本博客零散优化点汇总
熟悉本博客的同学可能早就发现,imququ.com 一直是我的一块试验田。我对网络协议、Web Server(Nginx)、服务端代码、前端代码每一层的研究 和优化,最终都会在本博客体现出来。我见过很多大谈用户体验的博主,自己博客体验并不怎样。我并不想在写如何做好优化性能的同时,自己的博客却十分缓慢。
关于具体的优化方案,我之前写过一些文章,如 Nginx 配置之性能篇、HTTP/2 相关优化,以后还会继续写。例如我最近在研究 ECC 证书对 HTTPS 性能的提升,等有结论了一定会跟大家分享。但同时有很多优化点我觉得比较常规,不值得分别写一篇文章去介绍。我准备把这些零散优化点罗列在本文,并不进行深入讨论。有 兴趣进一步了解和探讨的同学,欢迎发表评论。
顺便得瑟下,不久前我在 v2ex 发现这样一条回复,开心了好久(via):
他的博客速度最快,不服来辩 http://imququ.com/
专注 web 开发,他可是从底层协议到前端都有优化吧?
好了,下面开始进入正题。
静态资源优化
大家可以看一下本博客 HTML 源码,并没有任何外链资源,甚至你很可能连大段 css、js 也找不到。这是因为我将常规外链转成了 inline 输出,同时存入 localStorage,之后不再输出。这样做的优点有两个:1)首次访问减少连接数,后续访问减小页面体积;2)不怕刷新和强刷。
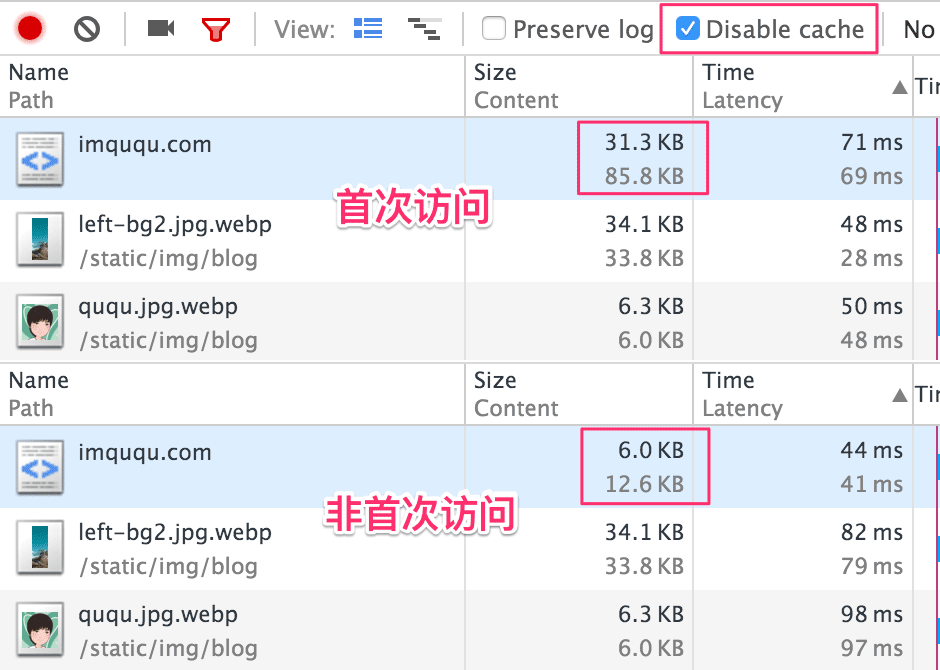
第一点很明显,将 inline
和外链两大方案取长补短。第二点也很重要,外链资源即使合理配置了强缓存和协商缓存,浏览器依然会在用户主动刷新时发起协商请求(响应码通常是
304,无响应正文,但依然需要建立连接);会在强刷时携带 Cache-Control:no-cache 和 Pragma:no- cache 头部,忽略所有缓存(产生响应码为 200 的完整请求)。很多并发流量很大的活动页,可以采用这种方案减少用户不断强刷对 CDN 产生的压力。
图片优化
不加载用户看不见的图片是最基本的优化,也就是图片 lazyload 策略。其实任何资源包括 Dom 节点都可以做 lazyload,这是老生常谈的话题,略过。
图片需要预先压缩。推荐一个 OSX 下的傻瓜式图片压缩工具 ImageOptim,非常好用。另外,使用 webp
格式,通常可以让图片文件大小大幅减小,可使用 cwebp、imagemagick 等命令行工具进行转换。判断浏览器是否支持 webp
图片,可以检查请求头中的 Accept 字段是否包含 image/webp;或者判断 JS 创建的 DataURI 格式的 webp
图片是否加载成功。后者一般还要配合存一个 Cookie。
需要注意的是,如果选择自己托管图片,不要开启服务器 gzip,效果微乎其微还浪费 CPU。如果选择将图片托管在七牛这样的云平台上,可以参考对应文档对图片进行 webp 格式转换,例如这是七牛的文档。另外,我咨询过七牛客服,现阶段使用七牛的 https 服务,已经没有免费额度了(via)。
还有,本站文章中引用的图片都在 HTML 中指定了高宽(在 Node.js 层解析 Markdown 语法时获取图片宽高),这样能很好地避免图片 lazyload 带来的页面跳动。
Google 统计优化
我一直在用 Google Analytics 分析本博客一些访问情况。大家知道使用 Google 统计需要引入它的 JS 文件,这个文件体积不小,缓存时间也 很短。我并不是十分在意详细访问情况,所以我把统计逻辑挪到了服务端。我自己生成用户唯一标识,获取访问页面的标题、URL、Referer,获取用户 IP 和浏览器 UA,随着每次访问发给 Google 的统计地址。服务端向 Google 发起的请求是异步的,用户端访问速度丝毫不受影响。另外这个方案还可以解决 Google 统计经常被墙的问题(当然,前提是服务端到 Google 统计地址的访问必须畅通)。
大家可以抓包看下本博客网络请求,肯定找不到任何与统计有关的内容(更新:现在应该可以看到一个本站的统计请求,这是为了让静态页也可以用上加速版的 Google 统计,我稍微改了一下实现)。但是,我所关注的统计功能丝毫不受影响,例如:
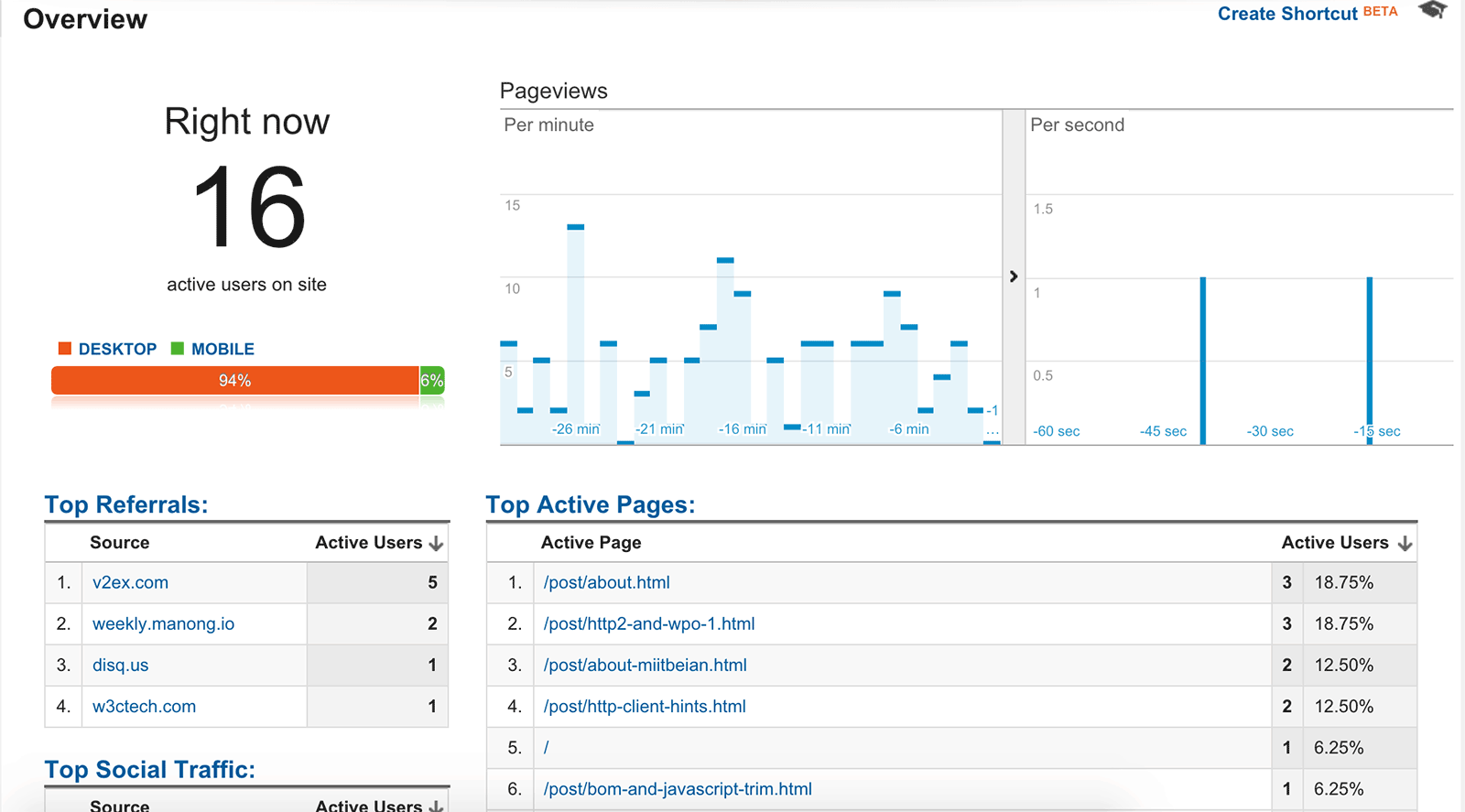
如果大家对我这个方案感兴趣,可以参考 Google 官方文档了解下细节。需要提醒的是,由于 Spider 的存在,采用服务端统计最好加上 UA 黑名单策略。
类似地,本博客使用了 Disqus 评论系统,每篇文章都会显示评论数。这个数字也没有使用 Disqus 的 JS API 在线获取,而是通过定期跑脚本离线更新,这样可以最大限度避免第三方服务对速度的影响。有同学问我 Disqus 经常要翻墙才能访问,为什么不换成多说,主要是多说实在太不稳定了,另外我认为现在这样也可以保证评论的高质量。
站内搜索优化
对于个人博客,一般有几种方案处理站内搜索。1)有自己数据库的博客,例如基于 WordPress、Typecho
搭建的博客,默认使用的数据库搜索;2)大部分静态博客,会直接跳转到 Google 等搜索引擎进行 site:
站内搜索;3)无论什么博客,都可以使用 Google CSE、Swiftype 之类的 JS Api 提供站内搜索。
这些方案,要么慢,要么对中文支持差(不支持分词、同义词),要么访问速度慢(被墙),要么收录速度慢,都不能满足我的需求。经过不懈研究,我最终采用了 bing
的 site: 搜索做为数据源,在服务端获取、解析、处理并缓存搜索结果,直接以 HTML
的形式输出搜索结果。这样无论是搜索效果,还是访问速度,都能令我满意。大家可以亲自试试,在本博客搜索
http/2、性能优化,或者其他任何词语,体验一下搜索效果和速度。
这里顺便说下,其实 Google 站内搜索效果也很好,但阿里云机房到 Google 的连通性太差了(根本 ping 不通),只能放弃。
2016-01-05 更新:本站站内搜索已经更换为自建的 Elasticsearch 引擎,具有更好的及时性和灵活性。查看详情 »
收录速度优化
如何让自己的文章更快被各大引擎收录,这属于 SEO 范畴,这里不深入。保证语义化的页面结构,使用友好的 URL 规则等等基本功,直接跳过。简单说下我的一些策略:
首先,网站必须有一个即时更新的 sitemap 文件,通过各大搜索引擎的站长平台提交给 Spider:Google、Bing、百度、好搜。
sitemap 提交给搜索引擎后,只能被动等待 Spider 周期性抓取。所以我在发布新文章之后,还会主动调用各大搜索引擎的 ping 服务即时推送。一些搜索引擎有自己私有格式的 ping 服务,具体格式可以参考各自站长平台的说明;大部分搜索引擎还支持通过 XML-RPC 远程调用 weblogUpdates.ping 方法实现主动推送。下面是 python 调用代码:
#!/usr/bin/python
# -*- coding: utf-8 -*-
from xmlrpclib import ServerProxy
from pprint import pprint
s = ServerProxy('http://rpc.pingomatic.com/')
ret = s.weblogUpdates.ping(u'JerryQu 的小站',
'https://imququ.com',
'https://imququ.com/post/datauri-and-404.html',
'https://imququ.com/rss.html'
)
pprint(ret)
除了上面代码中 pingomatic 提供的 ping 服务,百度和 Google 也有自己的服务地址:
- 百度:http://ping.baidu.com/ping/RPC2
- Google:http://blogsearch.google.com/ping/RPC2
另外,为了使得文章在发布后,能实时出现在各大 RSS 阅读平台,本博客还支持了 PubSubHubbub 协议。本博客的 RSS 文件指明了我所使用的 hub 服务地址为:https://imququ.superfeedr.com/,RSS 阅读平台会在这个网站注册自己的回调地址。这样每当我通知 superfeedr 有新文章了,所有注册过的 RSS 阅读平台就会收到通知,从而实时更新 Feed。常见的 Feedly、Inoreader 都支持 PubSubHubbub 协议。
国外访问优化
将博客搬到阿里云主机之后,经常收到 Google Webmaster 的抓取超时邮件提醒。我尝试通过 Linode Tokyo 机房访问我的博客,速度可以接受,于是决定用 Linode Tokyo 来加速国外访问。
通过免费的 DNSPod 服务已换成同样免费的 CloudXNS,可以很轻松地将域名针对国内、国外用户解析到不同 IP。为了让两个
IP 都能访问到我的博客,我可以在 Linode 上再部署一遍博客系统,这样就需要考虑代码及数据的同步,有点麻烦。我最终选择在 Linode 上使用
Nginx 的 proxy_pass 配置反向代理。
这样国外用户访问我的博客,会被解析到 Linode Tokyo,再反向代理到部署在阿里云上的服务。由于国外访问 Linode 很快,Linode 到阿里云的速度还可以接受,这样改造后比从国外直接访问阿里云要快不少。以下是 Google Webmaster 中有关本博客下载时间的统计:
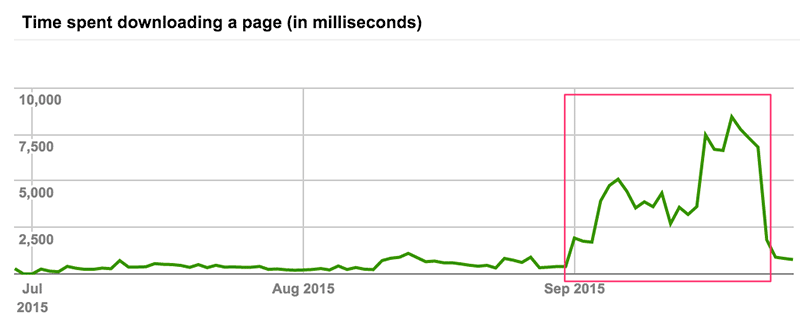
可以看到,迁移到阿里云之后,Google 下载页面所需时间大幅提升。配置反向代理后,又有大幅减少。
2016-01-30 更新:实际上,写完本文后没多久,从 Linode Tokyo 访问阿里云青岛变得非常不稳定,我还是选择了部署了两套独立的服务。
启用 Google 翻译
前几天,我在 Mozilla 官方博客一篇文章的评论中反馈了一个问题,最终 Mozilla 的工作人员通过 Google 翻译看懂了我的博客,并确认了这个问题(via):
The comment author's blog post discusses caching scripts in localStorage and reloading them using blobs or data URIs with integrity. SRI is used to prevent XSS attacks from becoming persistent.
I could read and understand the post quite well using Google Translate. The summary is that Data URI don't work, because Chrome treats them cross-origin. Blobs work in Chrome but fail to load in Firefox. See the table at https://imququ.com/post/enhance-security-for-ls-code.html for more.
为了让这极少数的国际友人更好地阅读我的博客,我决定在本博客加上 Google 翻译组件。页面内置的 Google 翻译组件可以更好地处理评论这一类异步生成的内容,使用也很简单,添加 HTML 结构及对应的 JS 文件就可以了。需要注意的是,如果网站启用了 CSP 策略,需要把 Google 翻译的域名加进去。
如果仅仅是不管青红皂白加上 Google 翻译代码,显然不符合我对本博客性能的极致追求。为此,我做了两点处理:1)对于国内 IP,始终不启用翻译功能,不额外加载任何资源;2)对于国外 IP,判断用户浏览器语言,不是简体中文才启用翻译并加载相关资源。
判断浏览器语言好办,但是国内外 IP 如何判断呢?我采用了一个取巧的办法:前一节我写到利用 DNSPodCloudXNS
的国内外解析到不同 IP 的功能,在 Linode 上搭建反向代理来加速。在这个基础上,只要在 Nginx 反向代理配置中,通过
proxy_set_header 指令增加一个额外的自定义请求头,再在源站程序中判断一下这个头是否存在,就可以区分访问是来自国内还是国外了。
2016-08-10 更新:本策略已下线。
实际上,本博客访问速度很快还有一个原因:Web 框架选型,我选择了 ThinkJS 这个性能非常优秀的 NodeJS 框架。ThinkJS 框架自身开销只有几毫秒,还有丰富的缓存机制和灵活的扩展接口,使得实现高效的 Web 应用变得更容易。关于这部分内容,后续有时间再专门介绍。