Python处理JSON数据并生成条形图
一、JSON 数据准备
首先准备一份 JSON 数据,这份数据共有 3560 条内容,每条内容结构如下:

本示例主要是以 tz(timezone 时区) 这一字段的值,分析这份数据里时区的分布情况。
二、将 JSON 数据转换成 Python 字典
代码如下:

三、统计 tz 值分布情况,以"时区:总数"的形式生成统计结果
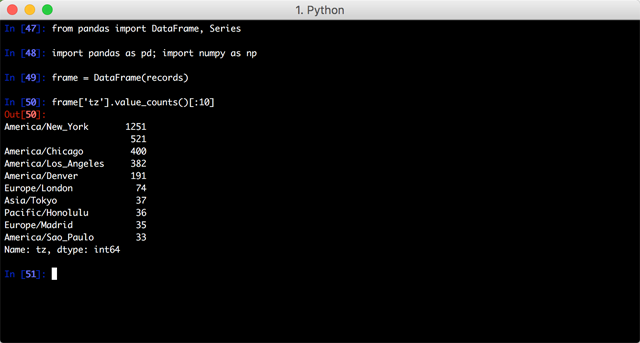
要想达到这一目的,需要先将 records 转换成 DataFrame,DataFrame 是 Pandas 里最重要的数据结构,它可以将数据以表格的形式表示;然后用 value_counts()方法汇总:
四、根据统计结果生成条形图
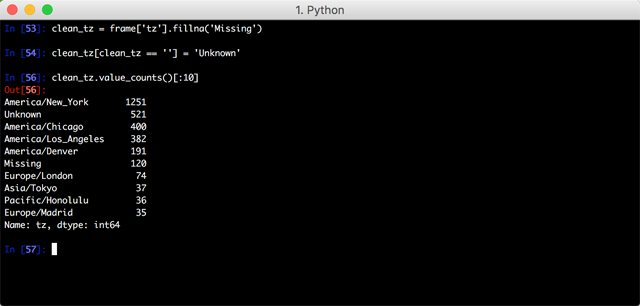
生成条形图之前,为了数据的完整,可以给结果中缺失的时区添加一个值(这里用Missing表示),而每条时区内容里缺失的值也需要添加一个未知的值(这里用Unknown表示):
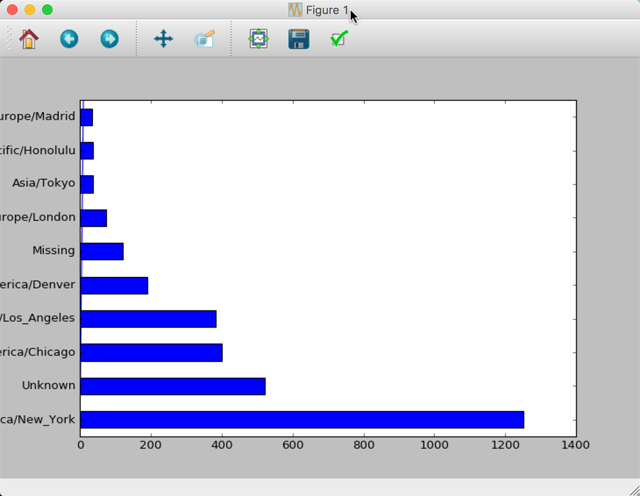
然后使用 plot()方法既可生成条形图:
到这里就是一个完整的处理 JSON 数据生成统计结果和条形图的例子;不过还可以对这份统计结果进行进一步的处理,以得到更加详细的结果。
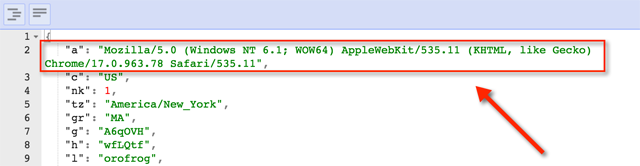
每条数据里还有一个 agent 值,即浏览器的 USER_AGENT 信息,通过这一信息可以得知所使用的操作系统,所以对上一步生成的统计结果还可以按操作系统的不同加以区分。
agent 值:
五、将条形图以操作系统(Windows/非Windows)加以区分
不是所有的数据都有 a 这个字段,首先过滤掉没有 agent 值的数据; 然后根据时区和操作系统列表对数据分组,然后 对分组结果进行计数:
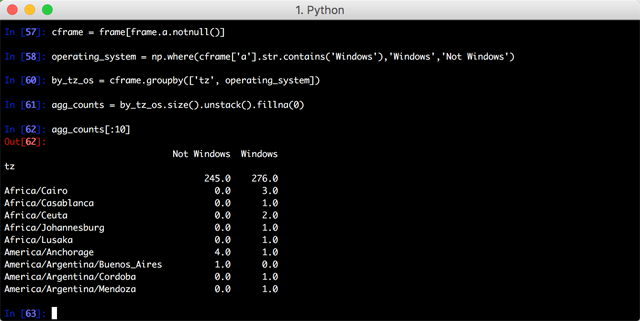
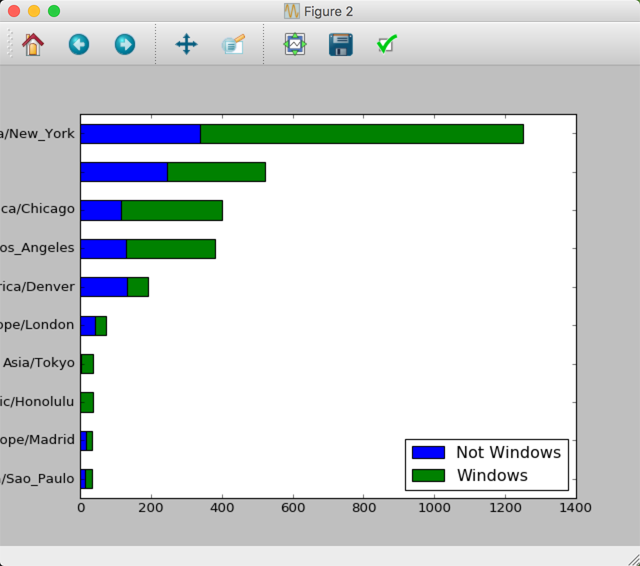
最后选择出现次数最多的10个时区的数据 生成一张条形图:

这样就得到了以不同操作系统加以区分的条形图统计结果:
以上就是Python处理JSON数据并生成条形图的全部内容,希望本文对大家学习Python和JSON都能有所帮助。