Babel 插件开发与单元测试覆盖度检查
单元测试,对于控制项目代码质量,保障线上版本的安全性和稳定性,节省回归测试成本和降低风险,都有着非常重要的作用。
代码覆盖度(Code coverage) 是衡量单元测试有效程度的一个重要指标。
代码覆盖度也是持续集成质量把控的一个环节。coveralls 是一个非常好的代码覆盖度检查平台,它可以和我们的 github repo 以及 Travis CI 无缝集成在一起。
结合 node-coveralls,有很多 Node.js 工具可以生成并发送代码覆盖度报告(Code coverage report),相关的工具包括 Mocha、Nodeunit、Blanke.js、JSCoverage、Poncho、Lab 等等。
在本文中,我将介绍如何使用 Babel 来开发插件,将 js 原文件编译为可被 Mocha 等工具生成代码覆盖度报告的测试文件。使用这个插件,可以让 coveralls 相关的工具很好地支持对最新的 ES6+ 代码生成代码覆盖度报告。
长文预警:本文内容很长,我先介绍怎样使用相关工具生成代码覆盖度数据,如果对 coveralls、lcov data 已经有所了解,可以跳过这一部分,直接看 Babel 插件的部分。
coveralls 与 lcov data
coveralls 接收一个 lcov data 文件,它用这个文件来计算代码覆盖度。一个 lcov data 文件格式看起来如下:
SF:file1.js
DA:3,1
DA:4,19
DA:5,19
DA:6,19
DA:9,1
……
DA:115,2
DA:118,2
DA:121,1
end_of_record
SF:file2.js
DA:1,1
DA:2,1
……
end_of_record
这个文件格式还是比较简单的, SF: 与 end_of_record 之间表示文件的覆盖数据,格式为: DA:行号,执行次数,例如:DA:5,19 表示代码的第 5 行被执行了 19 次。
有了 lcov data 文件,我们就可以通过 node-coveralls 与 Travis CI 集成,得到代码覆盖率结果。
.travis.yml 大致的内容如下:
language: node_js
node_js:
- "4"
sudo: false
script:
- "npm run test-cov"
after_script: "npm install coveralls && cd test-cov && cat coverage.lcov | ../node_modules/coveralls/bin/coveralls.js && cd .. && rm -rf ./test-cov && rm -rf ./test-app"
如果不知道怎样集成 Travis CI 与 coveralls,可以参考这篇文章。
lcov data 文件
前面说过有很多工具可以配合单元测试工具生成 lcov data 文件。
喜欢用 Mocha 来做单元测试的同学,可以简单用 mocha-lcov-reporter 来生成 lcov data 文件:
安装 mocha 和 mocha-lcov-reporter:
$ npm install mocha --save-dev
$ npm install mocha-lcov-reporter --save-dev
安装一个断言库,我喜欢用 chai:
$ npm install chai --save-dev
写一段 js 文件和测试代码:
//src/person.js
function Person(name){
this.name = name;
}
Person.prototype.greeting = function(){
console.log("hello", this.name);
}
module.exports = Person;
//test/test.js
var Person = require("../src/person");
var chai = require("chai");
describe("test", function(){
var expect = chai.expect;
it("person name", function(){
var akira = new Person("akira");
expect(akira.name).to.equal("akira");
});
});
执行测试:
$ mocha --reporter=mocha-lcov-reporter > coverage.lcov
你会发现,目录下多了一个 coverage.lcov 文件,这是我们需要的代码覆盖度文件,然而,这个文件的内容现在什么也没有。
这是正常的,并不是出了什么错误。因为 Mocha 只负责单元测试,并不会修改和监控 person.js 的原始代码,因此,为了让它正常生成有内容的 coverage.lcov 文件,我们可以对 person.js 文件做"一点"修改:
/*function Person(name){
this.name = name;
}
Person.prototype.greeting = function(){
console.log("hello", this.name);
}
module.exports = Person;*/
global._$jscoverage = global._$jscoverage || {};
_$jscoverage["person.js"] = {};
_$jscoverage["person.js"][1] = 0;
_$jscoverage["person.js"][2] = 0;
_$jscoverage["person.js"][5] = 0;
_$jscoverage["person.js"][6] = 0;
_$jscoverage["person.js"][9] = 0;
_$jscoverage["person.js"].source = [
"",
"function Person(name){",
"this.name = name;",
"}",
"",
"Person.prototype.greeting = function(){",
"console.log("hello", this.name);",
"}",
"",
"module.exports = Person;"
];
_$jscoverage["person.js"][1]++;
function Person(name){
_$jscoverage["person.js"][2]++;
this.name = name;
}
_$jscoverage["person.js"][5]++;
Person.prototype.greeting = function(){
_$jscoverage["person.js"][6]++;
console.log("hello", this.name);
}
_$jscoverage["person.js"][9]++;
module.exports = Person;
上面这个修改看上去有点吓人,只是短短的几行代码的 js 文件要被改成这样,如果内容多一些,靠手工改肯定不行的。不过别担心,这只是示范,这么做确实有效,现在我们可以看到 coverage.lcov 文件中有内容了:
SF:person.js
DA:1,1
DA:2,1
DA:5,1
DA:6,0
DA:9,1
end_of_record
注意 DA:6,0 说明第 6 行代码我们没有测试到,原始文件的第 6 行是:
console.log("hello", this.name);
我们看到它确实没有被测试到,因为它在 .greeting 方法里,而我们根本就没有测试这个方法。好吧,现在我们添加一下测试用例:
var Person = require("../src/person");
var chai = require("chai");
describe("test", function(){
var expect = chai.expect;
it("person name", function(){
var akira = new Person("akira");
expect(akira.name).to.equal("akira");
});
it("greeting", function(){
var akira = new Person("akira");
akira.greeting();
});
});
在上面的代码里,我们添加了一个测试用例,在这个测试用例中,我们只是调用了一下 .greeting( ) 方法,我们现在再测一次:
$ mocha --reporter=mocha-lcov-reporter > coverage.lcov
这次生成的代码覆盖率报告如下:
hello akira
SF:person.js
DA:1,1
DA:2,2
DA:5,1
DA:6,1
DA:9,1
end_of_record
我们看到,除了原始代码的第二行被执行了 2 次,其余各行都被执行了一次。第二行为什么是 2 次呢?因为第二行是:
this.name = name;
这行代码在构造函数内部,由于我们两个 case 分别构造了一个对象,因此这段代码就被执行了 2 次。
用 jscover 生成 lcov data
上面的例子是我们手写的,这么做在实际项目中当然不可行。一般情况下,我们采用一些工具来生成 lcov data,这里用 jscover 作为例子。
我们先来安装 jscover:
$ npm install jscover --save-dev
我们将 person.js 的代码还原成原始版本:
function Person(name){
this.name = name;
}
Person.prototype.greeting = function(){
console.log("hello", this.name);
}
module.exports = Person;
现在我们使用 jscover 来"编译" person.js 代码:
$ node_modules/jscover/bin/jscover src app
这样我们将 src/person.js 编译成了 app/person.js,它看起来像下面这个样子:
//app/person.js
/* ****** automatically generated by jscover - do not edit ******/
if (typeof _$jscoverage === "undefined") { _$jscoverage = {}; }
/* ****** end - do not edit ******/
//...
if (! this._$jscoverage) {
this._$jscoverage = {};
this._$jscoverage.branchData = {};
}
if (! _$jscoverage["person.js"]) {
_$jscoverage["person.js"] = [];
_$jscoverage["person.js"][1] = 0;
_$jscoverage["person.js"][2] = 0;
_$jscoverage["person.js"][5] = 0;
_$jscoverage["person.js"][6] = 0;
_$jscoverage["person.js"][9] = 0;
}
_$jscoverage["person.js"].source = ["function Person(name){"," this.name = name;","}","","Person.prototype.greeting = function(){"," console.log("hello", this.name);","}","","module.exports = Person;"];
_$jscoverage["person.js"][1]++;
function Person(name) {
_$jscoverage["person.js"][2]++;
this.name = name;
}
_$jscoverage["person.js"][5]++;
Person.prototype.greeting = function() {
_$jscoverage["person.js"][6]++;
console.log("hello", this.name);
};
_$jscoverage["person.js"][9]++;
module.exports = Person;
这样,我们就可以同样用 Mocha 来生成 lcov 了,只需要更改模块加载:
var Person = require("../app/person");
得到我们的 lcov data 文件:
hello akira
SF:person.js
DA:1,1
DA:2,2
DA:5,1
DA:6,1
DA:9,1
end_of_record
注意到控制台的输出也进入到 lcov data 文件中来了,这是因为 mocha-lcov-reporter 默认输出到控制台,我们实际上只是把控制台输出完全写到文件中来。在一般情况下,实际项目中不会有 console.log,所以我们可以忽略它。如果需要处理的话,也很简单,我们将文件生成完成之后,把 SF: 与 end_of_record 配对之外的所有的内容删去即可。
使用 ES6 与 Babel
我们现在继续实验,刚才 person.js 采用的是标准的 ES5 写法,我们现在将它改成 ES6 的版本:
"use strcit";
class Person{
constructor(name){
this.name = name;
}
greeting(){
console.log("hello", this.name);
}
}
module.exports = Person;
我们用 Babel 来编译一下:
$ babel --presets es2015 src --out-dir app
然后我们再使用 jscover 来生成代码覆盖报告:
$ node_modules/jscover/bin/jscover app app
$ mocha --reporter=mocha-lcov-reporter > coverage.lcov
hello akira
SF:person.js
DA:1,1
DA:2,1
DA:4,1
DA:6,1
DA:8,1
DA:9,1
DA:10,2
DA:12,2
DA:15,1
DA:18,1
DA:22,1
DA:25,1
end_of_record
麻烦来了,因为我们处理的是 Babel 编译过的代码,因此它不能如实反映出代码原始行号和测试覆盖率。那么我们能不能在 Babel 编译之前先用 jscover 处理它呢?
$ node_modules/jscover/bin/jscover src app
很遗憾,jscover 会报错,因为它不认为 ES6 语法是合法的:
Exception in thread "main" org.mozilla.javascript.EvaluatorException: missing ; before statement (person.js#3)
at org.mozilla.javascript.DefaultErrorReporter.runtimeError(DefaultErrorReporter.java:77)
at org.mozilla.javascript.DefaultErrorReporter.error(DefaultErrorReporter.java:64)
……
那么为了解决这个问题,我们可能得换一个更新的工具来代替 jscover,这个工具需要支持 ES6 语法。但是,我们好像还有一个办法----我们为何不直接使用 Babel?
AST 与 Babel 插件
我们可以直接用 Babel 开发一个插件来编译代码准备生成 lcov data。这么做有以下几个好处:
- 可以与 Babel 的 ES6 编译过程直接合并在一起,不用分两次编译
- lcov data 的数据直接关联原始文件,行号和内容信息不会丢失,覆盖率也能准确计算
- 不用担心语法问题,只要 Babel 能处理的语法都能正常运行,也可以和其他插件组合使用。
抽象语法树(AST)
计算机相关专业的同学应该对语法树的概念并不陌生,对非计算机专业的同学,这里举一个简单的例子稍微解释一下。
考虑表达式 x = (1 + 2) * 3,计算机语言处理的时候将它"展开"成一个树状结构:

上面是一个简单的表达式语法树,注意到它的节点有不同的类型,圆形表示数值常量,圆角矩形表示操作符,菱形表示变量符号。
这就是基本原理,程序的所有的部分都可以表达为树的一部分,AST 更复杂一些,它的树节点类型更多,每个树结构结点中包含更多的信息,但基本结构也大概类似于下面这样:

Babel 与 AST
Babel 6 拥有非常强大的插件 API,通过它,我们可以简单直接地操作文件的 AST。Babel 官方文档给出开发 Babel 插件的简单模板。
export default function ({types: t}) {
return {
visitor: {
Identifier(path) {
let name = path.node.name;
// reverse the name: JavaScript -> tpircSavaJ
path.node.name = name.split("").reverse().join("");
}
}
};
}
更加详细的文档在:babel-handbook (包含中文版)。
设计插件:transform-coverage
现在,我们可以着手来进行插件的设计与开发。在深入进行之前,希望对 AST 和 Babel 插件进一步了解的同学,可以花一点时间浏览一下:Babel 插件手册 以及 babel-types。如果不想深入了解也没关系,因为这个插件并不会用到太复杂的功能。
根据前面我们通过生成 lcov data 所了解的原理,我们的 transform-coverage 需要在代码的每一条_语句之前插入一个形式如 `$jscoverage[文件名][行号]++的**计数代码**。同时,我们需要在代码文件的最前面加上_$jscoverage` 初始化的相关代码。
所以,我们可以来设计插件的基本结构:
module.exports = function(babel) {
var t = babel.types;
var covVisitor = {
Statement: {
exit: function(path){
//插入计数代码到每一条语句(Statement)前面
}
},
Program: {
enter: function(path, state){
//初始化
},
exit: function(path, state){
//添加代码到文件最前面
}
}
};
return {visitor: covVisitor};
};
以上就是插件的基本逻辑结构,这里只用到 Statement 和 Program 两个 visitor,它们分别表示程序的语句节点和根节点。
这里解释一下 Babel 插件的 visitor 机制,每一个 visitor 属性对应一个 AST 节点类型,我们可以认为 Babel 插件遍历当前 AST 上每一个对应类型的节点(这有点像是 CSS 选择器,可以这么理解),因此:
Statement: {
exit: function(){
}
}
后序遍历当前 AST 中每一个类型为 Statement 的节点。
这里需要注意每一类节点可以有 enter 和 exit 两个遍历时机,分别对应前序遍历和后续遍历,前序遍历指的是当程序进入这个节点的时候对节点做处理,后续遍历则是当程序退出这个节点的时候对节点做处理。前序和后续两种方式,在节点有嵌套的时候会影响到节点处理的顺序:
if(a > 0){
b++;
return;
}
产生的 AST:
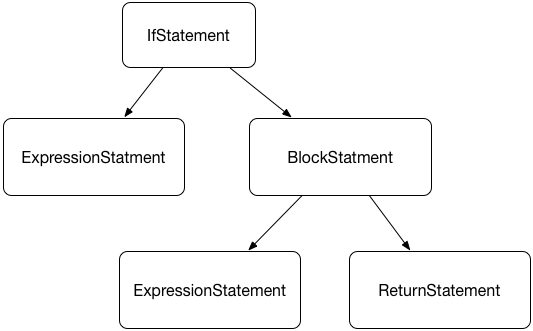
{
Statement:{
enter: function(path){
console.log(path.node.type);
}
}
}
前序遍历依次输出:IfStatement、ExpressionStatement、BlockStatment、ExpressionStatement、ReturnStatement
{
Statement:{
exit: function(path){
console.log(path.node.type);
}
}
}
后续遍历依次输出:ExpressionStatement、ExpressionStatement、ReturnStatement、BlockStatement、IfStatement
Program 是一个文件的 AST 的根节点,我们在 Program 的 enter 中完成一些内容的初始化,比如拿到当前的文件名(插入检查覆盖的代码的时候要用),初始化一个 Set,用来收集每个 Statement 所在的行号:
module.exports = function(babel) {
var t = babel.types,
coverageSet,
filename;
var covVisitor = {
Statement: {
exit: function(path){
//插入计数代码到每一条语句(Statement)前面
}
},
Program: {
enter: function(path, state){
//初始化
filename = state.file.opts.filename.replace(/^[^\/]*\//,"");
coverageSet = new Set();
},
exit: function(path, state){
//添加代码到文件最前面
}
}
};
return {visitor: covVisitor};
};
文件名 filename 可以通过 state.file.opts.filename 拿到,这个 filename 生成计数语句的时候要用到。需要注意的是我们要把 filename 最外层的目录去除(那一层目录在编译的时候改变了),以使得文件相对路径正确。
这里的 coverageSet 为什么用 Set 而不用一个 Array 是因为与 jscover 一致,我们仅为一行生成一个计数代码,如果该行有多个语句,我们应该忽略多余的语句,在这里使用 Set 判断起来更加高效率。我们看一下具体的 Statement 实现:
处理 Statement
Statement: {
exit: function(path){
//插入计数代码到每一条语句(Statement)前面
var loc = path.node.loc;
//不用处理 BlockStatement
if(loc && path.node.type !== "BlockStatement"){
var line = loc.start.line;
//有行号的代码、并且当前行没有被处理过
if(line && !coverageSet.has(line)){
//构造计数语句
var node = t.expressionStatement(t.updateExpression(
"++",
t.memberExpression(
t.memberExpression(
t.identifier(jscover),
t.stringLiteral(filename), true
),
t.numericLiteral(line), true
)
));
//记录当前处理的行号
coverageSet.add(line);
//将计数语句插入到当前节点的前面
path.insertBefore(node);
}
}
}
}
以上代码比较简单,最主要的内容是构造计数语句和将语句插入到当前节点之前。
构造计数语句是通过 babel-types 的方法进行的,这里没有什么特别有难度的东西,唯一需要注意的是注意它们的嵌套结构,写起来略微繁琐一些而已。
插入计数语句更简单了,path.insertBefore(node) 即可。
处理前置的代码
最后我们需要创建前面初始化 _$jscoverage 的代码,这里有几个步骤要做。我们将它放在 Program 的 exit 中,因为我们需要先拿到 coverageSet,知道有多少行代码被我们处理并添加了计数,我们要初始化这些计数器:
Program: {
enter: function(path, state){
//filename = state.file.opts.sourceFileName;
filename = state.file.opts.filename.replace(/^[^\/]*\//,"");
coverageSet = new Set();
},
exit: function(path, state){
……
//获得代码中的第一条语句
var body = path.get("body")[0];
//如果代码为空的,不做处理,返回
if(!body) return;
……
//初始化每个计数器
var lines = Array.from(coverageSet).sort((a,b)=>a-b);
for(var i = 0; i < lines.length; i++){
var node = t.expressionStatement(t.assignmentExpression(
"=",
t.memberExpression(
t.memberExpression(
t.identifier(jscover),
t.stringLiteral(filename),
true
),
t.numericLiteral(lines[i]),
true
),
t.numericLiteral(0)
));
body.insertBefore(node);
}
……
}
}
剩下的代码包括初始化 _$jscoverage、_$jscoverage[filename] 以及 _$jscoverage[filename].source:
Program: {
enter: function(path, state){
//filename = state.file.opts.sourceFileName;
filename = state.file.opts.filename.replace(/^[^\/]*\//,"");
coverageSet = new Set();
},
exit: function(path, state){
//获得代码中的第一条语句
var body = path.get("body")[0];
//如果代码为空的,不做处理,返回
if(!body) return;
//初始化 _$jscoverage
var node = t.expressionStatement(t.assignmentExpression(
"=",
t.memberExpression(
t.identifier("global"),
t.identifier(jscover)
),
t.logicalExpression(
"||",
t.memberExpression(
t.identifier("global"),
t.identifier(jscover)
),
t.objectExpression([])
)
));
body.insertBefore(node);
//初始化计数器列表
var node = t.expressionStatement(t.assignmentExpression(
"=",
t.memberExpression(
t.identifier(jscover),
t.stringLiteral(filename),
true
),
t.arrayExpression([])
));
body.insertBefore(node);
//初始化每个计数器
var lines = Array.from(coverageSet).sort((a,b)=>a-b);
for(var i = 0; i < lines.length; i++){
var node = t.expressionStatement(t.assignmentExpression(
"=",
t.memberExpression(
t.memberExpression(
t.identifier(jscover),
t.stringLiteral(filename),
true
),
t.numericLiteral(lines[i]),
true
),
t.numericLiteral(0)
));
body.insertBefore(node);
}
//初始化 _$jscoverage[filename].source
var codeList = state.file.code.split(/\n/g);
for(var i = 0; i < codeList.length; i++){
codeList[i] = t.stringLiteral(codeList[i] || "");
}
var node = t.expressionStatement(t.assignmentExpression(
"=",
t.memberExpression(
t.memberExpression(
t.identifier(jscover),
t.stringLiteral(filename),
true
),
t.identifier("source")
),
t.arrayExpression(codeList)
));
body.insertBefore(node);
}
}
最终,这个 Babel 插件的全部代码如下:
module.exports = function(babel) {
var t = babel.types,
coverageSet,
filename;
const jscover = "_$jscoverage";
var covVisitor = {
Statement: {
exit: function(path){
//insert `_$jscoverage[{filename}][{line}]++` before each statement
var loc = path.node.loc;
//ignore BlockStatement
if(loc && path.node.type !== "BlockStatement"){
var line = loc.start.line;
if(line && !coverageSet.has(line)){
var node = t.expressionStatement(t.updateExpression(
"++",
t.memberExpression(
t.memberExpression(
t.identifier(jscover),
t.stringLiteral(filename), true
),
t.numericLiteral(line), true
)
));
coverageSet.add(line);
path.insertBefore(node);
//path.traverse(covVisitor);
}
}
}
},
Program: {
enter: function(path, state){
//filename = state.file.opts.sourceFileName;
filename = state.file.opts.filename.replace(/^[^\/]*\//,"");
coverageSet = new Set();
},
exit: function(path, state){
var body = path.get("body")[0];
//exit if file is empty
if(!body) return;
//global._$jscoverage = global._$jscoverage || {}
var node = t.expressionStatement(t.assignmentExpression(
"=",
t.memberExpression(
t.identifier("global"),
t.identifier(jscover)
),
t.logicalExpression(
"||",
t.memberExpression(
t.identifier("global"),
t.identifier(jscover)
),
t.objectExpression([])
)
));
body.insertBefore(node);
//_$jscoverage[{$filename}] = [];
var node = t.expressionStatement(t.assignmentExpression(
"=",
t.memberExpression(
t.identifier(jscover),
t.stringLiteral(filename),
true
),
t.arrayExpression([])
));
body.insertBefore(node);
/**
_$jscoverage[{$filename}][{$line}] = 0;
...
*/
var lines = Array.from(coverageSet).sort((a,b)=>a-b);
for(var i = 0; i < lines.length; i++){
var node = t.expressionStatement(t.assignmentExpression(
"=",
t.memberExpression(
t.memberExpression(
t.identifier(jscover),
t.stringLiteral(filename),
true
),
t.numericLiteral(lines[i]),
true
),
t.numericLiteral(0)
));
body.insertBefore(node);
}
//_$jscoverage[{$filename}].source = [...codes]
var codeList = state.file.code.split(/\n/g);
for(var i = 0; i < codeList.length; i++){
codeList[i] = t.stringLiteral(codeList[i] || "");
}
var node = t.expressionStatement(t.assignmentExpression(
"=",
t.memberExpression(
t.memberExpression(
t.identifier(jscover),
t.stringLiteral(filename),
true
),
t.identifier("source")
),
t.arrayExpression(codeList)
));
body.insertBefore(node);
}
}
};
return {visitor: covVisitor};
};
如何使用
我将插件发布到 npm 上,你可以安装然后通过 babel 命令来使用:
安装 babel-cli 和 插件
$ npm install babel-cli --save-dev
$ npm install babel-preset-es2015 --save-dev
$ npm install babel-plugin-transform-coverage --save-dev
运行插件:
$ babel --presets es2015 --plugins transform-coverage src --out-dir app
以上代码将 ES6 编译成 ES5 并添加代码覆盖计数。
mocha --reporter=mocha-lcov-reporter > coverage.lcov
生成代码覆盖率报告:
hello akira
SF:person.js
DA:4,1
DA:5,2
DA:8,1
DA:12,1
end_of_record
结论
由于 jscover 不支持生成 ES6 的代码覆盖计数,我写了一个插件 babel-plugin-transform-coverage(GitHub 仓库地址),用它可以在编译 ES6 代码的同时生成需要的 lcov 代码覆盖计数。我们可以将它用在项目的测试脚本中:

关于代码覆盖率和开发 Babel 插件有任何问题,欢迎讨论。