Python中使用urllib2模块编写爬虫的简单上手示例
提起python做网络爬虫就不得不说到强大的组件urllib2。在python中正是使用urllib2这个组件来抓取网页的。urllib2是Python的一个获取URLs(Uniform Resource Locators)的组件。它以urlopen函数的形式提供了一个非常简单的接口。通过下面的代码简单感受一下urllib2的功能;
import urllib2
response = urllib2.urlopen('http://www.baidu.com/')
html = response.read()
print html
运行结果如下;
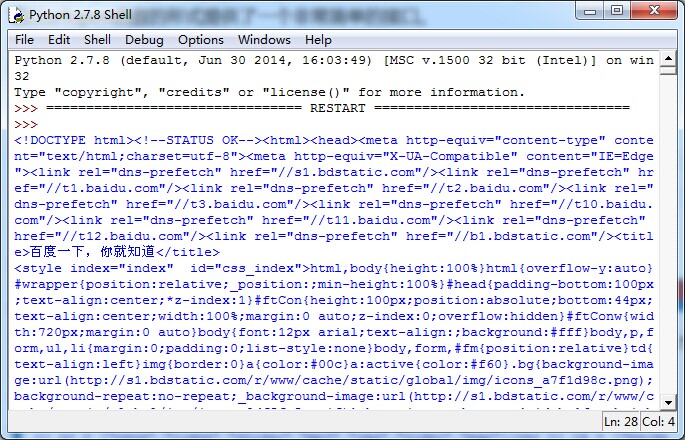
查看http://www.baidu.com/源代码发现跟以上运行结果完全一样。这里的URL除了http:还可以是ftp:或file:
urllib2用一个Request对象来映射提出的HTTP请求。你可以创建一个Request对象,通过调用urlopen并传入Request对象,将返回一个相关请求response对象,这个应答对象如同一个文件对象,所以你可以在Response中调用.read()。修改代码如下;
import urllib2
req = urllib2.Request('http://www.baidu.com')
response = urllib2.urlopen(req)
page = response.read()
print page
发现运行结果跟修改前一样。同时在http请求前你还需要做以下事1、发送表单数据。2、设置headers信息。
1、发送表单数据;常见于模拟登录时,一般的在登录操作时需要发送数据到服务器。这里主要用到post方法,一般的HTML表单,data需要编码成标准形式。然后做为data参数传到Request对象。编码工作使用urllib的函数而非urllib2。测试代码如下
import urllib
import urllib2
url = 'http://www.server.com/register.php'
postData = {'useid' : 'user',
'pwd' : '***',
'language' : 'Python' }
data = urllib.urlencode(postData) # 编码工作
req = urllib2.Request(url, data) # 发送请求同时传data
response = urllib2.urlopen(req) #接受反馈的信息
page = response.read() #读取反馈的内容
同时urllib2还可以使用get方法传送数据。代码如下;
import urllib2
import urllib
data = {}
data['useid'] = 'user'
data['pwd'] = '***'
data['language'] = 'Python'
values = urllib.urlencode(data)
print values
name=Somebody+Here&language;=Python&location;=Northampton
url = 'http://www.example.com/example.php'
full_url = url + '?' + url_values
data = urllib2.open(full_url)
2、设置headers信息;有些站点对访问来源做了限制,所以这里模拟User-Agent头,代码如下;
import urllib
import urllib2
url = 'http://www.server.com/register.php'
user_agent = 'Mozilla/5.0 (Windows NT 6.1; rv:33.0) Gecko/20100101 Firefox/33.0'
values = {'useid' : 'user',
'pwd' : '***',
'language' : 'Python' }
headers = { 'User-Agent' : user_agent }
data = urllib.urlencode(values)
req = urllib2.Request(url, data, headers)
response = urllib2.urlopen(req)
page = response.read()
urllib2就介绍到这里啦!
异常处理
通常URLError在没有网络连接时或者服务器地址不可达时产生,在这种情况下异常会带有resaon属性包含了错误号和错误信息。如下代码测试效果;
import urllib
import urllib2
url = 'http://www.server.com/register.php'
user_agent = 'Mozilla/5.0 (Windows NT 6.1; rv:33.0) Gecko/20100101 Firefox/33.0'
values = {'useid' : 'user',
'pwd' : '***',
'language' : 'Python' }
headers = { 'User-Agent' : user_agent }
data = urllib.urlencode(values)
req = urllib2.Request(url, data, headers)
response = urllib2.urlopen(req)
page = response.read()
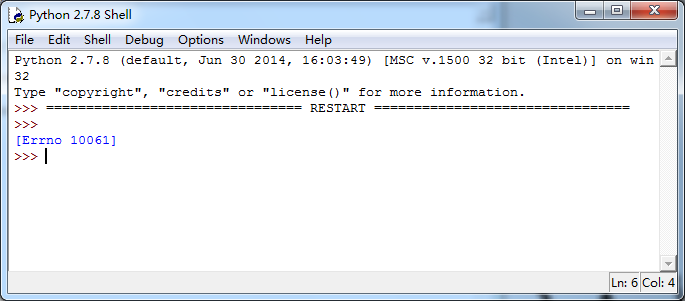
查阅相关资料后显示Errno 10061表示服务器端主动拒绝。
除此之外还有HTTPError,当客户端与服务器之间建立正常连接时,urllib2将开始处理相关数据。如果遇到不能处理的情况就会产生相应的HTTPError,如网站访问常见的错误码"404″(页面无法找到),"403″(请求禁止),和"401″(带验证请求)等……HTTP状态码表示HTTP协议的响应情况,常见的状态码见HTTP状态码详解。
HTTPError会带有一个'code'属性,是服务器发送的错误号。当一个HTTPError产生后服务器会返回一个相关的错误号和错误页面。如下代码验证;
import urllib2
req = urllib2.Request('http://www.python.org/callmewhy')
try:
urllib2.urlopen(req)
except urllib2.URLError, e:
print e.code
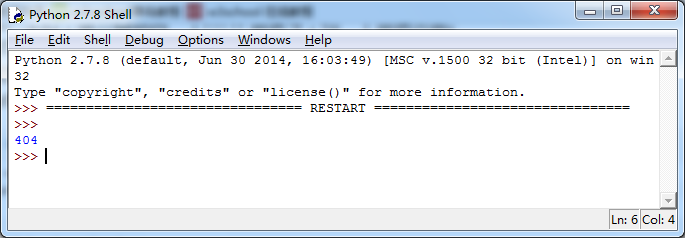
输出404代码,说明找不到页面。
捕捉异常并处理……实现代码如下;
#-*- coding:utf-8 -*-
from urllib2 import Request, urlopen, URLError, HTTPError
req = Request('http://www.python.org/callmewhy')
try:
response = urlopen(req)
except URLError, e:
if hasattr(e, 'code'):
print '服务器不能正常响应这个请求!'
print 'Error code: ', e.code
elif hasattr(e, 'reason'):
print '无法与服务器建立连接'
print 'Reason: ', e.reason
else:
print '没有出现异常'
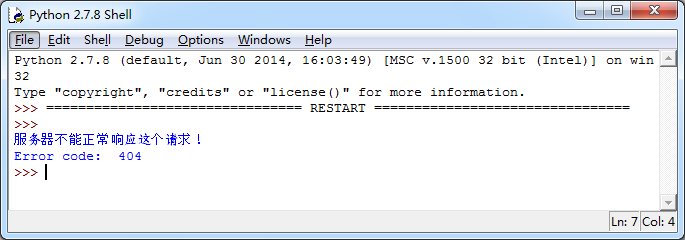
成功捕捉到异常!