网站渗透常用Python小脚本查询同ip网站
旁站查询来源:
http://dns.aizhan.com
http://s.tool.chinaz.com/same
http://i.links.cn/sameip/
http://www.ip2hosts.com/
效果图如下:
以百度网站和小残博客为例:
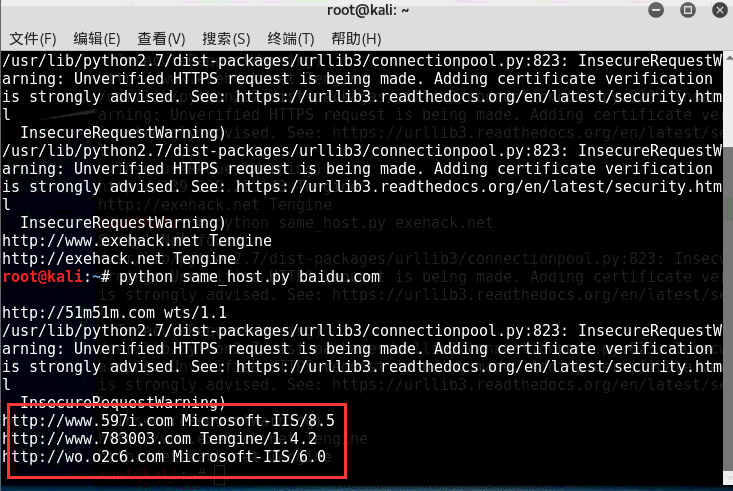
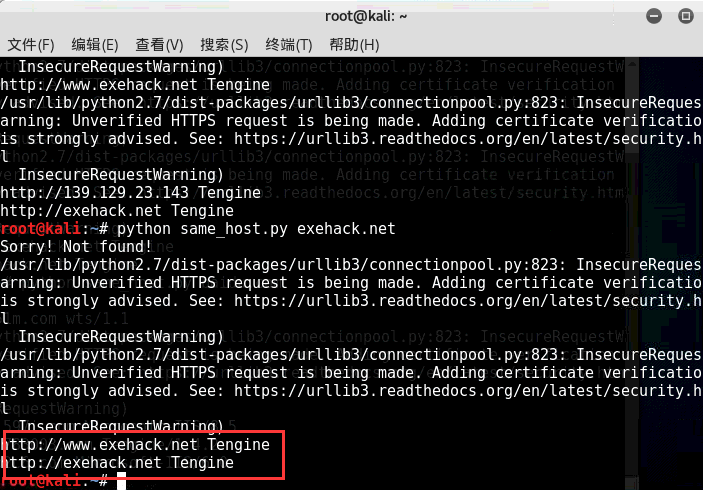
PS:直接调用以上4个旁注接口查询同服服务器域名信息包含服务器类型 比如小残博客使用的是Tengine
#!/usr/bin/env python
#encoding: utf-8
import re
import sys
import json
import time
import requests
import urllib
import requests.packages.urllib3
from multiprocessing import Pool
from BeautifulSoup import BeautifulSoup
requests.packages.urllib3.disable_warnings()
headers = {'User-Agent' : 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_3) AppleWebKit/535.20 (KHTML, like Gecko) Chrome/19.0.1036.7 Safari/535.20'}
def links_ip(host):
'''
查询同IP网站
'''
ip2hosts = []
ip2hosts.append("http://"+host)
try:
source = requests.get('http://i.links.cn/sameip/' + host + '.html', headers=headers,verify=False)
soup = BeautifulSoup(source.text)
divs = soup.findAll(style="word-break:break-all")
if divs == []: #抓取结果为空
print 'Sorry! Not found!'
return ip2hosts
for div in divs:
#print div.a.string
ip2hosts.append(div.a.string)
except Exception, e:
print str(e)
return ip2hosts
return ip2hosts
def ip2host_get(host):
ip2hosts = []
ip2hosts.append("http://"+host)
try:
req=requests.get('http://www.ip2hosts.com/search.php?ip='+str(host), headers=headers,verify=False)
src=req.content
if src.find('result') != -1:
result = json.loads(src)['result']
ip = json.loads(src)['ip']
if len(result)>0:
for item in result:
if len(item)>0:
#log(scan_type,host,port,str(item))
ip2hosts.append(item)
except Exception, e:
print str(e)
return ip2hosts
return ip2hosts
def filter(host):
'''
打不开的网站...
'''
try:
response = requests.get(host, headers=headers ,verify=False)
server = response.headers['Server']
title = re.findall(r'<title>(.*?)</title>',response.content)[0]
except Exception,e:
#print "%s" % str(e)
#print host
pass
else:
print host,server
def aizhan(host):
ip2hosts = []
ip2hosts.append("http://"+host)
regexp = r'''<a href="[^']+?([^']+?)/" rel="external nofollow" target="_blank">\1</a>'''
regexp_next = r'''<a href="http://dns.aizhan.com/[^/]+?/%d/" rel="external nofollow" >%d</a>'''
url = 'http://dns.aizhan.com/%s/%d/'
page = 1
while True:
if page > 2:
time.sleep(1) #防止拒绝访问
req = requests.get(url % (host , page) ,headers=headers ,verify=False)
try:
html = req.content.decode('utf-8') #取得页面
if req.status_code == 400:
break
except Exception as e:
print str(e)
pass
for site in re.findall(regexp , html):
ip2hosts.append("http://"+site)
if re.search(regexp_next % (page+1 , page+1) , html) is None:
return ip2hosts
break
page += 1
return ip2hosts
def chinaz(host):
ip2hosts = []
ip2hosts.append("http://"+host)
regexp = r'''<a href='[^']+?([^']+?)' target=_blank>\1</a>'''
regexp_next = r'''<a href="javascript:" rel="external nofollow" val="%d" class="item[^"]*?">%d</a>'''
url = 'http://s.tool.chinaz.com/same?s=%s&page;=%d'
page = 1
while True:
if page > 1:
time.sleep(1) #防止拒绝访问
req = requests.get(url % (host , page) , headers=headers ,verify=False)
html = req.content.decode('utf-8') #取得页面
for site in re.findall(regexp , html):
ip2hosts.append("http://"+site)
if re.search(regexp_next % (page+1 , page+1) , html) is None:
return ip2hosts
break
page += 1
return ip2hosts
def same_ip(host):
mydomains = []
mydomains.extend(ip2host_get(host))
mydomains.extend(links_ip(host))
mydomains.extend(aizhan(host))
mydomains.extend(chinaz(host))
mydomains = list(set(mydomains))
p = Pool()
for host in mydomains:
p.apply_async(filter, args=(host,))
p.close()
p.join()
if __name__=="__main__":
if len(sys.argv) == 2:
same_ip(sys.argv[1])
else:
print ("usage: %s host" % sys.argv[0])
sys.exit(-1)大家可以发挥添加或者修改任意查询接口。注意是这个里面的一些思路与代码。