python中正则的使用指南
上一次很多朋友写文字屏蔽说到要用正则表达,其实不是我不想用(我正则用得不是很多,看过我之前爬虫的都知道,我直接用BeautifulSoup的网页标签去找内容,因为容易理解也方便,),而是正则用好用精通的很难(看过正则表的应该都知道,里面符号对应的方法规则有很多,很灵活),对于接触编程不久的朋友们来说很可能在编程的过程上浪费很多时间,今天我把经常会用到正则简单介绍下,如果不是很特殊基本都覆盖使用。
1.正则的简单介绍
首先你得导入正则方法 import re正则表达式是用于处理字符串的强大工具,拥有自己独立的处理机制,效率上可能不如str自带的方法,但功能十分灵活给力。它的运行过程是先定一个匹配规则("你想要的内容+正则语法规则"),放入要匹配的字符串,通过正则内部的机制就能检索你想要的信息。
2.findall的常用几种姿势
基本结构大致: nojoke = re.findall(r'匹配的规则','要检索的愿字符串') nojoke就是我们最后通过正则返回的结果,re正则findall查找全部r标识代表后面是正则的语句(这样在代码多的时候好查阅),下面我们看看几个例子好深入了解
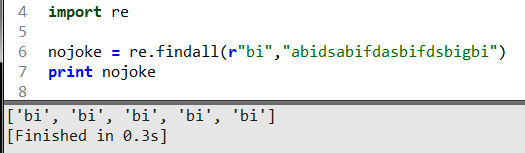
这段代码是找出检索字符串中所有的bi并以列表的形式返回,这个会经常用到计算统一字符出现的次数。继续看下一个

这里加了个符号^表示匹配以abi开头的的字符串返回,也可以判断字符串是否以abi开始的。

这里在的用$符号表示以gbi结尾的字符串返回,判断是否字符串结束的字符串。

这里[...]的意思匹配括号内a和f,或者b和f,或者c和f的值返回列表。

"\d"是正则语法规则用来匹配0到9之间的数返回列表,需要注意的是11会当成字符串'1'和'1'返回而不是返回'11'这个字符串,切记用不好这里是大坑。

当然解决的办法就你要取几位数就写几个\d,上面这里演示取字符串中3位数字,这里展现了正则灵活一方面。

这里小d表示取数字0-9,大D表示不要数字,也就是出了数字以外的内容返回。

"\w"在正则里面代表匹配从小写a到z,大写A到Z,数字0到9包含前面这三种的如上面打印的一样.

"\W"在正则里面代表匹配除了字母与数字以外的特殊符号,但这里\斜杠的用法要注意在字符串\是转义符号具体百度去学。
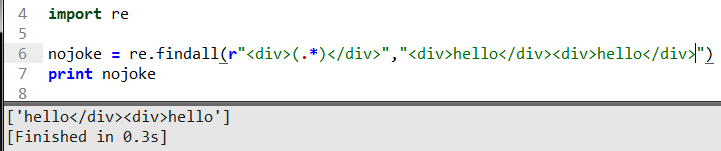
这里括号()的用法表示匹配是取括号内里面的内容,这里.*是正则贪婪匹配语法百话点就是贪心利益最大话最大范围的匹配准则如上图所示。

这里加了个问号.*?就是限制它不让他最大范围的匹配也叫非贪婪模式匹配。结果是把两个div内的内容匹配返回。

这里加re.I(大写的i)表示匹配无论公的母的大小写都通吃都要,不然后面有大小写就会出现上面匹配找不到返回空列表给你。

这里又搞事了就是\n俗称换行符,一旦换行程序就SB了不认了,所以我们加上了re.S(大写)这样代表比匹配包括换行在内的所有字符内容返回,基本你把上面的语法和用法学会后基本70%以上匹配方法全都搞定,当然还有很方法我就不列举了,大家可以自己去学习(剩下的基本我都很少用到了)。
2.match和search的用法及区别:
re.match 尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match()就返回none。re.search 扫描整个字符串并返回第一个成功的匹配。来看看代码就容易理解了。如下:

这里直接打印结尾加上.span()可以得到匹配字符串的位置以元组tuple返回(起始位置,结束位置),有一个没写,因为他返回空加上会编译器报错。

是不是一目了然,match只会开头匹配,找不到就返回None,这里我没加.group()是因为返回值是空值我加了编译器会报错,search不挑食扫描整个字符串,当然里面也可以用上面的正则方法去匹配,这里就不过多介绍了大家可以动手练练。
3.sub替换的用法
sub用于替换字符串中的匹配项,语法一般是re.sub(r'正则匹配规则','替换的字符串',需要检索的字符串)

这里很直观的反应了结果,把#号及后面的字符串替换想要改的字符串。
4.最后福利
在给最后福利之前,希望大家能多练练上面的用法和使用规则,只有多出错多总结才会积累经验,最后的福利讲给大家几个常用的邮箱匹配规则如下:

必杀技能最后送了合体多种匹配或者发|用来匹配多个不同的邮箱使用,大家只要用熟以上的方法保守70%以上的地方都能够使用到,最后声明只是小弟个人理解分享,大佬们忽略就忽略吧,谢谢,最后还还是老台词:感谢观看,下次再见!