Python爬取APP下载链接的实现方法
首先是准备工作
Python 2.7.11:下载python
Pycharm:下载Pycharm
其中python2和python3目前同步发行,我这里使用的是python2作为环境。Pycharm是一款比较高效的Python IDE,但是需要付费。
实现的基本思路
首先我们的目标网站:安卓市场
点击【应用】,进入我们的关键页面:

跳转到应用界面后我们需要关注三个地方,下图红色方框标出:
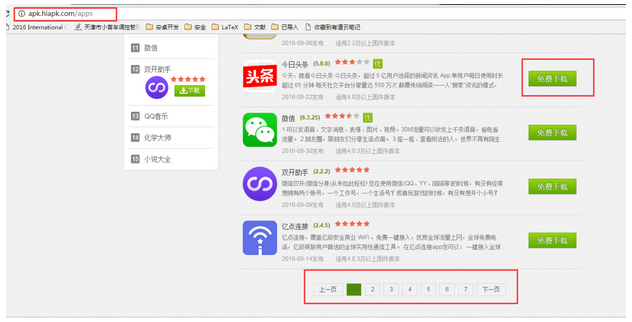
首先关注地址栏的URL,再关注免费下载按钮,然后关注底端的翻页选项。点击"免费下载"按钮就会立即下载相应的APP,所以我们的思路就是拿到这个点击下载的连接,就可以直接下载APP了。
编写爬虫
第一个需要解决的点:我们怎么拿到上面说的下载链接?这里不得不介绍下浏览器展示网页的基本原理。说简单点,浏览器是一个类似解析器的工具,它得到HTML等代码的时候会按照相应的规则解析渲染,从而我们能够看到页面。
这里我使用的是谷歌浏览器,对着页面右键,点击"检查",可以看到网页原本的HTML代码:

看到眼花缭乱的HTML代码不用着急,谷歌浏览器的审查元素有一个好用的小功能,可以帮我们定位页面控件对应的HTML代码
位置:

如上图所示,点击上方矩形框中的小箭头,点击页面对应的位置,在右边的HTML代码中就会自动定位并高亮。
接下来我们定位到下载按钮对应的HTML代码:
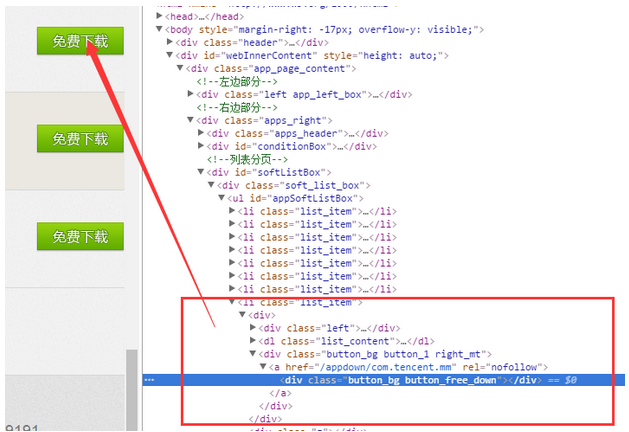
可以看到按钮对应的代码中,存在相应的下载链接:【/appdown/com.tecent.mm】,加上前缀,完整的下载链接就是 http://apk.hiapk.com/appdown/com.tecent.mm
首先使用python拿到整个页面的HTML,很简单,使用"requests.get(url)" ,url填入相应网址即可。

接着,在抓取页面关键信息的时候,采取"先抓大、再抓小"的思路。可以看到一个页面有10个APP,在HTML代码中对应10个item:

而每个 li 标签中,又包含各自APP的各个属性(名称、下载链接等)。所以第一步,我们将这10个 li 标签提取出来:
def geteveryapp(self,source):
everyapp = re.findall('(<li class="list_item".*?</li>)',source,re.S)
#everyapp2 = re.findall('(<div class="button_bg button_1 right_mt">.*?</div>)',everyapp,re.S)
return everyapp这里用到了简单的正则表达式知识
提取 li 标签中的下载链接:
def getinfo(self,eachclass):
info = {}
str1 = str(re.search('<a href="(.*?)">', eachclass).group(0))
app_url = re.search('"(.*?)"', str1).group(1)
appdown_url = app_url.replace('appinfo', 'appdown')
info['app_url'] = appdown_url
print appdown_url
return info接下来需要说的难点是翻页,点击下方的翻页按钮后我们可以看到地址栏发生了如下变化:


豁然开朗,我们可以在每次的请求中替换URL中对应的id值实现翻页。
def changepage(self,url,total_page):
now_page = int(re.search('pi=(\d)', url).group(1))
page_group = []
for i in range(now_page,total_page+1):
link = re.sub('pi=\d','pi=%s'%i,url,re.S)
page_group.append(link)
return page_group爬虫效果
关键位置说完了,我们先看下最后爬虫的效果:

在TXT文件中保存结果如下:

直接复制进迅雷就可以批量高速下载了。
附上全部代码
#-*_coding:utf8-*-
import requests
import re
import sys
reload(sys)
sys.setdefaultencoding("utf-8")
class spider(object):
def __init__(self):
print u'开始爬取内容'
def getsource(self,url):
html = requests.get(url)
return html.text
def changepage(self,url,total_page):
now_page = int(re.search('pi=(\d)', url).group(1))
page_group = []
for i in range(now_page,total_page+1):
link = re.sub('pi=\d','pi=%s'%i,url,re.S)
page_group.append(link)
return page_group
def geteveryapp(self,source):
everyapp = re.findall('(<li class="list_item".*?</li>)',source,re.S)
return everyapp
def getinfo(self,eachclass):
info = {}
str1 = str(re.search('<a href="(.*?)">', eachclass).group(0))
app_url = re.search('"(.*?)"', str1).group(1)
appdown_url = app_url.replace('appinfo', 'appdown')
info['app_url'] = appdown_url
print appdown_url
return info
def saveinfo(self,classinfo):
f = open('info.txt','a')
str2 = "http://apk.hiapk.com"
for each in classinfo:
f.write(str2)
f.writelines(each['app_url'] + '\n')
f.close()
if __name__ == '__main__':
appinfo = []
url = 'http://apk.hiapk.com/apps/MediaAndVideo?sort=5π=1'
appurl = spider()
all_links = appurl.changepage(url, 5)
for link in all_links:
print u'正在处理页面' + link
html = appurl.getsource(link)
every_app = appurl.geteveryapp(html)
for each in every_app:
info = appurl.getinfo(each)
appinfo.append(info)
appurl.saveinfo(appinfo)总结
选取的目标网页相对结构清晰简单,这是一个比较基本的爬虫。代码写的比较乱请见谅,以上就是这篇文章的全部内容了,希望能对大家的学习或者工作带来一定的帮助,如果有问题大家可以留言交流。