worker_pool_ =
DirectRasterWorkerPool::Create(proxy_->ImplThreadTaskRunner(),
resource_provider_.get(),
context_provider);
......
} else if (UseZeroCopyTextureUpload()) {
......
raster_worker_pool_ =
ImageRasterWorkerPool::Create(proxy_->ImplThreadTaskRunner(),
RasterWorkerPool::GetTaskGraphRunner(),
resource_provider_.get());
......
} else if (UseOneCopyTextureUpload()) {
......
raster_worker_pool_ = ImageCopyRasterWorkerPool::Create(
proxy_->ImplThreadTaskRunner(),
RasterWorkerPool::GetTaskGraphRunner(),
resource_provider_.get(),
staging_resource_pool_.get());
......
} else {
......
raster_worker_pool_ = PixelBufferRasterWorkerPool::Create(
proxy_->ImplThreadTaskRunner(),
RasterWorkerPool::GetTaskGraphRunner(),
resource_provider_.get(),
transfer_buffer_memory_limit_);
......
}
......
}这个函数定义在文件external/chromium_org/cc/trees/layer_tree_host_impl.cc中。
不同的光栅化方式来分别创建不同类型的Raster Worker Pool。不过我们观察到,在三种CPU光栅化方式中,均会调用到RasterWorkerPool类的静态成员函数GetTaskGraphRunner获得一个TaskGraphRunner对象。这个TaskGraphRunner对象就是用来对网页的分块执行CPU光栅化操作的。
RasterWorkerPool类的静态成员函数GetTaskGraphRunner的实现如下所示:
base::LazyInstance<RasterTaskGraphRunner>::Leaky g_task_graph_runner =
LAZY_INSTANCE_INITIALIZER;
......
TaskGraphRunner* RasterWorkerPool::GetTaskGraphRunner() {
return g_task_graph_runner.Pointer();
}这个函数定义在文件external/chromium_org/cc/resources/raster_worker_pool.cc中。
当RasterWorkerPool类的静态成员函数GetTaskGraphRunner第一次被调用时,全局变量g_task_graph_runner指向的一个RasterTaskGraphRunner对象就会先创建,然后再返回给调用者,也就是LayerTreeHostImpl类的成员函数CreateAndSetTileManager。
LayerTreeHostImpl类的成员函数CreateAndSetTileManager会使用获得的RasterTaskGraphRunner对象创建一个Raster Worker Pool。例如,在Zero Copy这种CPU光栅化方式中,Raster Worker Pool是通过调用ImageRasterWorkerPool类的静态成员函数Create创建的,如下所示:
scoped_ptr<RasterWorkerPool> ImageRasterWorkerPool::Create(
base::SequencedTaskRunner* task_runner,
TaskGraphRunner* task_graph_runner,
ResourceProvider* resource_provider) {
return make_scoped_ptr<RasterWorkerPool>(new ImageRasterWorkerPool(
task_runner, task_graph_runner, resource_provider));
}这个函数定义在文件external/chromium_org/cc/resources/image_raster_worker_pool.cc中。
参数task_graph_runner指向的便是前面获得的RasterTaskGraphRunner对象,ImageRasterWorkerPool类的静态成员函数Create将会使用这个RasterTaskGraphRunner对象创建一个ImageRasterWorkerPool对象,如下所示:
ImageRasterWorkerPool::ImageRasterWorkerPool(
base::SequencedTaskRunner* task_runner,
TaskGraphRunner* task_graph_runner,
ResourceProvider* resource_provider)
: task_runner_(task_runner),
task_graph_runner_(task_graph_runner),
...... {}这个函数定义在文件external/chromium_org/cc/resources/image_raster_worker_pool.cc中。
从这里就可以看到,前面获得的RasterTaskGraphRunner对象最终就会保存在ImageRasterWorkerPool类的成员变量task_graph_runner_中。另外,从前面的调用过程还可以知道,参数task_runner指向SequencedTaskRunner对象的描述的是Compositor线程的消息队列。这个SequencedTaskRunner对象保存在ImageRasterWorkerPool类的另外一个成员变量task_runner_中。
上述全局变量g_task_graph_runner指向的RasterTaskGraphRunner对象在创建的时候,就会创建一组光栅化线程,如下所示:
class RasterTaskGraphRunner : public TaskGraphRunner,
public base::DelegateSimpleThread::Delegate {
public:
RasterTaskGraphRunner() {
size_t num_threads = RasterWorkerPool::GetNumRasterThreads();
while (workers_.size() < num_threads) {
scoped_ptr<base::DelegateSimpleThread> worker =
make_scoped_ptr(new base::DelegateSimpleThread(
this,
base::StringPrintf("CompositorRasterWorker%u",
static_cast<unsigned>(workers_.size() + 1))
.c_str()));
worker->Start();
......
workers_.push_back(worker.Pass());
}
}
......
private:
......
ScopedPtrDeque<base::DelegateSimpleThread> workers_;
.....
};这个函数定义在文件external/chromium_org/cc/resources/raster_worker_pool.cc中。
要创建的光栅化线程的个数通过调用RasterWorkerPool类的静态成员函数GetNumRasterThreads获得。在默认情况下,光栅化线程的个数为1,不过可以通过启动选项"num-raster-threads"修改默认设置,可以设置的范围为[1, 64]。
每一个光栅化线程创建出来之后,都会调用RasterTaskGraphRunner类的成员函数Run进入运行状态,如下所示:
class RasterTaskGraphRunner : public TaskGraphRunner,
public base::DelegateSimpleThread::Delegate {
public:
......
private:
......
virtual void Run() OVERRIDE {
......
TaskGraphRunner::Run();
}
.....
};这个函数定义在文件external/chromium_org/cc/resources/raster_worker_pool.cc中。
RasterTaskGraphRunner类的成员函数Run主要是调用父类TaskGraphRunner的成员函数Run进入运行状态,如下所示:
void TaskGraphRunner::Run() {
base::AutoLock lock(lock_);
while (true) {
if (ready_to_run_namespaces_.empty()) {
// Exit when shutdown is set and no more tasks are pending.
if (shutdown_)
break;
// Wait for more tasks.
has_ready_to_run_tasks_cv_.Wait();
continue;
}
RunTaskWithLockAcquired();
}
// We noticed we should exit. Wake up the next worker so it knows it should
// exit as well (because the Shutdown() code only signals once).
has_ready_to_run_tasks_cv_.Signal();
}这个函数定义在文件external/chromium_org/cc/resources/task_graph_runner.cc中。
每一个光栅化线程在运行期间,都会检查TaskGraphRunner类的成员变量ready_to_run_namespaces_描述的一个Vector是否为空。如果为空,那么就会在TaskGraphRunner类的另外一个成员变量has_ready_to_run_tasks_cv_描述的一个条件变量上进行等待,直到上述Vector不为空为止。
从前面的分析可以知道,TaskGraphRunner类的成员变量ready_to_run_namespaces_描述的Vector保存的是当前有任务可以执行的Namespace。这些任务将通过调用前面我们已经分析过的TaskGraphRunner类的成员函数RunTaskWithLockAcquired执行。
TaskGraphRunner类的另外一个成员变量has_ready_to_run_tasks_cv_描述的条件变量在什么情况被设置有信号的呢?我们以Zero Copy这种CPU光栅化方式为例,说明上述条件变量设置为有信号的过程。
在Zero Copy CPU光栅化方式中,负责对分块执行光栅化操作的是一个ImageRasterWorkerPool对象。也就是当Tile Manager需要对分块执行光栅化操作时,就会调用ImageRasterWorkerPool类的成员函数ScheduleTasks。
ImageRasterWorkerPool类的成员函数ScheduleTasks的实现如下所示:
void ImageRasterWorkerPool::ScheduleTasks(RasterTaskQueue* queue) {
......
unsigned priority = kRasterTaskPriorityBase;
......
scoped_refptr<RasterizerTask>
new_raster_required_for_activation_finished_task(
CreateRasterRequiredForActivationFinishedTask(
queue->required_for_activation_count,
task_runner_.get(),
base::Bind(
&ImageRasterWorkerPool::OnRasterRequiredForActivationFinished,
raster_finished_weak_ptr_factory_.GetWeakPtr())));
scoped_refptr<RasterizerTask> new_raster_finished_task(
CreateRasterFinishedTask(
task_runner_.get(),
base::Bind(&ImageRasterWorkerPool::OnRasterFinished,
raster_finished_weak_ptr_factory_.GetWeakPtr())));
for (RasterTaskQueue::Item::Vector::const_iterator it = queue->items.begin();
it != queue->items.end();
++it) {
const RasterTaskQueue::Item& item = *it;
RasterTask* task = item.task;
DCHECK(!task->HasCompleted());
if (item.required_for_activation) {
graph_.edges.push_back(TaskGraph::Edge(
task, new_raster_required_for_activation_finished_task.get()));
}
InsertNodesForRasterTask(&graph_, task, task->dependencies(), priority++);
graph_.edges.push_back(
TaskGraph::Edge(task, new_raster_finished_task.get()));
}
InsertNodeForTask(&graph_,
new_raster_required_for_activation_finished_task.get(),
kRasterRequiredForActivationFinishedTaskPriority,
queue->required_for_activation_count);
InsertNodeForTask(&graph_,
new_raster_finished_task.get(),
kRasterFinishedTaskPriority,
queue->items.size());
ScheduleTasksOnOriginThread(this, &graph_);
task_graph_runner_->ScheduleTasks(namespace_token_, &graph_);
raster_finished_task_ = new_raster_finished_task;
raster_required_for_activation_finished_task_ =
new_raster_required_for_activation_finished_task;
......
}这个函数定义在文件external/chromium_org/cc/resources/image_raster_worker_pool.cc中。
与前面分析的DirectRasterWorkerPool类的成员函数ScheduleTasks类似,ImageRasterWorkerPool类的成员函数ScheduleTasks主要是做三件事情:
1. 构建图3所示的Task Graph。
2. 调用成员函数ScheduleTasksOnOriginThread为每一个光栅化任务创建Canvas。
3. 调用成员变量task_graph_runner_指向的RasterTaskGraphRunner对象的成员函数ScheduleTasks对分块执行光栅化操作。
唯一与DirectRasterWorkerPool类的成员函数ScheduleTasks不同的地方是,后者是通过调用自己的另外一个成员函数ScheduleRunTasksOnOriginThread对分块执行光栅化操作的。
RasterTaskGraphRunner类的成员函数ScheduleTasks是从父类TaskGraphRunner继承下来的,它的实现如下所示:
void TaskGraphRunner::ScheduleTasks(NamespaceToken token, TaskGraph* graph) {
......
{
base::AutoLock lock(lock_);
......
// Rearrange the elements in |ready_to_run_tasks| in such a way that they
// form a heap.
std::make_heap(task_namespace.ready_to_run_tasks.begin(),
task_namespace.ready_to_run_tasks.end(),
CompareTaskPriority);
......
// Rearrange the task namespaces in |ready_to_run_namespaces_| in such a way
// that they form a heap.
std::make_heap(ready_to_run_namespaces_.begin(),
ready_to_run_namespaces_.end(),
CompareTaskNamespacePriority);
// If there is more work available, wake up worker thread.
if (!ready_to_run_namespaces_.empty())
has_ready_to_run_tasks_cv_.Signal();
}
}这个函数定义在文件external/chromium_org/cc/resources/task_graph_runner.cc中。
TaskGraphRunner类的成员函数ScheduleTasks的实现我们在前面已经分析过,它主要就收集那些当前没有依赖的任务,或者说所有依赖均已执行完成了的任务,并且对这些任务按照优先级进行最小堆排序。不过当前我们没有提到,当收集到的任务的个数大于0时,TaskGraphRunner类的成员函数ScheduleTasks就会将成员变量as_ready_to_run_tasks_cv_描述的条件变量设置为有信号。
从前面的分析可以知道,一旦TaskGraphRunner类的成员变量as_ready_to_run_taskscv 描述的条件变量被设置为有信号,那么就会有一个光栅化线程被唤醒。这个光栅化线程被唤醒之后 ,就会调用TaskGraphRunner类的成员函数RunTaskWithLockAcquired,如下所示:
void TaskGraphRunner::RunTaskWithLockAcquired() {
......
// Take top priority TaskNamespace from |ready_to_run_namespaces_|.
std::pop_heap(ready_to_run_namespaces_.begin(),
ready_to_run_namespaces_.end(),
CompareTaskNamespacePriority);
TaskNamespace* task_namespace = ready_to_run_namespaces_.back();
ready_to_run_namespaces_.pop_back();
......
// Take top priority task from |ready_to_run_tasks|.
std::pop_heap(task_namespace->ready_to_run_tasks.begin(),
task_namespace->ready_to_run_tasks.end(),
CompareTaskPriority);
scoped_refptr<Task> task(task_namespace->ready_to_run_tasks.back().task);
task_namespace->ready_to_run_tasks.pop_back();
......
// There may be more work available, so wake up another worker thread.
has_ready_to_run_tasks_cv_.Signal();
......
{
base::AutoUnlock unlock(lock_);
task->RunOnWorkerThread();
}
......
}这个函数定义在文件external/chromium_org/cc/resources/task_graph_runner.cc中。
前面我们已经分析过TaskGraphRunner类的成员函数RunTaskWithLockAcquired的实现,它主要是执行优先级最高的任务。不过当前我们没有提到,在执行这个优先级最高的任务之前,TaskGraphRunner类的成员函数RunTaskWithLockAcquired又会再次将成员变量as_ready_to_run_taskscv 描述的条件变量被设置为有信号。这样又会有一个光栅化线程被唤醒,用来执行优先级次高的任务。这个过程就一直持续下去,直到所有的任务执行完成为止。
从这里我们就可以看到,在CPU光栅化方式中,分块的光栅化操作是由一组光栅化线程完成的。
至此,我们就对分块的GPU光栅化和CPU光栅化过程都进行了分析。总结来说,分块的光栅化过程包含了以下三个主要的步骤:
1. 根据分块的可见性,将它们划分到不同的Bin中。
2. 根据内存限制策略,从优先级较高的Bin中选集出需要光栅化的分块。
3. 为每一个需要光栅化的分块分配光栅化内存,并且分别为它们创建光栅化任务。
光栅化任务的执行过程又主要分为以下两个步骤:
1. 创建画布。画布以前面分配的光栅化内存为后端存储。
2. 调用画布提供的绘制接口执行以前记录的绘制命令。这些绘制命令就作用在前面分配的光栅化内存中。也就是前面分配的光栅化内存保存了分块的光栅化结果。
当所有标记为Acquired For Activation的分块都光栅化完成之后,就会触发一个ACTION_ACTIVATE_PENDING_TREE操作,也就是将CC Pending Layer Tree激活为CC Active Layer Tree。
在分析CC Pending Layer Tree激活为CC Active Layer Tree的过程之前,我们还会用两篇文章继续深入分析GPU光栅化和CPU光栅化的原理,也就是它们所使用的画布的创建过程。理解这个过程,对GPU光栅化和CPU光栅化的理解就会更深刻。敬请关注!更多的信息也可以关注老罗的新浪微博:http://weibo.com/shengyangluo。