python实现多线程抓取知乎用户
需要用到的包:
beautifulsoup4
html5lib
image
requests
redis
PyMySQL
pip安装所有依赖包:
pip install \
Image \
requests \
beautifulsoup4 \
html5lib \
redis \
PyMySQL运行环境需要支持中文
测试运行环境python3.5,不保证其他运行环境能完美运行
需要安装mysql和redis
配置 config.ini 文件,设置好mysql和redis,并且填写你的知乎帐号
向数据库导入 init.sql
Run
开始抓取数据: python get_user.py
查看抓取数量: python check_redis.py
效果
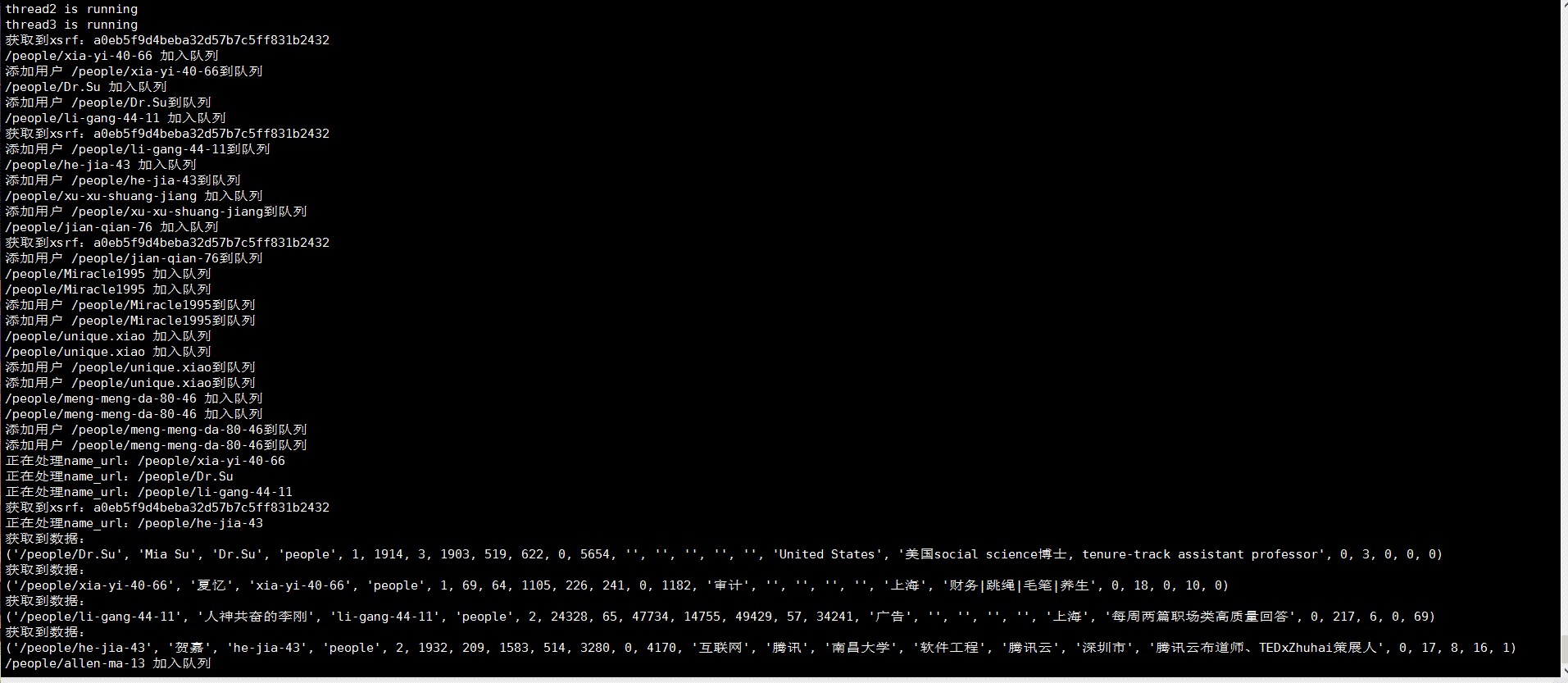
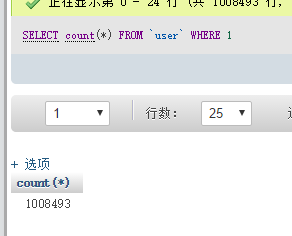
总体思路
1.首先是模拟登陆知乎,利用保存登陆的cookie信息
2.抓取知乎页面的html代码,留待下一步继续进行分析提取信息
3.分析提取页面中用户的个性化url,放入redis(这里特别说明一下redis的思路用法,将提取到的用户的个性化url放入redis的一个名为already_get_user的hash table,表示已抓取的用户,对于已抓取过的用户判断是否存在于already_get_user以去除重复抓取,同时将个性化url放入user_queue的队列中,需要抓取新用户时pop队列获取新的用户)
4.获取用户的关注列表和粉丝列表,继续插入到redis
5.从redis的user_queue队列中获取新用户继续重复步骤3
模拟登陆知乎
首先是登陆,登陆功能作为一个包封装了在login里面,方便整合调用
header部分,这里Connection最好设为close,不然可能会碰到max retireve exceed的错误
原因在于普通的连接是keep-alive的但是却又没有关闭
# http请求的header
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8",
"Host": "www.zhihu.com",
"Referer": "https://www.zhihu.com/",
"Origin": "https://www.zhihu.com/",
"Upgrade-Insecure-Requests": "1",
"Content-Type": "application/x-www-form-urlencoded; charset=UTF-8",
"Pragma": "no-cache",
"Accept-Encoding": "gzip, deflate, br",
'Connection': 'close'
}
# 验证是否登陆
def check_login(self):
check_url = 'https://www.zhihu.com/settings/profile'
try:
login_check = self.__session.get(check_url, headers=self.headers, timeout=35)
except Exception as err:
print(traceback.print_exc())
print(err)
print("验证登陆失败,请检查网络")
sys.exit()
print("验证登陆的http status code为:" + str(login_check.status_code))
if int(login_check.status_code) == 200:
return True
else:
return False
进入首页查看http状态码来验证是否登陆,200为已经登陆,一般304就是被重定向所以就是没有登陆
# 获取验证码
def get_captcha(self):
t = str(time.time() * 1000)
captcha_url = 'http://www.zhihu.com/captcha.gif?r=' + t + "&type;=login"
r = self.__session.get(captcha_url, headers=self.headers, timeout=35)
with open('captcha.jpg', 'wb') as f:
f.write(r.content)
f.close()
# 用pillow 的 Image 显示验证码
# 如果没有安装 pillow 到源代码所在的目录去找到验证码然后手动输入
'''try:
im = Image.open('captcha.jpg')
im.show()
im.close()
except:'''
print(u'请到 %s 目录找到captcha.jpg 手动输入' % os.path.abspath('captcha.jpg'))
captcha = input("请输入验证码\n>")
return captcha
获取验证码的方法。当登录次数太多有可能会要求输入验证码,这里实现这个功能
# 获取xsrf
def get_xsrf(self):
index_url = 'http://www.zhihu.com'
# 获取登录时需要用到的_xsrf
try:
index_page = self.__session.get(index_url, headers=self.headers, timeout=35)
except:
print('获取知乎页面失败,请检查网络连接')
sys.exit()
html = index_page.text
# 这里的_xsrf 返回的是一个list
BS = BeautifulSoup(html, 'html.parser')
xsrf_input = BS.find(attrs={'name': '_xsrf'})
pattern = r'value=\"(.*?)\"'
print(xsrf_input)
self.__xsrf = re.findall(pattern, str(xsrf_input))
return self.__xsrf[0]
获取xsrf,为什么要获取xsrf呢,因为xsrf是一种防止跨站攻击的手段,具体介绍可以看这里csrf
在获取到xsrf之后把xsrf存入cookie当中,并且在调用api的时候带上xsrf作为头部,不然的话知乎会返回403
# 进行模拟登陆
def do_login(self):
try:
# 模拟登陆
if self.check_login():
print('您已经登录')
return
else:
if self.config.get("zhihu_account", "username") and self.config.get("zhihu_account", "password"):
self.username = self.config.get("zhihu_account", "username")
self.password = self.config.get("zhihu_account", "password")
else:
self.username = input('请输入你的用户名\n> ')
self.password = input("请输入你的密码\n> ")
except Exception as err:
print(traceback.print_exc())
print(err)
sys.exit()
if re.match(r"^1\d{10}$", self.username):
print("手机登陆\n")
post_url = 'http://www.zhihu.com/login/phone_num'
postdata = {
'_xsrf': self.get_xsrf(),
'password': self.password,
'remember_me': 'true',
'phone_num': self.username,
}
else:
print("邮箱登陆\n")
post_url = 'http://www.zhihu.com/login/email'
postdata = {
'_xsrf': self.get_xsrf(),
'password': self.password,
'remember_me': 'true',
'email': self.username,
}
try:
login_page = self.__session.post(post_url, postdata, headers=self.headers, timeout=35)
login_text = json.loads(login_page.text.encode('latin-1').decode('unicode-escape'))
print(postdata)
print(login_text)
# 需要输入验证码 r = 0为登陆成功代码
if login_text['r'] == 1:
sys.exit()
except:
postdata['captcha'] = self.get_captcha()
login_page = self.__session.post(post_url, postdata, headers=self.headers, timeout=35)
print(json.loads(login_page.text.encode('latin-1').decode('unicode-escape')))
# 保存登陆cookie
self.__session.cookies.save()
这个就是核心的登陆功能啦,非常关键的就是用到了requests库,非常方便的保存到session
我们这里全局都是用单例模式,统一使用同一个requests.session对象进行访问功能,保持登录状态的一致性
最后主要调用登陆的代码为
# 创建login对象
lo = login.login.Login(self.session)
# 模拟登陆
if lo.check_login():
print('您已经登录')
else:
if self.config.get("zhihu_account", "username") and self.config.get("zhihu_account", "username"):
username = self.config.get("zhihu_account", "username")
password = self.config.get("zhihu_account", "password")
else:
username = input('请输入你的用户名\n> ')
password = input("请输入你的密码\n> ")
lo.do_login(username, password)
知乎模拟登陆到此就完成啦
知乎用户抓取
def __init__(self, threadID=1, name=''):
# 多线程
print("线程" + str(threadID) + "初始化")
threading.Thread.__init__(self)
self.threadID = threadID
self.name = name
try:
print("线程" + str(threadID) + "初始化成功")
except Exception as err:
print(err)
print("线程" + str(threadID) + "开启失败")
self.threadLock = threading.Lock()
# 获取配置
self.config = configparser.ConfigParser()
self.config.read("config.ini")
# 初始化session
requests.adapters.DEFAULT_RETRIES = 5
self.session = requests.Session()
self.session.cookies = cookielib.LWPCookieJar(filename='cookie')
self.session.keep_alive = False
try:
self.session.cookies.load(ignore_discard=True)
except:
print('Cookie 未能加载')
finally:
pass
# 创建login对象
lo = Login(self.session)
lo.do_login()
# 初始化redis连接
try:
redis_host = self.config.get("redis", "host")
redis_port = self.config.get("redis", "port")
self.redis_con = redis.Redis(host=redis_host, port=redis_port, db=0)
# 刷新redis库
# self.redis_con.flushdb()
except:
print("请安装redis或检查redis连接配置")
sys.exit()
# 初始化数据库连接
try:
db_host = self.config.get("db", "host")
db_port = int(self.config.get("db", "port"))
db_user = self.config.get("db", "user")
db_pass = self.config.get("db", "password")
db_db = self.config.get("db", "db")
db_charset = self.config.get("db", "charset")
self.db = pymysql.connect(host=db_host, port=db_port, user=db_user, passwd=db_pass, db=db_db,
charset=db_charset)
self.db_cursor = self.db.cursor()
except:
print("请检查数据库配置")
sys.exit()
# 初始化系统设置
self.max_queue_len = int(self.config.get("sys", "max_queue_len"))
这个是get_user.py的构造函数,主要功能就是初始化mysql连接、redis连接、验证登陆、生成全局的session对象、导入系统配置、开启多线程。
# 获取首页html
def get_index_page(self):
index_url = 'https://www.zhihu.com/'
try:
index_html = self.session.get(index_url, headers=self.headers, timeout=35)
except Exception as err:
# 出现异常重试
print("获取页面失败,正在重试......")
print(err)
traceback.print_exc()
return None
finally:
pass
return index_html.text
# 获取单个用户详情页面
def get_user_page(self, name_url):
user_page_url = 'https://www.zhihu.com' + str(name_url) + '/about'
try:
index_html = self.session.get(user_page_url, headers=self.headers, timeout=35)
except Exception as err:
# 出现异常重试
print("失败name_url:" + str(name_url) + "获取页面失败,放弃该用户")
print(err)
traceback.print_exc()
return None
finally:
pass
return index_html.text
# 获取粉丝页面
def get_follower_page(self, name_url):
user_page_url = 'https://www.zhihu.com' + str(name_url) + '/followers'
try:
index_html = self.session.get(user_page_url, headers=self.headers, timeout=35)
except Exception as err:
# 出现异常重试
print("失败name_url:" + str(name_url) + "获取页面失败,放弃该用户")
print(err)
traceback.print_exc()
return None
finally:
pass
return index_html.text
def get_following_page(self, name_url):
user_page_url = 'https://www.zhihu.com' + str(name_url) + '/followers'
try:
index_html = self.session.get(user_page_url, headers=self.headers, timeout=35)
except Exception as err:
# 出现异常重试
print("失败name_url:" + str(name_url) + "获取页面失败,放弃该用户")
print(err)
traceback.print_exc()
return None
finally:
pass
return index_html.text
# 获取首页上的用户列表,存入redis
def get_index_page_user(self):
index_html = self.get_index_page()
if not index_html:
return
BS = BeautifulSoup(index_html, "html.parser")
self.get_xsrf(index_html)
user_a = BS.find_all("a", class_="author-link") # 获取用户的a标签
for a in user_a:
if a:
self.add_wait_user(a.get('href'))
else:
continue
这一部分的代码就是用于抓取各个页面的html代码
# 加入带抓取用户队列,先用redis判断是否已被抓取过
def add_wait_user(self, name_url):
# 判断是否已抓取
self.threadLock.acquire()
if not self.redis_con.hexists('already_get_user', name_url):
self.counter += 1
print(name_url + " 加入队列")
self.redis_con.hset('already_get_user', name_url, 1)
self.redis_con.lpush('user_queue', name_url)
print("添加用户 " + name_url + "到队列")
self.threadLock.release()
# 获取页面出错移出redis
def del_already_user(self, name_url):
self.threadLock.acquire()
if not self.redis_con.hexists('already_get_user', name_url):
self.counter -= 1
self.redis_con.hdel('already_get_user', name_url)
self.threadLock.release()
用户加入redis的操作,在数据库插入出错时我们调用del_already_user删除插入出错的用户
# 分析粉丝页面获取用户的所有粉丝用户
# @param follower_page get_follower_page()中获取到的页面,这里获取用户hash_id请求粉丝接口获取粉丝信息
def get_all_follower(self, name_url):
follower_page = self.get_follower_page(name_url)
# 判断是否获取到页面
if not follower_page:
return
BS = BeautifulSoup(follower_page, 'html.parser')
# 获取关注者数量
follower_num = int(BS.find('span', text='关注者').find_parent().find('strong').get_text())
# 获取用户的hash_id
hash_id = \
json.loads(BS.select("#zh-profile-follows-list")[0].select(".zh-general-list")[0].get('data-init'))[
'params'][
'hash_id']
# 获取关注者列表
self.get_xsrf(follower_page) # 获取xsrf
post_url = 'https://www.zhihu.com/node/ProfileFollowersListV2'
# 开始获取所有的关注者 math.ceil(follower_num/20)*20
for i in range(0, math.ceil(follower_num / 20) * 20, 20):
post_data = {
'method': 'next',
'params': json.dumps({"offset": i, "order_by": "created", "hash_id": hash_id})
}
try:
j = self.session.post(post_url, params=post_data, headers=self.headers, timeout=35).text.encode(
'latin-1').decode(
'unicode-escape')
pattern = re.compile(r"class=\"zm-item-link-avatar\"[^\"]*\"([^\"]*)", re.DOTALL)
j = pattern.findall(j)
for user in j:
user = user.replace('\\', '')
self.add_wait_user(user) # 保存到redis
except Exception as err:
print("获取正在关注失败")
print(err)
traceback.print_exc()
pass
# 获取正在关注列表
def get_all_following(self, name_url):
following_page = self.get_following_page(name_url)
# 判断是否获取到页面
if not following_page:
return
BS = BeautifulSoup(following_page, 'html.parser')
# 获取关注者数量
following_num = int(BS.find('span', text='关注了').find_parent().find('strong').get_text())
# 获取用户的hash_id
hash_id = \
json.loads(BS.select("#zh-profile-follows-list")[0].select(".zh-general-list")[0].get('data-init'))[
'params'][
'hash_id']
# 获取关注者列表
self.get_xsrf(following_page) # 获取xsrf
post_url = 'https://www.zhihu.com/node/ProfileFolloweesListV2'
# 开始获取所有的关注者 math.ceil(follower_num/20)*20
for i in range(0, math.ceil(following_num / 20) * 20, 20):
post_data = {
'method': 'next',
'params': json.dumps({"offset": i, "order_by": "created", "hash_id": hash_id})
}
try:
j = self.session.post(post_url, params=post_data, headers=self.headers, timeout=35).text.encode(
'latin-1').decode(
'unicode-escape')
pattern = re.compile(r"class=\"zm-item-link-avatar\"[^\"]*\"([^\"]*)", re.DOTALL)
j = pattern.findall(j)
for user in j:
user = user.replace('\\', '')
self.add_wait_user(user) # 保存到redis
except Exception as err:
print("获取正在关注失败")
print(err)
traceback.print_exc()
pass
调用知乎的API,获取所有的关注用户列表和粉丝用户列表,递归获取用户
这里需要注意的是头部要记得带上xsrf不然会抛出403
# 分析about页面,获取用户详细资料
def get_user_info(self, name_url):
about_page = self.get_user_page(name_url)
# 判断是否获取到页面
if not about_page:
print("获取用户详情页面失败,跳过,name_url:" + name_url)
return
self.get_xsrf(about_page)
BS = BeautifulSoup(about_page, 'html.parser')
# 获取页面的具体数据
try:
nickname = BS.find("a", class_="name").get_text() if BS.find("a", class_="name") else ''
user_type = name_url[1:name_url.index('/', 1)]
self_domain = name_url[name_url.index('/', 1) + 1:]
gender = 2 if BS.find("i", class_="icon icon-profile-female") else (1 if BS.find("i", class_="icon icon-profile-male") else 3)
follower_num = int(BS.find('span', text='关注者').find_parent().find('strong').get_text())
following_num = int(BS.find('span', text='关注了').find_parent().find('strong').get_text())
agree_num = int(re.findall(r'<strong>(.*)</strong>.*赞同', about_page)[0])
appreciate_num = int(re.findall(r'<strong>(.*)</strong>.*感谢', about_page)[0])
star_num = int(re.findall(r'<strong>(.*)</strong>.*收藏', about_page)[0])
share_num = int(re.findall(r'<strong>(.*)</strong>.*分享', about_page)[0])
browse_num = int(BS.find_all("span", class_="zg-gray-normal")[2].find("strong").get_text())
trade = BS.find("span", class_="business item").get('title') if BS.find("span",
class_="business item") else ''
company = BS.find("span", class_="employment item").get('title') if BS.find("span",
class_="employment item") else ''
school = BS.find("span", class_="education item").get('title') if BS.find("span",
class_="education item") else ''
major = BS.find("span", class_="education-extra item").get('title') if BS.find("span",
class_="education-extra item") else ''
job = BS.find("span", class_="position item").get_text() if BS.find("span",
class_="position item") else ''
location = BS.find("span", class_="location item").get('title') if BS.find("span",
class_="location item") else ''
description = BS.find("div", class_="bio ellipsis").get('title') if BS.find("div",
class_="bio ellipsis") else ''
ask_num = int(BS.find_all("a", class_='item')[1].find("span").get_text()) if \
BS.find_all("a", class_='item')[
1] else int(0)
answer_num = int(BS.find_all("a", class_='item')[2].find("span").get_text()) if \
BS.find_all("a", class_='item')[
2] else int(0)
article_num = int(BS.find_all("a", class_='item')[3].find("span").get_text()) if \
BS.find_all("a", class_='item')[3] else int(0)
collect_num = int(BS.find_all("a", class_='item')[4].find("span").get_text()) if \
BS.find_all("a", class_='item')[4] else int(0)
public_edit_num = int(BS.find_all("a", class_='item')[5].find("span").get_text()) if \
BS.find_all("a", class_='item')[5] else int(0)
replace_data = \
(pymysql.escape_string(name_url), nickname, self_domain, user_type,
gender, follower_num, following_num, agree_num, appreciate_num, star_num, share_num, browse_num,
trade, company, school, major, job, location, pymysql.escape_string(description),
ask_num, answer_num, article_num, collect_num, public_edit_num)
replace_sql = '''REPLACE INTO
user(url,nickname,self_domain,user_type,
gender, follower,following,agree_num,appreciate_num,star_num,share_num,browse_num,
trade,company,school,major,job,location,description,
ask_num,answer_num,article_num,collect_num,public_edit_num)
VALUES(%s,%s,%s,%s,
%s,%s,%s,%s,%s,%s,%s,%s,
%s,%s,%s,%s,%s,%s,%s,
%s,%s,%s,%s,%s)'''
try:
print("获取到数据:")
print(replace_data)
self.db_cursor.execute(replace_sql, replace_data)
self.db.commit()
except Exception as err:
print("插入数据库出错")
print("获取到数据:")
print(replace_data)
print("插入语句:" + self.db_cursor._last_executed)
self.db.rollback()
print(err)
traceback.print_exc()
except Exception as err:
print("获取数据出错,跳过用户")
self.redis_con.hdel("already_get_user", name_url)
self.del_already_user(name_url)
print(err)
traceback.print_exc()
pass
最后,到用户的about页面,分析页面元素,利用正则或者beatifulsoup分析抓取页面的数据
这里我们SQL语句用REPLACE INTO而不用INSERT INTO,这样可以很好的防止数据重复问题
# 开始抓取用户,程序总入口
def entrance(self):
while 1:
if int(self.redis_con.llen("user_queue")) < 1:
self.get_index_page_user()
else:
# 出队列获取用户name_url redis取出的是byte,要decode成utf-8
name_url = str(self.redis_con.rpop("user_queue").decode('utf-8'))
print("正在处理name_url:" + name_url)
self.get_user_info(name_url)
if int(self.redis_con.llen("user_queue")) <= int(self.max_queue_len):
self.get_all_follower(name_url)
self.get_all_following(name_url)
self.session.cookies.save()
def run(self):
print(self.name + " is running")
self.entrance()
最后,入口
if __name__ == '__main__':
login = GetUser(999, "登陆线程")
threads = []
for i in range(0, 4):
m = GetUser(i, "thread" + str(i))
threads.append(m)
for i in range(0, 4):
threads[i].start()
for i in range(0, 4):
threads[i].join()
这里就是多线程的开启,需要开启多少个线程就把4换成多少就可以了
Docker
嫌麻烦的可以参考一下我用docker简单的搭建一个基础环境:
mysql和redis都是官方镜像
docker run --name mysql -itd mysql:latest
docker run --name redis -itd mysql:latest再利用docker-compose运行python镜像,我的python的docker-compose.yml:
python:
container_name: python
build: .
ports:
- "84:80"
external_links:
- memcache:memcache
- mysql:mysql
- redis:redis
volumes:
- /docker_containers/python/www:/var/www/html
tty: true
stdin_open: true
extra_hosts:
- "python:192.168.102.140"
environment:
PYTHONIOENCODING: utf-8最后附上源代码: GITHUB https://github.com/kong36088/ZhihuSpider
本站下载地址: http://xiazai.jb51.net/201612/yuanma/ZhihuSpider(jb51.net).zip