离线 Web App 以及消息同步与推送实现
离线 Web App 以及消息同步与推送实现
丰富的离线体验、定期的后台同步以及推送通知等通常需要将面向本机应用的功能将引入到网页应用中。 Service Worker 提供所有这些功能所依赖的技术基础。
什么是 Service Worker
Service Worker 是浏览器在后台独立于网页运行的脚本,它打开了通向不需要网页或用户交互的功能的大门。 现在,它们已包括如推送通知和后台同步等功能。 将来,Service Worker 将会支持如定期同步或地理围栏等其他功能。 本教程讨论的核心功能是拦截和处理网络请求,包括通过程序来管理缓存中的响应。
这个 API 之所以令人兴奋,是因为它可以支持离线体验,让开发者能够全面控制这一体验。
在 Service Worker 出现前,存在能够在网络上为用户提供离线体验的另一个 API,称为 AppCache。 AppCache API 存在的许多相关问题,在设计 Service Worker 时已予以避免。
Service Worker 相关注意事项:
- 它是一种 JavaScript Worker,无法直接访问 DOM。 Service Worker 通过响应 postMessage 接口发送的消息来与其控制的页面通信,页面可在必要时对 DOM 执行操作。
- Service Worker 是一种可编程网络代理,让您能够控制页面所发送网络请求的处理方式。
- Service Worker 在不用时会被中止,并在下次有需要时重启,因此,您不能依赖 Service Worker
onfetch和onmessage处理程序中的全局状态。 如果存在您需要持续保存并在重启后加以重用的信息,Service Worker 可以访问 IndexedDB API。 - Service Worker 广泛地利用了 promise,因此如果您不熟悉 promise,则应停下阅读此内容,看一看 Promise 简介。
Service Worker 生命周期
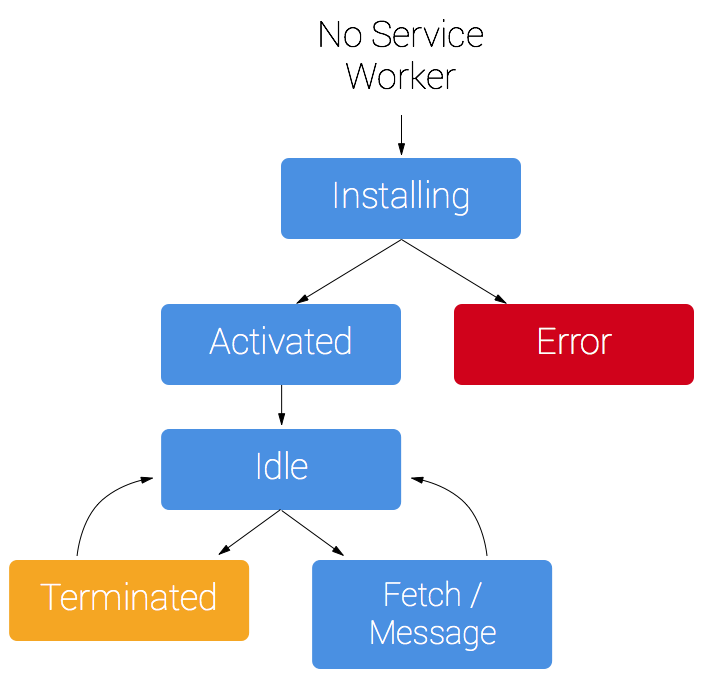
Service Worker 的生命周期完全独立于网页。
要为网站安装服务工作线程,您需要先在页面的 JavaScript 中注册。 注册服务工作线程将会导致浏览器在后台启动服务工作线程安装步骤。
在安装过程中,您通常需要缓存某些静态资产。 如果所有文件均已成功缓存,那么 Service Worker 就安装完毕。 如果任何文件下载失败或缓存失败,那么安装步骤将会失败,Service Worker 就无法激活(也就是说, 不会安装)。 如果发生这种情况,不必担心,它下次会再试一次。 但这意味着,如果安装完成,您可以知道您已在缓存中获得那些静态资产。
安装之后,接下来就是激活步骤,这是管理旧缓存的绝佳机会,我们将在 Service Worker 的更新部分对此详加介绍。
激活之后,Service Worker 将会对其作用域内的所有页面实施控制,不过,首次注册该 Service Worker 的页面需要再次加载才会受其控制。 服务工作线程实施控制后,它将处于以下两种状态之一:服务工作线程终止以节省内存,或处理获取和消息事件,从页面发出网络请求或消息后将会出现后一种状态。
以下是 Service Worker 初始安装时的简化生命周期。
先决条件
浏览器支持
可用的浏览器日益增多。 Service Worker 受 Chrome、Firefox 和 Opera 支持。 Microsoft Edge 现在表示公开支持。 甚至 Safari 也暗示未来会进行相关开发。 您可以在 Jake Archibald 的 is Serviceworker ready 网站上查看所有浏览器的支持情况 。
您需要 HTTPS
在开发过程中,可以通过 localhost 使用 Service Worker,但如果要在网站上部署 Service Worker,则需要在服务器上设置 HTTPS。
使用服务工作线程,您可以劫持连接、编撰以及过滤响应。 这是一个很强大的工具。 您可能会善意地使用这些功能,但中间人可会将其用于不良目的。 为避免这种情况,可仅在通过 HTTPS 提供的页面上注册 Service Worker,如此我们便知道浏览器接收的 Service Worker 在整个网络传输过程中都没有被篡改。
Github 页面 通过 HTTPS 提供,因此这些页面是托管演示的绝佳位置。
如果想要向服务器添加 HTTPS,您需要获得 TLS 证书并在服务器上进行设置。 具体因您的设置而异,因此请查看服务器的文档,并务必查阅 Mozilla SSL 配置生成器,了解最佳做法。
注册 Service Worker
若要安装 Service Worker,您需要通过在页面中对其进行注册来启动安装。 这将告诉浏览器 Service Worker JavaScript 文件的位置。
if ('serviceWorker' in navigator) {
window.addEventListener('load', function() {
navigator.serviceWorker.register('/sw.js').then(function(registration) {
// Registration was successful
console.log('ServiceWorker registration successful with scope: ', registration.scope);
}, function(err) {
// registration failed :(
console.log('ServiceWorker registration failed: ', err);
});
});
}此代码用于检查 Service Worker API 是否可用,如果可用,则在页面加载后注册位于 /sw.js 的 Service Worker。
每次页面加载无误时,即可调用 register();浏览器将会判断服务工作线程是否已注册并做出相应的处理。
register() 方法的精妙之处在于服务工作线程文件的位置。 您会发现在本例中服务工作线程文件位于根网域。 这意味着服务工作线程的作用域将是整个来源。 换句话说,Service Worker 将接收此网域上所有事项的 fetch 事件。 如果我们在 /example/sw.js 处注册 Service Worker 文件,则 Service Worker 将只能看到网址以 /example/ 开头(即 /example/page1/、/example/page2/)的页面的 fetch 事件。
现在,您可以通过转至 chrome://inspect/#service-workers 并寻找您的网站来检查 Service Worker 是否已启用。
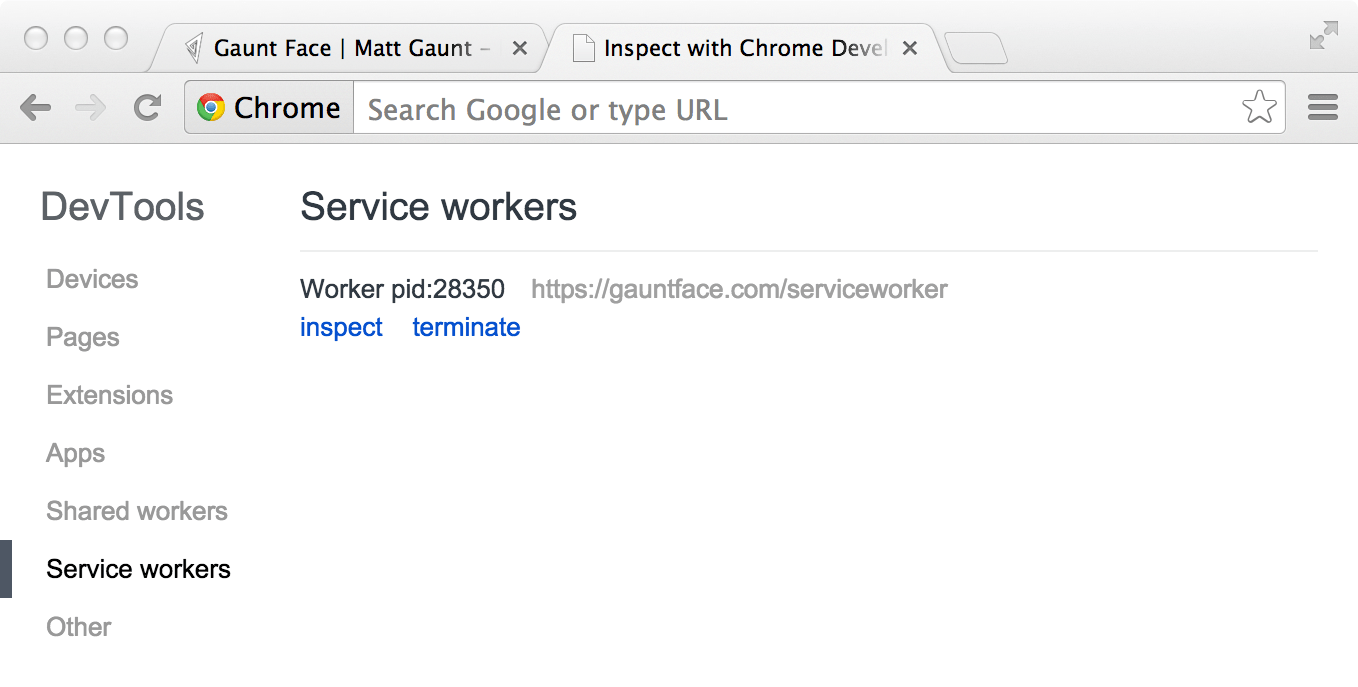
首次实施 Service Worker 时,您还可以通过 chrome://serviceworker-internals 来查看 Service Worker 详情。 如果只是想了解 Service Worker 的生命周期,这仍很有用,但是日后其很有可能被 chrome://inspect/#service-workers 完全取代。
您会发现,它还可用于测试隐身窗口中的服务工作线程,您可以关闭服务工作线程并重新打开,因为之前的服务工作线程不会影响新窗口。 从无痕式窗口创建的任何注册和缓存在该窗口关闭后均将被清除。
安装 Service Worker
在受控页面启动注册流程后,我们来看看处理 install 事件的 Service Worker 脚本。
最基本的例子是,您需要为安装事件定义回调,并决定想要缓存的文件。
self.addEventListener('install', function(event) {
// Perform install steps
});
在 install 回调的内部,我们需要执行以下步骤:
- 打开缓存。
- 缓存文件。
- 确认所有需要的资产是否已缓存。
var CACHE_NAME = 'my-site-cache-v1';
var urlsToCache = [
'/',
'/styles/main.css',
'/script/main.js'
];
self.addEventListener('install', function(event) {
// Perform install steps
event.waitUntil(
caches.open(CACHE_NAME)
.then(function(cache) {
console.log('Opened cache');
return cache.addAll(urlsToCache);
})
);
});此处,我们以所需的缓存名称调用 caches.open(),之后再调用 cache.addAll() 并传入文件数组。 这是一个 promise 链(caches.open() 和 cache.addAll())。 event.waitUntil() 方法带有 promise 参数并使用它来判断安装所花费的时间,以及安装是否成功。
如果所有文件都成功缓存,则将安装 Service Worker。 如有任何文件无法下载,则安装步骤将失败。 这可让您依赖于所定义的所有资产,但也意味着需要对您决定在安装步骤缓存的文件列表格外留意。 定义一个过长的文件列表将会增加文件缓存失败的几率,从而导致服务工作线程未能安装。
这仅是一个示例,实际您可以在 install 事件中执行其他任务,或完全避免设置 install 事件侦听器。
缓存和返回请求
您已安装 Service Worker,现在可能会想要返回一个缓存的响应,对吧?
在安装 Service Worker 且用户转至其他页面或刷新当前页面后,Service Worker 将开始接收 fetch 事件。下面提供了一个示例。
self.addEventListener('fetch', function(event) {
event.respondWith(
caches.match(event.request)
.then(function(response) {
// Cache hit - return response
if (response) {
return response;
}
return fetch(event.request);
}
)
);
});
这里我们定义了 fetch 事件,并且在 event.respondWith() 中,我们传入来自 caches.match() 的一个 promise。 此方法检视该请求,并从服务工作线程所创建的任何缓存中查找缓存的结果。
如果发现匹配的响应,则返回缓存的值,否则,将调用 fetch 以发出网络请求,并将从网络检索到的任何数据作为结果返回。 这是一个简单的例子,它使用了在安装步骤中缓存的所有资产。
如果希望连续缓存新请求,可以通过处理 fetch 请求的响应并将其添加到缓存来实现,如下所示。
self.addEventListener('fetch', function(event) {
event.respondWith(
caches.match(event.request)
.then(function(response) {
// Cache hit - return response
if (response) {
return response;
}
// IMPORTANT:Clone the request. A request is a stream and
// can only be consumed once. Since we are consuming this
// once by cache and once by the browser for fetch, we need
// to clone the response.
var fetchRequest = event.request.clone();
return fetch(fetchRequest).then(
function(response) {
// Check if we received a valid response
if(!response || response.status !== 200 || response.type !== 'basic') {
return response;
}
// IMPORTANT:Clone the response. A response is a stream
// and because we want the browser to consume the response
// as well as the cache consuming the response, we need
// to clone it so we have two streams.
var responseToCache = response.clone();
caches.open(CACHE_NAME)
.then(function(cache) {
cache.put(event.request, responseToCache);
});
return response;
}
);
})
);
});
执行的操作如下:
- 在
fetch请求中添加对.then()的回调。 - 获得响应后,执行以下检查:
- 确保响应有效。
- 检查并确保响应的状态为
200。 - 确保响应类型为 basic,亦即由自身发起的请求。 这意味着,对第三方资产的请求也不会添加到缓存。
- 如果通过检查,则克隆响应。 这样做的原因在于,该响应是数据流, 因此主体只能使用一次。 由于我们想要返回能被浏览器使用的响应,并将其传递到缓存以供使用,因此需要克隆一份副本。我们将一份发送给浏览器,另一份则保留在缓存。
更新 Service Worker
在某个时间点,您的 Service Worker 需要更新。 此时,您需要遵循以下步骤:
- 更新您的服务工作线程 JavaScript 文件。 用户导航至您的站点时,浏览器会尝试在后台重新下载定义 Service Worker 的脚本文件。 如果 Service Worker 文件与其当前所用文件存在字节差异,则将其视为_新 Service Worker_。
- 新 Service Worker 将会启动,且将会触发
install事件。 - 此时,旧 Service Worker 仍控制着当前页面,因此新 Service Worker 将进入
waiting状态。 - 当网站上当前打开的页面关闭时,旧 Service Worker 将会被终止,新 Service Worker 将会取得控制权。
- 新 Service Worker 取得控制权后,将会触发其
activate事件。
出现在 activate 回调中的一个常见任务是缓存管理。 您希望在 activate 回调中执行此任务的原因在于,如果您在安装步骤中清除了任何旧缓存,则继续控制所有当前页面的任何旧 Service Worker 将突然无法从缓存中提供文件。
比如说我们有一个名为 'my-site-cache-v1' 的缓存,我们想要将该缓存拆分为一个页面缓存和一个博文缓存。 这就意味着在安装步骤中我们创建了两个缓存:'pages-cache-v1' 和 'blog-posts-cache-v1',且在激活步骤中我们要删除旧的 'my-site-cache-v1'。
以下代码将执行此操作,具体做法为:遍历 Service Worker 中的所有缓存,并删除未在缓存白名单中定义的任何缓存。
self.addEventListener('activate', function(event) {
var cacheWhitelist = ['pages-cache-v1', 'blog-posts-cache-v1'];
event.waitUntil(
caches.keys().then(function(cacheNames) {
return Promise.all(
cacheNames.map(function(cacheName) {
if (cacheWhitelist.indexOf(cacheName) === -1) {
return caches.delete(cacheName);
}
})
);
})
);
});
瑕疵和问题
这是一项新事物, 下面是我们可能会遇到的问题汇总。 希望这些问题很快能消除,不过当前我们需要对这些问题多加留意。
如果安装失败,我们未必能告知您详情
如果 Worker注册后未在 chrome://inspect/#service-workers 或 chrome://serviceworker-internals 中显示,则有可能是引发错误或向 event.waitUntil() 发送被拒绝的 promise 而导致无法安装。
要解决该问题,请转至 chrome://serviceworker-internals 并勾选“Open DevTools window and pause JavaScript execution on service worker startup for debugging”,然后将调试程序语句置于安装事件开始处。 这与未捕获异常中的暂停共同揭露问题。
fetch() 默认值
默认情况下没有凭据
使用 fetch 时,默认情况下请求中不包含 Cookie 等凭据。 如需凭据,改为调用:
fetch(url, {
credentials: 'include'
})
这一行为是有意为之,可以说比 XHR 更复杂的以下默认行为更好:如果网址具有相同来源,则默认发送凭据,否则忽略。 提取的行为更接近于其他 CORS 请求,如 <imgcrossorigin>,它将决不会发送 Cookie,除非您使用 <imgcrossorigin="use-credentials"> 选择加入。
非 CORS 默认失败
默认情况下,从不支持 CORS 的第三方网址中提取资源将会失败。 您可以向请求中添加 no-CORS 选项来克服此问题,不过这可能会导致“不透明”的响应,这意味着您无法辨别响应是否成功。
cache.addAll(urlsToPrefetch.map(function(urlToPrefetch) {
return new Request(urlToPrefetch, { mode: 'no-cors' });
})).then(function() {
console.log('All resources have been fetched and cached.');
});
处理响应式图像
srcset 属性或 <picture> 元素将在运行期间选择最适当的图像资产,并发出网络请求。
对于 Service Worker,如果您想要在安装过程中缓存图像,您有下列几种选择:
- 安装
<picture>元素和srcset属性将请求的所有图像。 - 安装一个低分辨率版本的图像。
- 安装一个高分辨率版本的图像。
实际上,您应该选择 2 或 3,因为下载所有图像会浪费存储空间。
假定您在安装期间选择安装低分辨率版本的图像,在页面加载时您想要尝试从网络中检索高分辨率的图像,但是如果检索高分辨率版本失败,则回退到低分辨率版本。 这没有问题,而且这种做法很好,但是有另外一个问题。
如果我们有以下两张图像:
| 屏幕密度 | 宽度 | 高度 |
|---|---|---|
| 1x | 400 | 400 |
| 2x | 800 | 800 |
在 srcset 图像中,我们有一些像这样的标记:
<img src="image-src.png" srcset="image-src.png 1x, image-2x.png 2x" />如果我们使用的是 2x 显示屏,浏览器将会选择下载 image-2x.png。如果我们处于离线状态,您可以对请求执行 .catch() 并返回 image-src.png(如已缓存)。但是,浏览器会期望 2x 屏幕上的图像有额外的像素,这样图像将显示为 200x200 CSS 像素而不是 400x400 CSS 像素。 解决该问题的唯一办法是设定固定的图像高度和宽度。
<img src="image-src.png" srcset="image-src.png 1x, image-2x.png 2x"
style="width:400px; height: 400px;" />
对于要用于艺术指导的 <picture> 元素,这会变得相当困难,而且很大程度上取决于图像的创建和使用方式,但是您可以使用类似于 srcset 的方法。