Python爬虫框架Scrapy实战之批量抓取招聘信息
网络爬虫抓取特定网站网页的html数据,但是一个网站有上千上万条数据,我们不可能知道网站网页的url地址,所以,要有个技巧去抓取网站的所有html页面。Scrapy是纯Python实现的爬虫框架,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非常之方便~
Scrapy 使用wisted这个异步网络库来处理网络通讯,架构清晰,并且包含了各种中间件接口,可以灵活的完成各种需求。整体架构如下图所示:
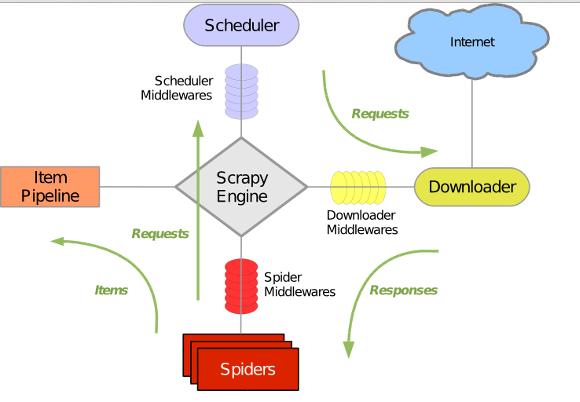
绿线是数据流向,首先从初始URL 开始,**Scheduler **会将其交给 Downloader 进行下载,下载之后会交给 Spider 进行分析,Spider分析出来的结果有两种:一种是需要进一步抓取的链接,例如之前分析的"下一页"的链接,这些东西会被传回 Scheduler ;另一种是需要保存的数据,它们则被送到Item Pipeline 那里,那是对数据进行后期处理(详细分析、过滤、存储等)的地方。另外,在数据流动的通道里还可以安装各种中间件,进行必要的处理。我假定你已经安装了Scrapy。假如你没有安装,你可以参考这篇文章。
在本文中,我们将学会如何使用Scrapy建立一个爬虫程序,并爬取指定网站上的内容
1. 创建一个新的Scrapy Project
2. 定义你需要从网页中提取的元素Item
3.实现一个Spider类,通过接口完成爬取URL和提取Item的功能
4. 实现一个Item PipeLine类,完成Item的存储功能
我将会用腾讯招聘官网作为例子。
Github源码:https://github.com/maxliaops/scrapy-itzhaopin
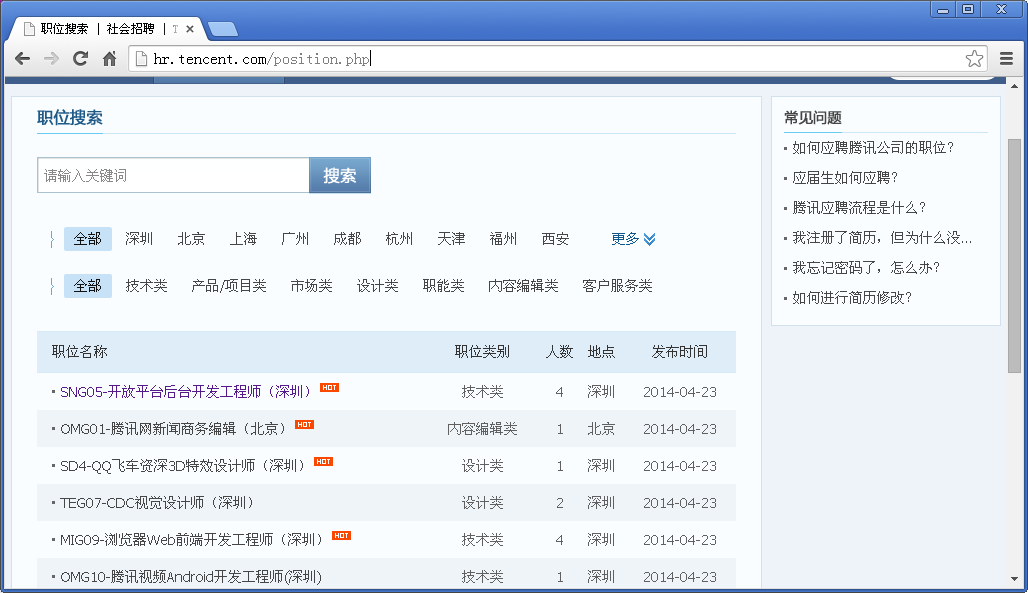
目标:抓取腾讯招聘官网职位招聘信息并保存为JSON格式。
新建工程
首先,为我们的爬虫新建一个工程,首先进入一个目录(任意一个我们用来保存代码的目录),执行:
复制代码 代码如下:
scrapy startprojectitzhaopin
最后的itzhaopin就是项目名称。这个命令会在当前目录下创建一个新目录itzhaopin,结构如下:
├── itzhaopin
│ ├── itzhaopin
│ │ ├── init.py
│ │ ├── items.py
│ │ ├── pipelines.py
│ │ ├── settings.py
│ │ └── spiders
│ │ └── init.py
│ └── scrapy.cfg
scrapy.cfg: 项目配置文件
items.py: 需要提取的数据结构定义文件
pipelines.py:管道定义,用来对items里面提取的数据做进一步处理,如保存等
settings.py: 爬虫配置文件
spiders: 放置spider的目录
定义Item
在items.py里面定义我们要抓取的数据:
from scrapy.item import Item, Field
class TencentItem(Item):
name = Field() # 职位名称
catalog = Field() # 职位类别
workLocation = Field() # 工作地点
recruitNumber = Field() # 招聘人数
detailLink = Field() # 职位详情页链接
publishTime = Field() # 发布时间
实现Spider
Spider是一个继承自scrapy.contrib.spiders.CrawlSpider的Python类,有三个必需的定义的成员
name: 名字,这个spider的标识
start_urls:一个url列表,spider从这些网页开始抓取
parse():一个方法,当start_urls里面的网页抓取下来之后需要调用这个方法解析网页内容,同时需要返回下一个需要抓取的网页,或者返回items列表
所以在spiders目录下新建一个spider,tencent_spider.py:
import re
import json
from scrapy.selector import Selector
try:
from scrapy.spider import Spider
except:
from scrapy.spider import BaseSpider as Spider
from scrapy.utils.response import get_base_url
from scrapy.utils.url import urljoin_rfc
from scrapy.contrib.spiders import CrawlSpider, Rule
from scrapy.contrib.linkextractors.sgml import SgmlLinkExtractor as sle
from itzhaopin.items import *
from itzhaopin.misc.log import *
class TencentSpider(CrawlSpider):
name = "tencent"
allowed_domains = ["tencent.com"]
start_urls = [
"http://hr.tencent.com/position.php"
]
rules = [ # 定义爬取URL的规则
Rule(sle(allow=("/position.php\?&start;=\d{,4}#a")), follow=True, callback='parse_item')
]
def parse_item(self, response): # 提取数据到Items里面,主要用到XPath和CSS选择器提取网页数据
items = []
sel = Selector(response)
base_url = get_base_url(response)
sites_even = sel.css('table.tablelist tr.even')
for site in sites_even:
item = TencentItem()
item['name'] = site.css('.l.square a').xpath('text()').extract()
relative_url = site.css('.l.square a').xpath('@href').extract()[0]
item['detailLink'] = urljoin_rfc(base_url, relative_url)
item['catalog'] = site.css('tr > td:nth-child(2)::text').extract()
item['workLocation'] = site.css('tr > td:nth-child(4)::text').extract()
item['recruitNumber'] = site.css('tr > td:nth-child(3)::text').extract()
item['publishTime'] = site.css('tr > td:nth-child(5)::text').extract()
items.append(item)
#print repr(item).decode("unicode-escape") + '\n'
sites_odd = sel.css('table.tablelist tr.odd')
for site in sites_odd:
item = TencentItem()
item['name'] = site.css('.l.square a').xpath('text()').extract()
relative_url = site.css('.l.square a').xpath('@href').extract()[0]
item['detailLink'] = urljoin_rfc(base_url, relative_url)
item['catalog'] = site.css('tr > td:nth-child(2)::text').extract()
item['workLocation'] = site.css('tr > td:nth-child(4)::text').extract()
item['recruitNumber'] = site.css('tr > td:nth-child(3)::text').extract()
item['publishTime'] = site.css('tr > td:nth-child(5)::text').extract()
items.append(item)
#print repr(item).decode("unicode-escape") + '\n'
info('parsed ' + str(response))
return items
def _process_request(self, request):
info('process ' + str(request))
return request
实现PipeLine
PipeLine用来对Spider返回的Item列表进行保存操作,可以写入到文件、或者数据库等。
PipeLine只有一个需要实现的方法:process_item,例如我们将Item保存到JSON格式文件中:
pipelines.py
from scrapy import signals
import json
import codecs
class JsonWithEncodingTencentPipeline(object):
def __init__(self):
self.file = codecs.open('tencent.json', 'w', encoding='utf-8')
def process_item(self, item, spider):
line = json.dumps(dict(item), ensure_ascii=False) + "\n"
self.file.write(line)
return item
def spider_closed(self, spider):
self.file.close(
)
到现在,我们就完成了一个基本的爬虫的实现,可以输入下面的命令来启动这个Spider
scrapy crawl tencent
爬虫运行结束后,在当前目录下将会生成一个名为tencent.json的文件,其中以JSON格式保存了职位招聘信息。
部分内容如下:
{"recruitNumber": ["1"], "name": ["SD5-资深手游策划(深圳)"], "detailLink": "http://hr.tencent.com/position_detail.php?id=15626&keywords;=&tid;=0&lid;=0", "publishTime":
["2014-04-25"], "catalog": ["产品/项目类"], "workLocation": ["深圳"]}
{"recruitNumber": ["1"], "name": ["TEG13-后台开发工程师(深圳)"], "detailLink": "http://hr.tencent.com/position_detail.php?id=15666&keywords;=&tid;=0&lid;=0",
"publishTime": ["2014-04-25"], "catalog": ["技术类"], "workLocation": ["深圳"]}
{"recruitNumber": ["2"], "name": ["TEG12-数据中心高级经理(深圳)"], "detailLink": "http://hr.tencent.com/position_detail.php?id=15698&keywords;=&tid;=0&lid;=0",
"publishTime": ["2014-04-25"], "catalog": ["技术类"], "workLocation": ["深圳"]}
{"recruitNumber": ["1"], "name": ["GY1-微信支付品牌策划经理(深圳)"], "detailLink": "http://hr.tencent.com/position_detail.php?id=15710&keywords;=&tid;=0&lid;=0",
"publishTime": ["2014-04-25"], "catalog": ["市场类"], "workLocation": ["深圳"]}
{"recruitNumber": ["2"], "name": ["SNG06-后台开发工程师(深圳)"], "detailLink": "http://hr.tencent.com/position_detail.php?id=15499&keywords;=&tid;=0&lid;=0",
"publishTime": ["2014-04-25"], "catalog": ["技术类"], "workLocation": ["深圳"]}
{"recruitNumber": ["2"], "name": ["OMG01-腾讯时尚视频策划编辑(北京)"], "detailLink": "http://hr.tencent.com/position_detail.php?id=15694&keywords;=&tid;=0&lid;=0",
"publishTime": ["2014-04-25"], "catalog": ["内容编辑类"], "workLocation": ["北京"]}
{"recruitNumber": ["1"], "name": ["HY08-QT客户端Windows开发工程师(深圳)"], "detailLink": "http://hr.tencent.com/position_detail.php?id=11378&keywords;=&tid;=0&lid;=0",
"publishTime": ["2014-04-25"], "catalog": ["技术类"], "workLocation": ["深圳"]}
{"recruitNumber": ["5"], "name": ["HY1-移动游戏测试经理(上海)"], "detailLink": "http://hr.tencent.com/position_detail.php?id=15607&keywords;=&tid;=0&lid;=0", "publishTime": ["2014-04-25"], "catalog": ["技术类"], "workLocation": ["上海"]}
{"recruitNumber": ["1"], "name": ["HY6-网吧平台高级产品经理(深圳)"], "detailLink": "http://hr.tencent.com/position_detail.php?id=10974&keywords;=&tid;=0&lid;=0", "publishTime": ["2014-04-25"], "catalog": ["产品/项目类"], "workLocation": ["深圳"]}
{"recruitNumber": ["4"], "name": ["TEG14-云存储研发工程师(深圳)"], "detailLink": "http://hr.tencent.com/position_detail.php?id=15168&keywords;=&tid;=0&lid;=0", "publishTime": ["2014-04-24"], "catalog": ["技术类"], "workLocation": ["深圳"]}
{"recruitNumber": ["1"], "name": ["CB-薪酬经理(深圳)"], "detailLink": "http://hr.tencent.com/position_detail.php?id=2309&keywords;=&tid;=0&lid;=0", "publishTime": ["2013-11-28"], "catalog": ["职能类"], "workLocation": ["深圳"]}
以上全部内容就是通过Python爬虫框架Scrapy实战之批量抓取招聘信息的全部内容,希望对大家有所帮助,欲了解更多编程知识,请锁定我们的网站,每天都有新的内容发布。