详解Python的Django框架中的通用视图
通用视图
1. 前言
回想一下,在Django中view层起到的作用是相当于controller的角色,在view中实施的
动作,一般是取得请求参数,再从model中得到数据,再通过数据创建模板,返回相应
响应对象。但在一些比较通用的功能中,比如显示对象列表,显示某对象信息,如果反复
写这么多流程的代码,也是一件浪费时间的事,在这里,Django同样给我们提供了类似的
"shortcut"捷径--通用视图。
2. 使用通用视图
使用通用视图的方法就是在urls.py这个路径配置文件中进行,创建字典配置信息,然后
传入patterns里的元组的第三个参数(extra-parameter),下面来看一个简单的例子:
from django.conf.urls.defaults import *
from django.views.generic.simple import direct_to_template
urlpatterns = patterns('',
url(r'^about/$', direct_to_template, {'template': 'about.html'}),
)
运行结果:
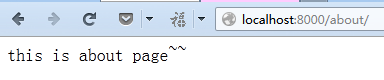
可以看到,没有view的代码,也可以直接运行。在这里direct_to_template,这个方法
,传入第三个参数,然后直接进行渲染。
同时因为direct_to_template是一个函数,我们又可以把它放在view中,下面把
上面的例子改成匹配about/*,任意子网页。
#urls.py
from django.conf.urls.defaults import *
from django.views.generic.simple import direct_to_template
from mysite.books.views import about_pages
urlpatterns = patterns('',
(r'^about/$', direct_to_template, {
'template': 'about.html'
}),
(r'^about/(\w+)/$', about_pages),
)
# view.py
from django.http import Http404
from django.template import TemplateDoesNotExist
from django.views.generic.simple import direct_to_template
#由正则匹配的参数
def about_pages(request, page):
try:
return direct_to_template(request, template="about/%s.html" % page)#返回的HttpResponse
except TemplateDoesNotExist:
raise Http404()
运行结果:
安全问题的题外话
上面的例子中,有一个潜在的安全问题,比较容易被忽略。那就是template="about/%s.html" % page这
句,这样构造路径容易被名为directory traversal的手段攻击,简单的说就是利用"../"这样的返回父目录的
路径操作,去访问原本不应该被访问到的服务器上的文件,又被称为dot dot slash攻击。比如
使用"http://www.cnblogs.com/../etc/passwd"路径的话,有可能就能读取到服务器上的passwd这个文件,从而获取到
关键密码。
发布这篇博文的时候,cnblogs会把连续的"../"转义成"http://www.cnblogs.com",难道是在防止
dot dot slash攻击?不信,你可以试试。
那在上面的例子中会不会有这个问题呢?
答案:不会的。。。
因为\w只会匹配数字,字母和下划线,不会去匹配dot这个符号。所以可以安心使用。
回车后,会直接退回到主页,无法匹配。
3. 用于显示对象内容的通用视图
同样,我们可以只需要model,urls.py文件就可以显示对象的信息:
model.py,之前例子中Publisher的定义
class Publisher(models.Model):
name = models.CharField(max_length=30)
address = models.CharField(max_length=50)
city = models.CharField(max_length=60)
state_province = models.CharField(max_length=30)
country = models.CharField(max_length=50)
website = models.URLField()
def __unicode__(self):
return self.name
#urls.py
from django.conf.urls.defaults import *
from django.views.generic import list_detail
from mysite.books.models import Publisher
publisher_info = {
'queryset': Publisher.objects.all(),
'template_name': 'publisher_list_page.html',
}
urlpatterns = patterns('',
url(r'^publishers/$', list_detail.object_list, publisher_info),
)
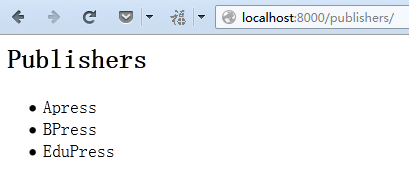
#publisher_list_page.html
<h2>Publishers</h2>
<ul>
{% for publisher in object_list %}
<li>{{ publisher.name }}</li>
{% endfor %}
</ul>
也是要构造一个字典参数,包含数据源和模板信息,再传给list_detail.object_list方法,
然后直接完成渲染的工作。运行结果:
4. 通用视图的几种扩展用法
4.1 自定义结果集的模板名
上面的例子中 ,模板文件中的变量名一直是object_list,如果有多个数据需要显示,那就
会,通用视图提供了一种解决这种冲突的命名方法,就是在字典类型中加入template_object_name
变量,此变量+_list就组成模板文件中使用的变量名
publisher_info = {
'queryset': Publisher.objects.all(),
'template_name': 'publisher_list_page.html',
'template_object_name': 'publisher',
}
模板文件也要作相应的修改:
<h2>Publishers</h2>
<ul>
{% for publisher in publisher_list %}
<li>{{ publisher.name }}</li>
{% endfor %}
</ul>
运行结果同上。
4.2 增加额外的context
也是在字典变量中进行修改,增加"extra_context"变量,它的值就是额外的对象数据的字典描述,
就可以用在模板文件中使用字典描述中的key来当作变量名。
publisher_info = {
'queryset': Publisher.objects.all(),
'template_object_name': 'publisher',
'template_name': 'publisher_list_page.html',
'extra_context': {'book_list': Book.objects.all()}
}
模板文件也要做相应的改:
<h2>Publishers</h2>
<ul>
{% for publisher in publisher_list %}
<li>{{ publisher.name }}</li>
{% endfor %}
</ul>
<h2>Book</h2>
<ul>
{% for book in book_list %}
<li>{{ book.title }}</li>
{% endfor %}
</ul>
运行结果为:
上面的代码又有一个问题,那就是'book_list': Book.objects.all(),这段代码因为
在urls.py中,所以只会在第一次执行此路径的时候执行一次,而不会因为Book的值
改变而改变,这是会使用到Django的缓存功能;而"queryset"中的值,Django是不会
缓存的,所以会随着数据改变而改变。
解决方法就是使用函数引用来代替直接的返回值,任何在extra_context中的函数都会在
视图每一次渲染的时候执行一次。所以代码可以改成:
def get_books():
return Book.objects.all()
publisher_info = {
'queryset': Publisher.objects.all(),
'template_object_name': 'publisher',
'template_name': 'publisher_list_page.html',
'extra_context': {'book_list': get_books},
}
或者改写成:
publisher_info = {
'queryset': Publisher.objects.all(),
'template_object_name': 'publisher',
'extra_context': {'book_list': Book.objects.all},
}
只要是引用参数就可以。
4.3 查看结果集的子集
方法很简单,就是在字典数据中使用manage有的方法进行结果集操作,如filter等。
apress_books = {
'queryset': Book.objects.filter(publisher__name='Apress'),
'template_name': 'books/apress_list.html',
}
urlpatterns = patterns('',
url(r'^books/apress/$', list_detail.object_list, apress_books),
)
4.4 更灵活的结果集操作
上面的代码可以看到,需要把publisher的名字硬编码在urls.py文件中,如何才能处理
从用户传递过来的任何publisher名字呢?
答案就是把list_detail.object_list方法放在views.py中调用,就可以使用从request传递过来
的参数。因为list_detail.object_list也只不过是普通的python函数。
#urls.py
urlpatterns = patterns('',
url(r'^publishers/$', list_detail.object_list, publisher_info),
url(r'^books/(\w+)/$', books_by_publisher),
)
#views.py
from django.shortcuts import get_object_or_404
from django.views.generic import list_detail
from mysite.books.models import Book, Publisher
def books_by_publisher(request, name):
# Look up the publisher (and raise a 404 if it can't be found).
publisher = get_object_or_404(Publisher, name__iexact=name)
# Use the object_list view for the heavy lifting.
return list_detail.object_list(
request,
queryset = Book.objects.filter(publisher=publisher),
template_name = 'books_by_publisher.html',
template_object_name = 'book',
extra_context = {'publisher': publisher}
)
list_detail.object_list返回的也是HttpResponse,
4.5 利用通用视图做额外工作
利用4.4的功能,在执行完list_detail.object操作之后,不立即返回HttpResponse对象,而是
赋值给response变量,再进行一些额外的处理,最后再返回HttpResponse对象,这样就可以
在使用通用视图功能之前或者之后做一些处理操作。下面例子的功能是在每一次访问作者之后
,都会更新作者的最后被访问时间。
#urls.py
from mysite.books.views import author_detail
urlpatterns = patterns('',
# ...
url(r'^authors/(?P<author_id>\d+)/$', author_detail),
# ...
)
#views.py
import datetime
from django.shortcuts import get_object_or_404
from django.views.generic import list_detail
from mysite.books.models import Author
def author_detail(request, author_id):
# 执行通用视图函数,但不立即返回HttpResponse对象
response = list_detail.object_list(
request,
queryset = Author.objects.all(),
object_id = author_id,
)
# 记录访问该作者的时间
now = datetime.datetime.now()
Author.objects.filter(id=author_id).update(last_accessed=now)
# 返回通用视图生成的HttpResponse对象
return response
我们还可以修改HttpResponse对象的相关参数来达到改变响应信息的目的。比如
def author_list_plaintext(request):
response = list_detail.object_list(
request,
queryset = Author.objects.all(),
mimetype = 'text/plain',
template_name = 'author_list.txt'
)
#修改响应格式,使其的内容不直接显示在网页中,而是储存在文件中,下载下来。
response["Content-Disposition"] = "attachment; filename=authors.txt"
return response
模板文件author_list.txt的内容:
<h2>Author</h2>
<ul>
{% for author in object_list %}
<li>{{ author.first_name }}</li>
{% endfor %}
</ul>
运行结果为生成authors.txt文件并提供下载:
文本内容会保留HTML标签信息。