2019年十大精彩AI学术论文盘点
当然,这一年有许多论文都具有显著的学术价值,下面总结出的只是冰山一角。如果你觉得还有哪些论文是同样值得被回顾的,欢迎在评论区留言和我们讨论。
除此之外,我们还准备了一篇“2019 年十大新奇论文”,总结了这一年中尤其新颖有趣、甚至出格招致批评的论文。
2019 年精彩学术论文 Top10(按首字母排序)
A Style-Based Generator Architecture for Generative Adversarial Networks ( CVPR 2019 )

一个基于风格的GAN生成器架构
作者:NVIDIA 实验室 Tero Karras, Samuli Laine, Timo Aila
推荐理由:StyleGAN 无疑是 2019 年最热门的 GAN 网络模型。在 StyleGAN 之前,GAN 的相关研究已经遇到了条件式生成困难、单纯增加模型大小的收益有限、无法生成逼真的高分辨率图像等等多种困境,StyleGAN 就冲破了这个瓶颈,在生成控制的可控制性、不同属性的互相搭配、高分辨率高清晰度(且具备一致性)方面都带来了大幅进步。为此,StyleGAN 获得了 CVPR 2019 最佳论文荣誉提名奖。

StyleGAN 在网络上引发了大量讨论,它惊人的人脸生成效果不仅折服了吃瓜群众,也吸引了很多人撰写自己的实现并开放 demo 供所有人尝试,包括生成人脸(thispersondoesnotexist.com)、生成猫(thiscatsondoesnotexist.com)、生成二次元妹子(thiswaifudoesnotexist.net)、生成房间照片(thisairbnbdoesnotexist.com)的模型。
就在近期,包括论文原作者在内的 NVIDIA 实验室研究人员们发表了 StyleGAN2 论文(Analyzing and Improving the Image Quality of StyleGAN,arxiv.org/abs/1912.04958),针对性地修正了 StyleGAN 生成的图像中的缺陷等问题、提高了图像中元素的一致性,从而把图像生成质量带到了新的高峰。
论文地址:StyleGAN arxiv.org/abs/1812.04948,StyleGAN2 arxiv.org/abs/1912.04958
代码开源:https://github.com/NVlabs/stylegan2
Bridging the Gap between Training and Inference for Neural Machine Translation ( ACL 2019 )
弥补神经机器翻译模型训练和推理之间的缺口
作者:中科院计算所智能信息处理重点实验室,中国科学院大学,微信 AI 模式识别中心,伍斯特理工学院,华为诺亚方舟实验室
推荐理由:神经机器翻译模型的训练方式是给定上下文,预测某一些被掩模的词,但推理过程(真正的翻译过程)是需要从零生成整个句子。这种偏差问题其实在序列到序列转换任务中长期普遍存在。这篇论文就研究了这种偏差,并探讨如何弥补这种偏差。
作者们提出的解决方案是,生成条件在“基于参考文本中的词”和“解码器自己的输出中预选择词”两种之间切换,论文的实验做得非常完善,结果令人信服。根据 ACL 2019 论文奖评选委员会的意见,这种方法适用于当前的纯学习训练范式,也能为规划采样带来改进;而且,这不仅可能影响本来针对的机器翻译任务的未来研究和应用,也能用来普遍地改进其它的序列到序列转换模型。这篇论文也被选为 ACL 2019 最佳论文。
论文地址:https://arxiv.org/abs/1906.02448
Grandmaster Level in StarCraft II Using Multi-agent Reinforcement Learning ( Nature )

通过多智能体强化学习在星际2中达到“Grandmaster”段位
作者:DeepMind Oriol Vinyals、Demis Hassabis、Chris Apps & David Silver 等
推荐理由:2019 年 1 月,DeepMind 开发的星际 2 AI“AlphaStar”首次亮相就击败了人类职业选手。虽然当时的比赛规则明显对 AI 方有利,但我们已经感受到了 AI 并不是靠操作速度、而主要是靠优秀的策略取得胜利的。后来,在公平规则的、基于星际 2 天梯的大规模人机 1v1 比赛中,AlphaStar 继续发挥出了优秀的表现,取得了“Grandmaster”段位,大概为所有活跃玩家的前 0.15%。这也成为了 AlphaStar 论文发表在《Nature》杂志 2019 年 10 月刊所需要的最后一个实验。

AI 在游戏中胜过人类当然不是第一次了,不过 DeepMind 开发 AlphaStar 并不仅仅(和其它游戏 AI 一样)使用了大量的计算能力,他们使用的群体强化学习(群体进化、保留多种不同策略)等设计也改善了通常强化学习做法的问题,提高了智能体在复杂环境中的表现。不完全信息、高维连续行动空间的长序列建模问题的解决方案日趋成熟。
论文地址:https://www.nature.com/articles/s41586-019-1724-z (开放阅读版 https://storage.googleapis.com/deepmind-media/research/alphastar/AlphaStar_unformatted.pdf)
详细介绍:https://www.leiPhone.com/news/201901/aDDh5MOlOsU22WvK.html
Learning the Depths of Moving People by Watching Frozen People ( CVPR 2019 )

通过观察静止的人学习预测移动的人的深度
作者:谷歌 AI 研究院 Zhengqi Li, Tali Dekel, Forrester Cole, Richard Tucker, Noah Snavely, Ce Liu, William T. Freeman
推荐理由:这篇论文要解决的任务“从单个摄像头估计运动物体的深度”乍看上去是无法完成的。这篇论文用了很巧妙的方法,一方面,作者们把 YouTube 上用户们自己上传的“时间静止”视频作为数据集,它们提供了海量的、天然的、带有人物的三维空间回放,经过传统方法还原之后就可以作为标注数据,免去了采集之苦。这实际上提醒我们,除了用传统众包方法专门收集数据集之外,网络上还有许多公开数据经过处理以后也可以成为很有价值的训练数据集。

另一方面,在用深度模型学习空间常识、学习预测深度的同时,作者们还增加了额外的结构让网络能够提取临近的帧之间的变化信息,提高了网络处理运动物体的能力。最终效果是,只需要单个摄像头视角的输入,模型就可以输出稳定、高准确率的三维深度预测,对于运动的物体也有很好效果。这篇论文也获得了 CVPR 2019 最佳论文荣誉提名奖。
论文地址:https://arxiv.org/abs/1904.11111
详细介绍:https://www.leiphone.com/news/201905/comu6TnFl5ejaAG1.html
代码开源:https://github.com/google/mannequinchallenge
The Lottery Ticket Hypothesis:Finding Sparse, Trainable Neural Networks ( ICLR 2019 )
彩票假说:找到稀疏、可训练的神经网络
作者:MIT 计算机科学与人工智能实验室 Jonathan Frankle, Michael Carbin
推荐理由:作为缩小网络体积、降低运算资源需求的技术路线,网络稀疏化和知识蒸馏一起得到了越来越多的关注。目前最常用的稀疏化方法是先训练一个大网络然后剪枝,稀疏的网络也可以得到和稠密网络差不多的性能。
既然稀疏的网络可以有和稠密网络差不多的性能,这篇论文里作者们就提出一个大胆的假设,看作是想要的稀疏网络本来就在稠密网络里,我们只需要把它找出来就可以 —— 更具体地,如果从随机初始化的网络随机做 n 次迭代可以得到训练好的稠密网络,从随机初始化的网络里做类似数目的迭代也可以找到表现差不多的稀疏网络。只不过,找到那个稀疏网络非常依赖好的初始值,而想在随机出好的初始值简直就像抽彩票。这就是论文核心的“彩票假说”。
作者们设计了算法确认“是否抽到了好的号码”,也用一系列实验验证了假说、展示了好的初始值的重要性。甚至,从好的初始值出发得到的稀疏网络可以得到比稠密网络更好的表现。这篇论文获得了 ICLR 2019 的最佳论文奖。
大胆的“彩票假说”立刻引发了激烈讨论。作者们做了后续研究发表了 Stabilizing the Lottery Ticket Hypothesis(arxiv.org/abs/1903.01611);Uber AI 实验室发表了一篇论文 Deconstructing Lottery Tickets: Zeros, Signs, and the Supermask(arxiv.org/abs/1905.01067)介绍了他们对这个现象的深入探究结果,揭示了“彩票假说”在碰运气之外的合理性;论文 Sparse Networks from Scratch: Faster Training without Losing Performance(arxiv.org/abs/1907.04840)也紧接着提出“彩票假设”之类的稀疏网络生成方式计算代价太高,他们的新方法可以直接从稀疏的网络结构开始训练,对计算资源需求更少、训练更快,并达到和稠密网络相近的表现;FB 田渊栋组也发表了 One ticket to win them all: generalizing lottery ticket initializations across datasets and optimizers(arxiv.org/abs/1906.02773)并被 NeurIPS 2019 接收。
论文地址:https://arxiv.org/abs/1803.03635
详细介绍:https://www.leiphone.com/news/201905/ZwDWnaSGZHDveLiO.html
代码开源:https://github.com/google-research/lottery-ticket-hypothesis
On the Variance of the Adaptive Learning Rate and Beyond
关于自适应学习率的变化以及更多
作者:UIUC Liyuan Liu、韩家炜,微软研究院 高剑峰 等
推荐理由:这篇来自韩家炜团队的论文研究了深度学习中的变差管理。在神经网络的训练中,Adam、RMSProp 等为了提升效果而加入了自适应动量的优化器都需要一个预热阶段,不然在训练刚刚启动的时候就很容易陷入不好的、可能有问题的局部最优,而这篇论文中提出的 RAdam 能为优化器提供好的初始值。借助一个动态整流器,RAdam 可以根据变差大小来调整 Adam 优化器中的自适应动量,并且可以提供一个高效的自动预热过程;这些都可以针对当前的数据集运行,从而为深度神经网络的训练提供一个扎实的开头。

同一时期还有另一篇研究改进优化过程的论文《LookAhead optimizer: k steps forward, 1 step back》(arxiv.org/abs/1907.08610),它的核心思路是维持两套权重,并在两者之间进行内插,可以说是,它允许更快的那一组权重“向前看”(也就是探索),同时更慢的那一组权重可以留在后面,带来更好的长期稳定性。这种做法带来的效果就是降低了训练过程中的变差,就“减少了超参数调节的工作量”,同时“在许多不同的深度学习任务中都有更快的收敛速度、最小的计算开销”(根据论文作者自己的介绍)。

这两篇论文不仅都对神经网络的优化过程提出了有效改进,而且两者还可以共同使用。这些成果都既增进了我们对神经网络损失空间的理解,还是非常有效的工具。
论文地址:https://arxiv.org/abs/1908.03265
代码开源:https://github.com/LiyuanLucasLiu/RAdam(RAdam),https://github.com/lonePatient/lookahead_pytorch/blob/master/(LookAhead)
详细介绍:RAdam 和 LookAhead 可以合二为一 https://www.leiphone.com/news/201908/SAFF4ESD8CCXaCxM.html
Reasoning-RCNN: Unifying Adaptive Global Reasoning Into Large-Scale Object Detection ( CVPR 2019 )

Reasoning-RCNN: 在大规模目标检测中应用统一的自适应全局推理
作者:华为诺亚方舟实验室,中山大学
推荐理由:随着目标识别的规模越来越大、粒度越来越细,类别不平衡、遮挡、分类模糊性、物体尺度差异性等等问题越来越明显。我们很容易想到,人类视觉识别能力中的一个重要环节是“基于常识的推理”,比如辨认出了 A 物被 B 物遮挡之后,对这两个物体的识别都能更准确。这篇论文就把这种思想融入到了 RCNN 模型中,作者们为模型设计了显式的常识知识,并且用基于类别的知识图把图像中物体的语义知识表示出来。
一方面,在感知模型中加入常识、加入基础的推理能力是构建“视觉智能”的趋势;另一方面,其它研究者虽然在更早的研究里就提出过“从图像的目标识别生成关系图”,但是关系图生成了以后有什么作用呢,这篇论文就展示了,可以用图进一步改善目标识别任务本身的表现。
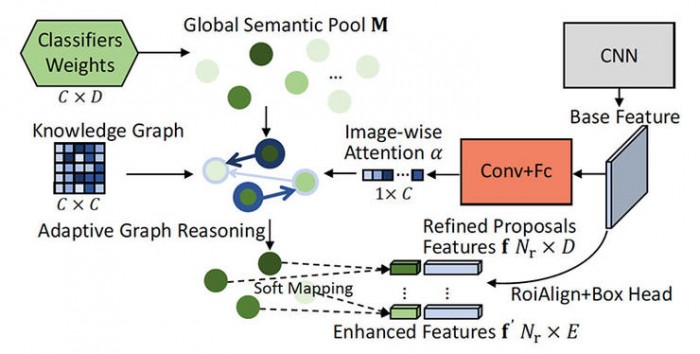
除此之外,作者们还做了许多改进,让模型更适应大规模物体识别、增强阶段之间的联系、优化识别效果。最终,模型的 mAP 在多个数据集上都有大幅提高。作者们的方法比较轻量,可以用在各种目标识别主干网络上,也可以集成各种不同的知识来源。
代码开源:https://github.com/chanyn/Reasoning-RCNN
Social Influence as Intrinsic Motivation for Multi-Agent Deep Reinforcement Learning ( ICML 2019 )

在多智能体强化学习中把社交影响作为固有动机
作者:MIT,DeepMind,普林斯顿大学
推荐理由:随着多智能体强化学习研究越来越多,为智能体设计/让智能体学会行动协调和信息交换成了一个重要课题。这篇论文中作者们的着力点就是在多智能体环境下,让智能体从其他智能体身上学会固有的社交动机。他们的方法是,如果一个智能体能影响其他智能体、让它们在协同和沟通方面都有更好的表现,那就奖励它。更具体地,作者们在论文中展示了,如果一个智能体让其他智能体的行为发生了较大的改变,那奖励它就更有可能鼓励不同的智能体之间有更多的共同信息交换。这样的机制会让智能体形成归纳偏倚,更有意愿学会协同运动,即便这些智能体都是各自独立地训练的。并且影响力的奖励是使用一种分布式的方式来计算的,能够有效解决突发通信的问题。这篇论文获得了 ICML 2019 最佳论文荣誉提名。
同期还有另一篇来自 Facebook AI 研究院的论文 Learning Existing Social Conventions via Observationally Augmented Self-Play (arxiv.org/abs/1806.10071)从另一个角度设计了协调机制:在加入一个团体之前,新的智能体要通过观察和重放机制学习这个团地当前的行为模式(人类角度的“风俗习惯”),让自己能够融入,避免加入团体之后它的策略无法得到奖励(即便在无合作的竞争性环境下可以得到奖励)。不过大概还是前一篇学会固有社交动机更高明一点?相比之下它可是明明白白地促进了智能体都变得更协调、更主动沟通啊(笑)。
论文地址:https://arxiv.org/abs/1810.08647
Weight Agnostic Neural Networks
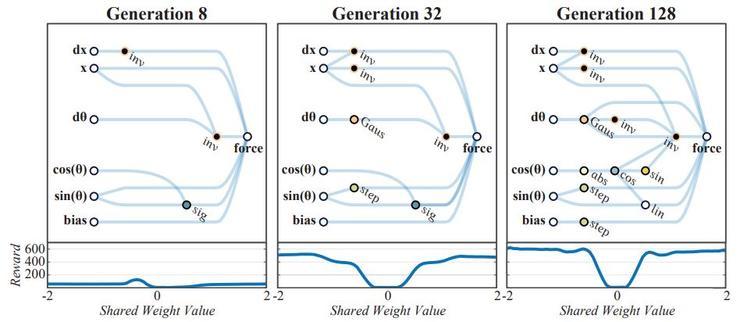
权重无关的神经网络
作者:谷歌 AI Adam Gaier 和 David Ha
推荐理由:现代的神经网络研究都有一个固定的模式,固定网络架构,通过优化寻找好的连接权重(训练)。这种惯例也引发了一些讨论,“如果我们把网络结构看作先验,把连接权重看作学到的知识”,那么我们能在多大程度上把知识以结构(先验)的形式集成在模型中呢?以及这样做是好还是坏呢?
这篇论文就是一次直接的探索,网络的训练过程不是为了寻找权重,而是在相对固定且随机的权重下寻找更好的网络结构。对于集成了好的先验的网络结构,即便网络中所有的权重都统一且随机的也能有好的表现;在此基础上如果能允许分别优化不同的权重,网络的表现就可以更上一层楼。这种方式找到的先验知识也会以网络结构的形式直接体现出来,有更好的可解释性。
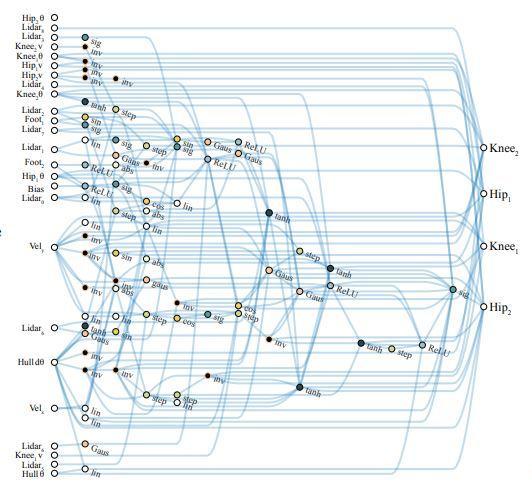
如果说“固定网络结构,寻找权重”和“固定权重、寻找网络结构”分别就像“气宗”与“剑宗”,那么现在双方终于都登场了,我们可以期待未来有更多的好戏上演。
论文地址:https://arxiv.org/abs/1906.04358
详细介绍:https://www.leiphone.com/news/201906/wMjVvtWT2fr8PcxP.html
代码开源:https://weightagnostic.github.io/
XLNet: Generalized Autoregressive Pretraining for Language Understanding
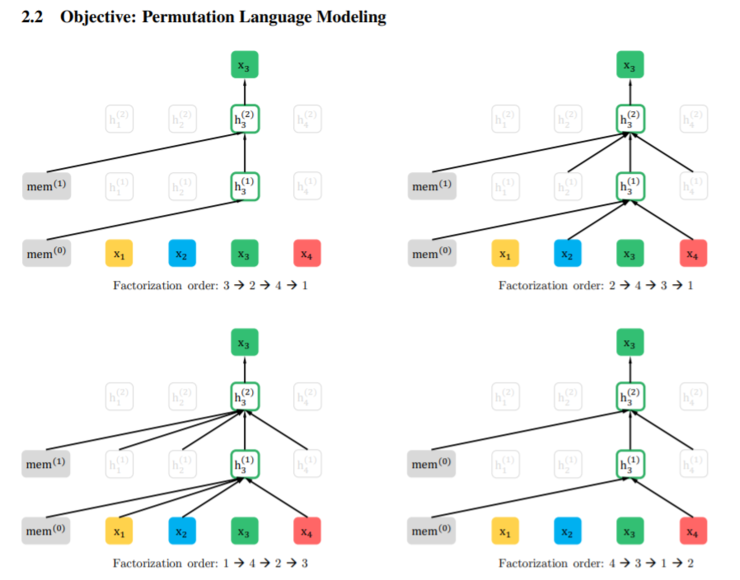
XLNet:用于语言理解的通用自回归预训练
作者:CMU,谷歌 AI
推荐理由:基于 BERT 的改进模型很多,XLNet 是其中非常成功的一个。XLNet 的改进重点在于,1,用基于输入顺序置换的新的掩模方式替代 BERT 的掩模+双向预测(这种机制设计使得 BERT 更像是文本降噪模型,而在生成任务中表现不佳),2,使用了 token 内容和 token 位置分离的双流自注意力机制,3,采用了和改进 2 匹配的新的掩模方式。这些设计让 XLNet 兼具了序列生成能力(类似传统语言模型)和上下文信息参考能力。
再加上选用更大的训练数据集、用更适应长序列的 Transformer-XL 作为主干网络、训练方式对掩模的利用率更高、允许部分预测训练等改进,可以说 XLNet 相对于 BERT 的技术改进是从头到尾的,在作者们测试的所有任务中都取得了比 BERT 更好的表现也是情理之中(虽然有一些任务中提升并不大)。
XLNet 这样的模型出现代表着 NLP 预训练模型越发成熟,适应的下游任务越来越多、表现越来越好;也代表着一个统一的模型架构就有可能解决各种不同的 NLP 任务。
论文地址:https://arxiv.org/abs/1906.08237
代码开源:https://github.com/zihangdai/xlnet
除此之外,以下这 10 篇论文也曾在我们的候选列表里,它们各突出之处,我们列举如下:
-
AI surpasses humans at six-player poker ( Science Magazine)
-
在 6 人德州扑克游戏中胜过人类的扑克 AI(这也是 Science 杂志总结的 2019 年 10 大科学突破第 10 名)
-
ALBERT: A Lite BERT for Self-supervised Learning of Language Representations
-
简化版 BERT,但不是简单的缩小了事,他们用更少的参数获得了更好的表现
-
A Theory of Fermat Paths for Non-Line-of-Sight Shape Reconstruction
-
“非视线内的物体形状重建”,也就是“如何看到墙角后面的东西”是这篇论文的研究课题。虽然这个任务略显冷门,但这篇论文表明计算机视觉技术有潜力让更多看似不可能的事情变得可能。获得了 CVPR 2019 最佳论文
-
Transferable Multi-Domain State Generator for Task-Oriented Dialogue Systems ( ACL 2019 )
-
面向任务的多轮对话系统通常会为不同的任务设计预定义的模版,但不同模版之间的数据共享、数据迁移是一大难点。这篇论文就提出了有效的知识追踪、共享、迁移方法
-
Depth Prediction Without the Sensors: Leveraging Structure for Unsupervised Learning from Monocular Videos
-
基于单视角视频,根据运动物体的移动解算三维空间结构的做法在传统计算机视觉中就有很多研究,这篇论文里把它和深度学习结合以后带来了更好的效果,作者们增加的在线学习能力也让这个方法对不同的数据集、不同的场景有更好的适应性。
-
EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks
-
研究 CNN 模型的缩放和可拓展性,用更小的模型得到更高的准确率,而且为不同规模的计算资源提供了一系列优化过的模型。ICML 2019 Spotlight 论文
-
Emergent Tool Use From Multi-Agent Autocurricula
-
通过隐式的课程学习中,在一个具备互动和竞争机制的环境中,不同的智能体之间可以持续地找到新任务,它们也就可以持续地学会新的策略
-
RoBERTa: A Robustly Optimized BERT Pretraining Approach
-
专门研究 BERT 的预训练过程并提出一种新的改进思路,用新的预训练目标做更充分的训练。也就是说,设计一个大模型容易,但还要想办法确定是否已经训练够了。
-
SinGAN: Learning a Generative Model from a Single Natural Image
-
这篇论文尝试从单张图像学习 GAN,多种不同尺度的 GAN 组成的金字塔结构分别学习图像中不同大小的小块,整个模型的学习效果得以同时兼顾图像中的全局结构和细节纹理。ICCV 2019 最佳论文
-
Towards Artificial General Intelligence with Hybrid Tianjic Chip Architecture
-
清华大学团队设计的天机芯片用融合架构同时支持来自计算机科学的、基于数值的非线性变换的人工神经网络,以及来自神经科学的、基于信号响应的脉冲神经网络。论文发表在 Nature 杂志。