利用python实现命令行有道词典的方法示例
前言
由于一直用Linux系统,对于词典的支持特别不好,对于我这英语渣渣的人来说,当看英文文档就一直卡壳,之前用惯了有道词典,感觉很不错,虽然有网页版的但是对于全站英文的网页来说并不支持。索性自己实现一个,基于Python编写的小工具实现有道词典,思路也很简单,直接调用有道的api,解析下返回的json就ok了。
只用到了python原生的库,支持python2和python3.
示例代码
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# API key:273646050
# keyfrom:11pegasus11
import json
import sys
try: # py3
from urllib.parse import urlparse, quote, urlencode, unquote
from urllib.request import urlopen
except: # py2
from urllib import urlencode, quote, unquote
from urllib2 import urlopen
def fetch(query_str=''):
query_str = query_str.strip("'").strip('"').strip()
if not query_str:
query_str = 'python'
print(query_str)
query = {
'q': query_str
}
url = 'http://fanyi.youdao.com/openapi.do?keyfrom=11pegasus11&key;=273646050&type;=data&doctype;=json&version;=1.1&' + urlencode(query)
response = urlopen(url, timeout=3)
html = response.read().decode('utf-8')
return html
def parse(html):
d = json.loads(html)
try:
if d.get('errorCode') == 0:
explains = d.get('basic').get('explains')
for i in explains:
print(i)
else:
print('无法翻译')
except:
print('翻译出错,请输入合法单词')
def main():
try:
s = sys.argv[1]
except IndexError:
s = 'python'
parse(fetch(s))
if __name__ == '__main__':
main()使用
将上面代码粘贴后命名为youdao.py
修改名称mv youdao.py youdao, 然后加上可执行权限chmod a+x youdao
拷贝到/usr/local/bin。 cp youdao /usr/local/bin
使用的时候把要翻译的单词作为第一个命令行参数,要是句子用引号括起来。
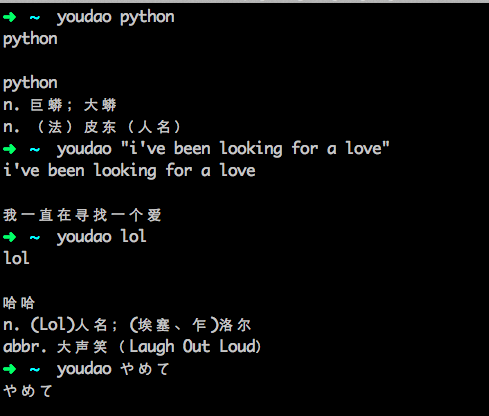
总结
以上就是这篇问文章的全部内容了,希望本文的内容对大家的学习或者工作能带来一定的帮助,如果有疑问大家可以留言交流。