Python实现的下载网页源码功能示例
本文实例讲述了Python实现的下载网页源码功能。分享给大家供大家参考,具体如下:
#!/usr/bin/python
import httplib
httpconn = httplib.HTTPConnection("www.baidu.com")
httpconn.request("GET", "/index.html")
resp = httpconn.getresponse()
if resp.reason == "OK":
resp_data = resp.read()
print resp_data
print len(resp_data)
httpconn.close()
要下载的网页源码被读取到了resp_data中了
运行效果图如下:
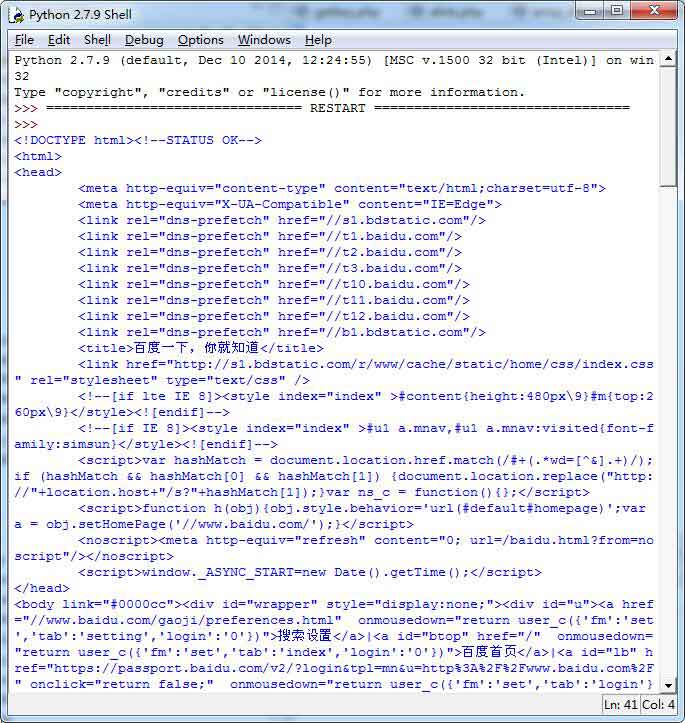
更多关于Python相关内容感兴趣的读者可查看本站专题:《Python进程与线程操作技巧总结》、《Python Socket编程技巧总结》、《Python数据结构与算法教程》、《Python函数使用技巧总结》、《Python字符串操作技巧汇总》、《Python入门与进阶经典教程》及《Python文件与目录操作技巧汇总》
希望本文所述对大家Python程序设计有所帮助。